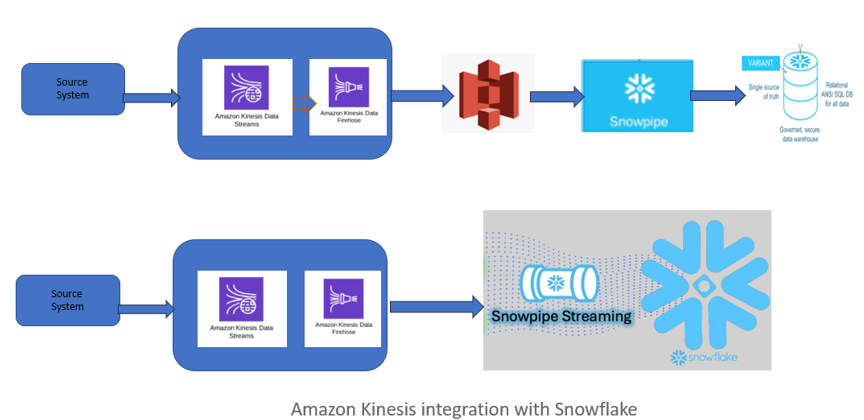
Previously, data engineers used Kinesis Firehose to transfer data into blob storage (S3) and then load it into Snowflake using either Snowpipe or batch processing. This introduced latency in the data pipeline for near real-time data processing. Now, Amazon Kinesis Data Firehose (Firehose) offers direct integration with Snowflake Snowpipe Streaming, eliminating the need to store data in an S3 bucket. With just a few clicks, users can set up a Firehose stream to deliver data directly to Snowflake. Through its integration with Snowpipe Streaming, Firehose sends records as soon as they are available, making data query-ready in Snowflake within seconds.
During this post, we will discuss how this integration transforms data ingestion workflows. We will explore practical use cases and a step-by-step guide to setting up your own Kinesis Firehose to Snowflake pipeline. By the end of this post, you’ll have a comprehensive understanding of how to leverage this powerful integration to enhance your data architecture.
Technical:
Let’s delve into the process of setting up a pipeline using Kinesis:
Step1: Generate public and private key file requires in Kinesis setup.
openssl genrsa 2048 | openssl pkcs8 -topk8 -inform PEM -out rsa_key.p8
openssl rsa -in rsa_key.p8 -pubout -out rsa_key.pub

Step 2: Create table in Snowflake.
CREATE OR REPLACE TABLE DEMO_DB.PUBLIC.sales_data ( json_data VARIANT );
Step 3: Generate the fingerprint (a SHA-256 hash) of the public key for the user. This is done by using:
Copy the Key from rsa_key file (Make sure all in one line there should not be any line break)
Alter user sachinsnowpro set rsa_public_key='';
Step4: Configure Kinesis and ADF delivery stream for data streaming.
- AWS Console->Kinesis->Create Data stream.

2.Once Data Stream gets created Create a Firehose Stream.




Till this point, the Kinesis and Firehose setup is done. Next, we have to invoke this data stream in automate way rather than manual intervention.
Step5: Configure the Lambda in AWS.
To automatically invoke the Stream, we will utilize an AWS Lambda function. Here’s the logic we aim to implement:
When a file uploads to the S3 Bucket, the Lambda function will trigger.
- The Lambda function will call the Kinesis stream.
- The Stream will execute the following tasks:
- a) Read the source file from the S3 bucket.
- b) Connect to Snowflake as the destination.
- c) Load the data directly into Snowflake.

Step6: Attach function to S3 Bucket:

Step7: Upload file to the Bucket and this would trigger Lambda function which in turn will call kinesis data stream.

Step 8: Verify Data in snowflake:

Incorporating this setup into your data architecture not only streamlines operations but also enhances performance, scalability, and cost-efficiency. The ease of configuration and the powerful capabilities of Snowpipe Streaming make it an invaluable tool for data engineers looking to optimize their workflows.












