As we know Snowflake has introduced latest badge “Data Cloud Deployment Framework” which helps to understand knowledge in designing, deploying, and managing the Snowflake landscape. Data Architecture discussed in course was in great detail and instead of just going only video and earning Badge, we plan to implement Architecture based on our understanding. Therefore, After going Video, back and forth multiple times I tried to accumulate the different parts in a single architecture slide in simpler way.
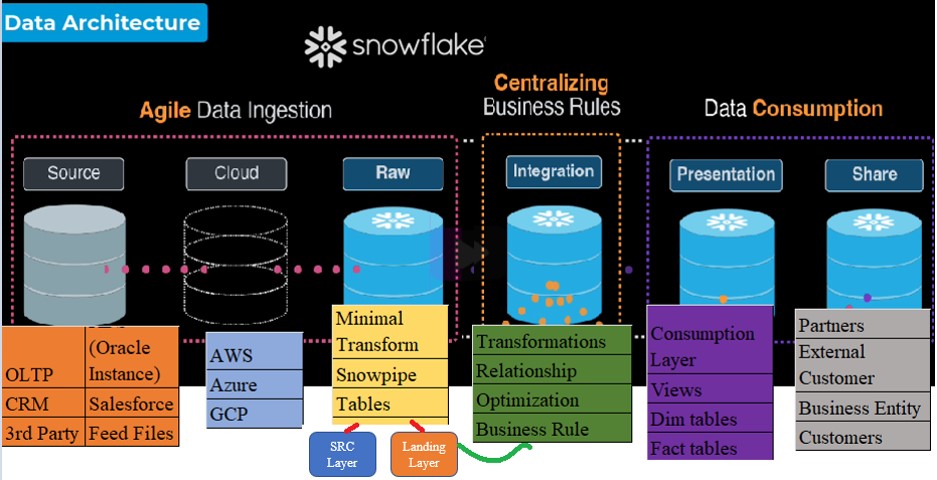
Above all, Architecture was divided into three Business layers:
- Firstly,Agile Data ingestion:
- Heterogeneous Source System fed the data into Cloud.
- Respective Cloud would consume/Store the data in bucket or containers.
- Load the data AS-IS into Snowflake called RAW layer.
- Streams track the changes in the Landing tables and maintain history.
- Snowpipe to automate the ingestion process.
- Secondly, Define Business Rules:
- Develop the transformation on RAW data and include the Business logic.
- Develop the relationship among different sources table to produce meaningful data.
- Try to optimize the logic and filter unwanted columns.
- Thirdly, Data Consumption:
- Develop the Views on Transformed or aggregated tables.
- Finalize the Dimension and Fact tables in this layer.
- Develop the Business Reports dashboard on finalized table or Views.
- Share the Secured Views to External or Internal Customers.
Agile Data ingestion
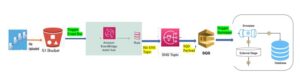
Agile Data ingestion: Source System to RAW Layer:
- Eventually,In RAW layer we have two schemas: SRC schema and Landing Schema:
- However, Below Source system will ingest data into Snowflake and truncate tables on daily basis in SRC layer.
- Oracle RDS instance on AWS: (Customer Table).
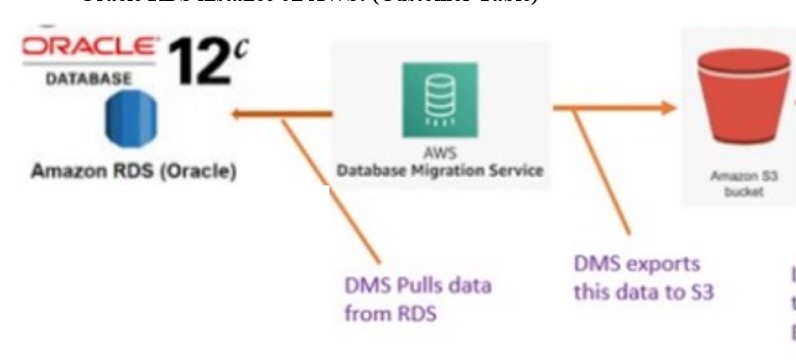
- Assume we have Customer data stored on Oracle RDS instance.
- Subsequently,Create an S3 bucket to hold the Tables data.
- Afterward, Launched Data Migration (DMS) service in AWS, pulls data from RDS instance and place file in S3 bucket.
