During this post we will discuss how AWS S3 service and Snowflake integration can be used as Data Lake in current organizations. How customer has migrated On Premises EDW to Snowflake to leverage snowflake Data Lake capabilities.
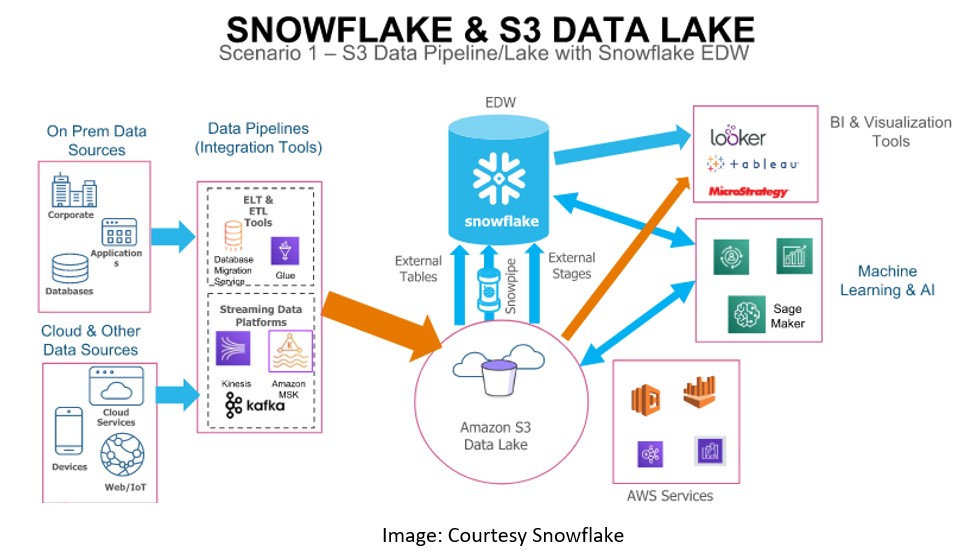
Moreover, We will use the below architecture to showcase the Demo where convert the existing Data Lake to Snowflake Deployment.
As per the below sheet we will try to implement a new EDW process which will use Snowflake as their Target Database.

AWS Implementation:
AWS Implementation:
To be ProcessStep1: To implement On Prem Data Source:
Use DMS (Data Migration Service): To move Table data from RDS to Snowflake.
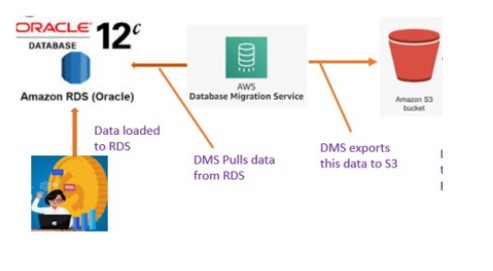
- For this Demo we launched RDS service for ORACLE in AWS and created some tables.
- Populate the table using sqlworkbench editor.
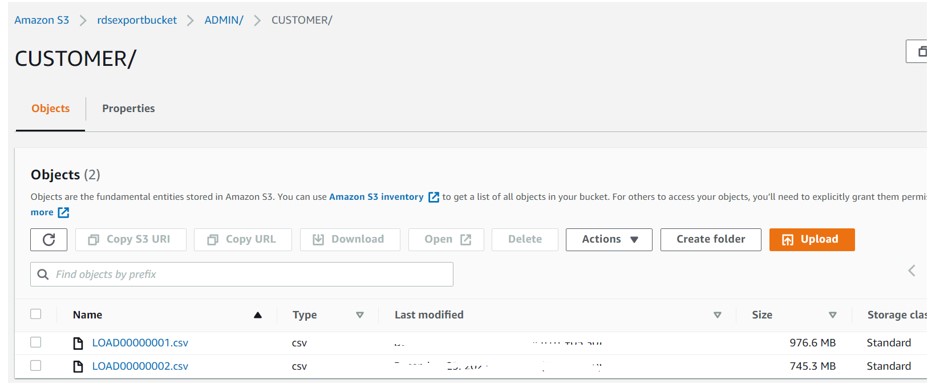
- Create S3 bucket to hold the tables data.
- Launched Data Migration (DMS) service in AWS.
