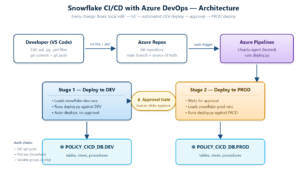
Snowflake CI/CD with Azure DevOps
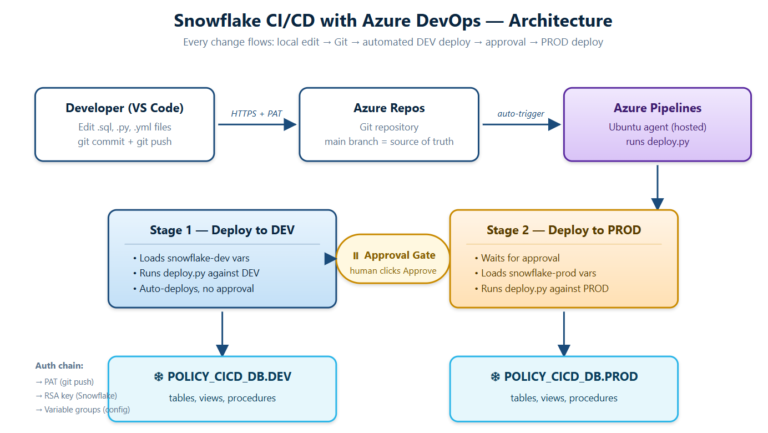
Why This Blog Snowflake CI/CD with Azure DevOps: Deploying Snowflake objects by hand i.e pasting DDL into Snowsight, running it in DEV, running it again in PROD works until it doesn’t. It’s manual, un-audited, and error-prone. The moment two team members touch the same object, or PROD drifts silently from […]
Read More