- As a result, load data into snowflake:
- Lambda function to trigger Glue job and Glue job to load data into Snowflake.
https://cloudyard.in/2022/02/data-migration-oracle-aws-rds-to-snowflake-via-dms/
https://cloudyard.in/2021/12/aws-glue-connect-with-snowflake/
- Also, Create the S3 integration, Create Stage and File Format and Configure Snowpipe, to load data into Snowflake.
https://cloudyard.in/2022/12/snowflake-and-s3-data-lake/
(Refer : DMS to Snowflake section in Blog)
- Amazon AppFlow: Salesforce to Snowflake. (Order Table)

- At First, Use Amazon AppFlow to securely transfer data between Software-as-a-Service (SaaS) applications and Cloud Data warehouse.
- Also, Ensure target table is available in RAW layer in Snowflake.
- In addition,Create the FLOW with Salesforce as Source and Snowflake as Target and defined mapping.
https://cloudyard.in/2022/01/aws-amazon-appflow-salesforce-to-snowflake-integration/
- Customer or 3rd Party place file on Cloud: (Product Table)
- Firstly, Customer placed, multiple feeds files where Format is varying according to the Source system in a bucket.
- Afterward, use PATTERN with REGEX in COPY command to fetch only relevant feed files.
https://cloudyard.in/2022/02/snowflake-pattern-with-regex-in-copy-command/
- Create Storage Integration, File Format, Create table and stages.
- Finally, Configure the Snowpipe on Consolidated bucket, which in turn will load data into multiple tables.
https://cloudyard.in/2022/06/snowpipe-load-multiple-tables-with-same-bucket/
Layers
Raw Layer:
- Business confirms the timings when Feed file would be arrived in Bucket.
- Therefore, Create Task to schedule at specified time after getting discussion with Business.
- Finally,Truncate tables (Customer, Order and Product) in Source Layer and load latest data.
Landing Layer:
- Track the changes on table i.e., any Insert/Update on Delta data present in Landing Layer.
- Create the STREAMS on all Tables in Landing Layer.
- You can create APPEND ONLY or full DML stream base on business requirement.
- Create the TASK, depends on RAW Layer task and data will be overwritten into the Landing Layer tables from the Raw layer.
merge into <<Landing Layer Table>> LL
using(select * from RAW Layer Table) RL
on LL.COLUMNS = RL.COLUMNS
when matched and LL.COLUMNS = RL.COLUMNS
then
update LL TABL
when not matched then
Insert INTO LL TABLE
4. Eventually,Streams will capture the changed records.
Centralized Business Rules:
Centralized Business Rules:
- Firstly, Create the STREAMS on all Tables in Business Layer.
- Create the TASK in Business Layer which checks if the STREAMS created in landing layer has data or not.
- This implies that if the source team has fed the data into RAW layer.
- TASK in RAW layer triggers and updates the changes in Landing table system$stream_has_data(‘Landing Layer.Landing_Layer_Stream’)
- Refer the METADATA$ACTION& METADATA$ISUPDATE columns in the stream to check if record is a New or Updated.
- Leverage the MERGE command to get the latest data in the Business layer.
- Also perform any transformation like: Status =’A’ then ‘Active’ or Country = ‘In’ then India,
Order amount null then 0 etc. - Identify the record versioning using ENDDATE and FLAG.Records where ENDDATE is null and FLAG <> ‘N’ are latest records.
- Streams in Business layer captures the final Data after required transformations.
- These records should be eligible for presentation layer.
merge into <<Business Layer Table>> BL
using(select * from Landing_Layer_Stream) LS
on BL.COLUMNS = LS.Columns
when matched and (LS.METADATA$ACTION='DELETE') THEN
update set ENDDATE = sysdate , FLAG = 'N'
when not matched and (LS.METADATA$ACTION='INSERT') THEN
insert BL.TABLE FROM LS.COLUMNS
Data Consumption:
- Create the TASK in Consumption Layer which checks if the STREAMS created in Business layer has data or not.
- Refer the METADATA$ACTION& METADATA$ISUPDATE columns in the stream to check if record is a New or Updated.
- Leverage the MERGE command to get the latest data in the Presentation layer.
- Therefore, Develop a secure view based on the business requirement by creating join among these tables .At this stage we can hide the unwanted or PII columns to be expose.
- Also filter out the records in secure view based on the customer Business type.
- Also develop the Row Masking or Column masking to protect the Sensitive data.
- Create the Role hierarchy in Account.