Step2: To implement Cloud Data Source::
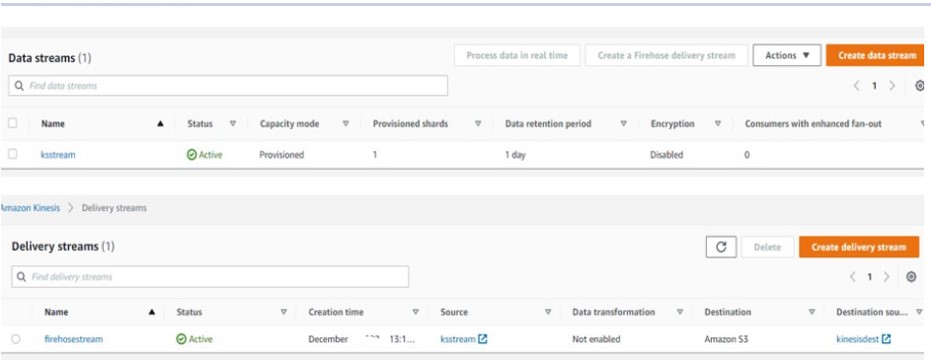
A Kinesis data stream is basically a publish/subscribe system used to collect and process large streams of data records in real time. Kinesis Data Streams and Firehose are designed to work well together, so when you create a Firehose, you can tell it to use an already created Data Stream as input.
The following actions has been performed to get data from Kinesis to S3.
- Firstly, Create Lambda function: kinesislambda, to read JSON file from S3 bucket and trigger the Kinesis data stream
- Secondly, Create Kinesis Stream: ksstream, Stream to capture the JSON file
- Thirdly, Create Kinesis Firehose: firehosestream, Receive input from Kinesis stream and store output to kinesisdest bucket
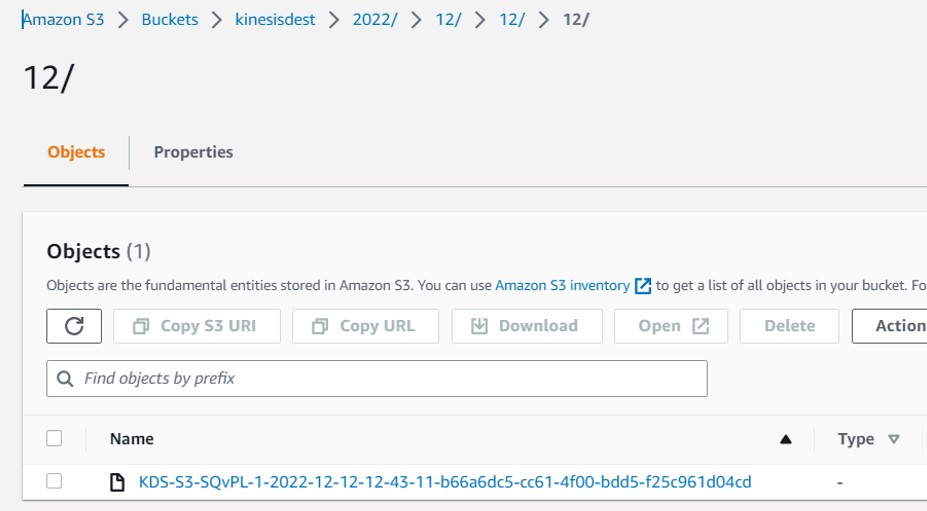
- Finally, Create Firehose Destination Bucket : kinesisdest ,Bucket to store the file by Firehose.
Step3: Through ADF ETL process, connect with Source system and ingest this data on S3 Bucket. This data would not be used much frequently so we will be creating External Tables in Snowflake.
Step4 : Hence we have three S3 Buckets to store files in Pipeline
- rdsexportbucket: Bucket to hold data generated from DMS service.
- Kinesisdest:Bucket to hold Streaming data i.e. JSON file
- Externalbucketstream:Bucket to hold In frequent access data.
Snowflake Implementation:
Snowflake Implementation:
DMS to Snowflake:
- Firstly, Create the S3 integration pointing to all 3 S3 buckets used in our Data lake.
