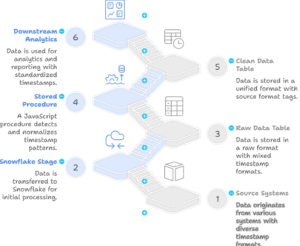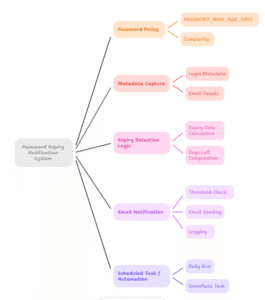
In modern data-driven environments, it’s common to receive daily data feeds from various sources. These files need to be ingested into a data warehouse like Snowflake for further processing and analysis. Automating this process ensures data is consistently and reliably loaded without manual intervention.
Suppose you are a data engineer at a company that receives daily sales data from an external vendor. Each day, a new feeds file is placed in a cloud storage stage in Snowflake, organized by year, month, and day (e.g., @daily_csv_stage/2024/06/16/). Your task is to create a stored procedure that automatically checks for a file in the current day’s folder and loads it into a Snowflake table named prod_tbl.
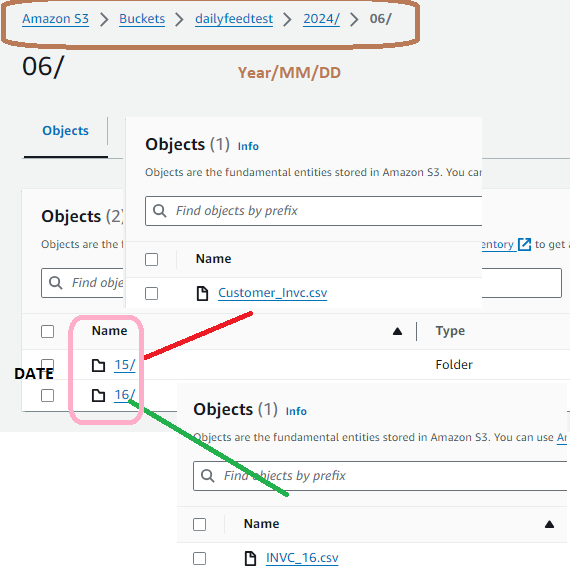
We have the following staging structure in our AWS account.
The following Snowflake stored procedure automates the process of checking for and loading the daily CSV file:

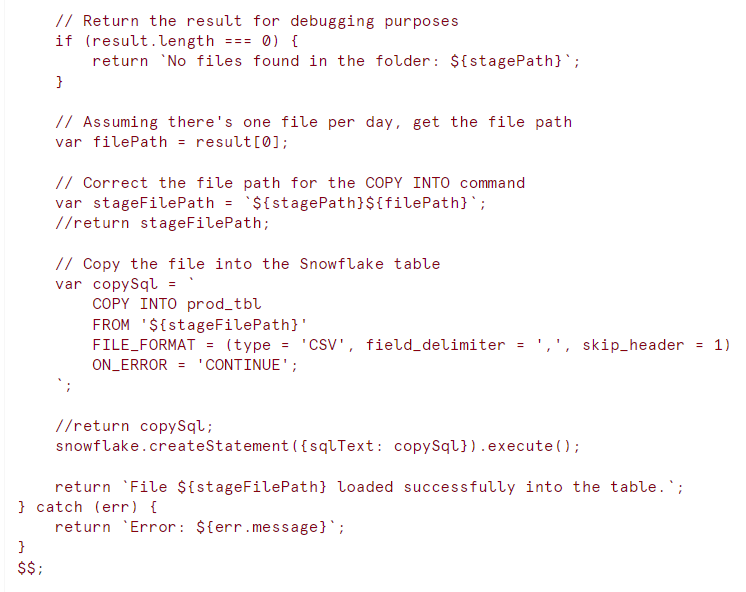
Use Case Example
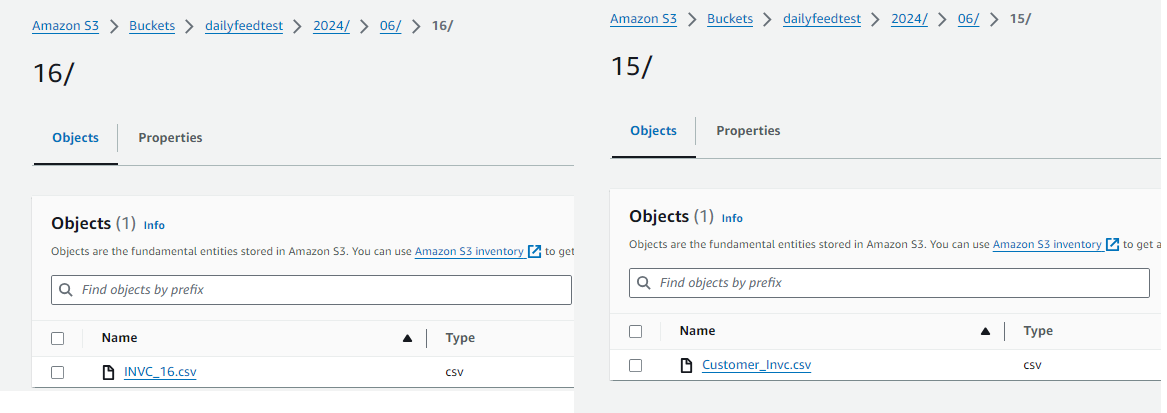
Imagine today is June 15, 2024, and the file Customer_Invc.csv has been placed in the folder @daily_csv_stage/2024/06/15/. When the procedure runs, it will:
- Check for the existence of files in the folder @daily_csv_stage/2024/06/15/.
- If a file is found, it will construct the correct file path.
- Execute the COPY INTO command to load the data from the CSV file into the prod_tbl table.
- Return a success message indicating the file has been loaded.
Similarly it will work for 16th June as well. See we have file with INVC_16.csv in /2024/06/16 folder so today it will pick this file and load into the prod table.
By incrementing the date dynamically, the same procedure can be tested for future dates without hardcoding the date value. This ensures your ETL (Extract, Transform, Load) process remains automated and efficient.