create or replace storage integration s3_int
type = external_stage
storage_provider = s3
enabled = true
storage_aws_role_arn = 'arn:aws:iam::913267004595:role/testsnowflake'
storage_allowed_locations = ('s3://rdsexportbucket/ADMIN/',s3://externalbucketstream/color/’,‘s3://kinesisdest/2022/’);
- Secondly, Create Stage and File Format
create or replace file format demo_db.public.csv_format
type = csv
skip_header = 1
null_if = ('NULL', 'null')
empty_field_as_null = true;
create or replace stage demo_db.public.rds_csv_stage
URL = 's3://rdsexportbucket/ADMIN/'
STORAGE_INTEGRATION = s3_int
file_format = demo_db.public.csv_format;
- Finally, Create Table and Snowpipe
create table RDS_CUSTOMER (CUSTOMER_ID integer,NAME varchar2(100),INVOICE varchar2(100),
STATUS VARCHAR2(10),AMOUNT INTEGER);
create or replace pipe demo_db.public.rds_snowflake auto_ingest=true as
copy into RDS_CUSTOMER
from @demo_db.public.rds_csv_stage/CUSTOMER/
on_error = CONTINUE;
Kinesis to Snowflake:
- Create File Format and Stage
create or replace file format demo_db.public.json_format
type = 'json',
STRIP_OUTER_ARRAY = TRUE;
create or replace stage demo_db.public.ext_json_stage
URL = 's3://kinesisdest/2022/
STORAGE_INTEGRATION = s3_int
file_format = demo_db.public.json_format;
- Create table with VARIANT column
CREATE OR REPLACE TABLE DEMO_DB.PUBLIC.JSON_TABLE (JSON_DATA VARIANT );
- Load Data into Table:
COPY INTO DEMO_DB.PUBLIC.JSON_TABLE FROM @DEMO_DB.public.ext_json_stage;
- Parse JSON data in rows and Column
SELECT
JSON_DATA
,JSON_DATA:Category::string,
Regions.value:Region::string,
"Sub-Categories".value:"Sub-Category"::String,
EmployeeSales.value:Employee::string,
EmployeeSales.value:Sales::string,
EmployeeSales.value:Comment::string
FROM JSON_TABLE
,LATERAL FLATTEN (JSON_DATA:Regions) as Regions
,LATERAL FLATTEN (Regions.value:"Sub-Categories") as "Sub-Categories"
,LATERAL FLATTEN ("Sub-Categories".value:EmployeeSales) as EmployeeSales;
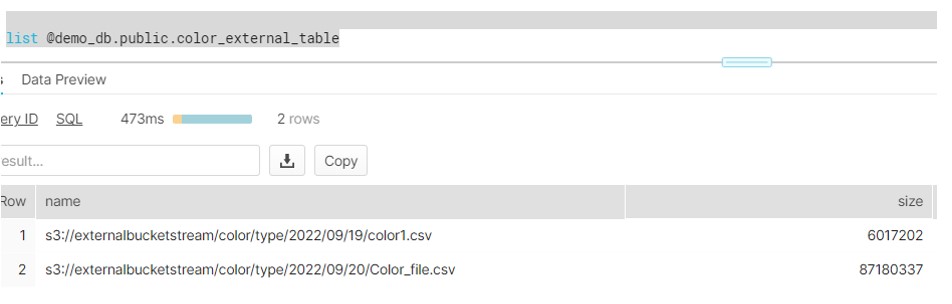
External Table in Snowflake:
- Create the stage pointing to S3 location
create or replace stage demo_db.public.color_external_table
URL = 's3://externalbucketstream/color/'
STORAGE_INTEGRATION = s3_int
file_format = demo_db.public.csv_format;
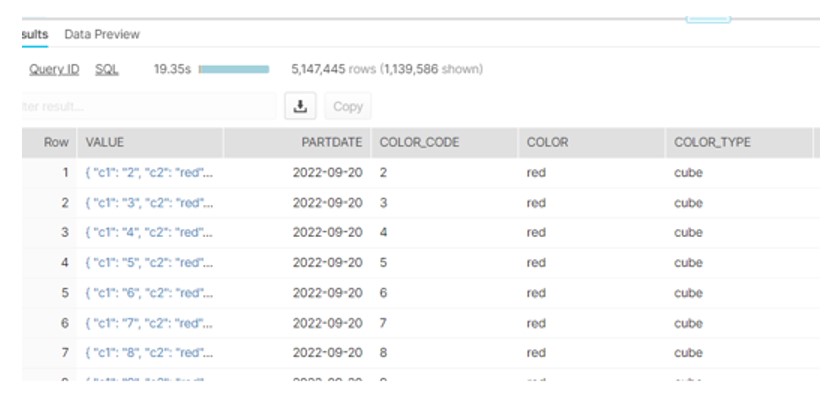
- Create External table and partition on YYYY-MM-DD
create or replace external table colors (
partdate date as to_date(split_part(metadata$filename, '/', 3) || '-' ||
split_part(metadata$filename, '/', 4) || '-' ||
split_part(metadata$filename, '/', 5),'YYYY-MM-DD'),
Color_Code varchar(10) as (value:c1::varchar),
Color varchar(20) as ( value:c2::varchar),
color_Type varchar(10) as (value:c3::varchar))
partition by (partdate)
location = @demo_db.public.color_external_table
auto_refresh = true
file_format = csv_format;