Read Time:2 Minute, 20 Second
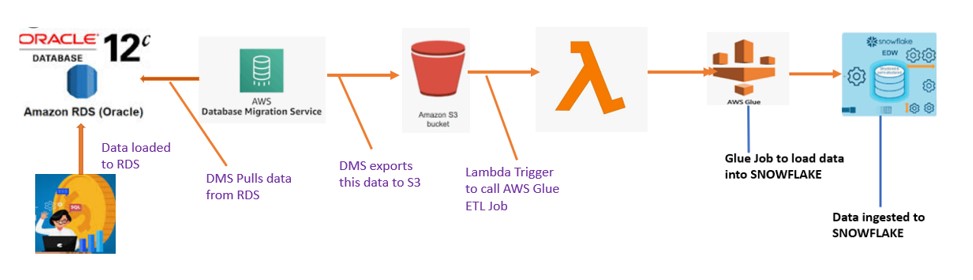
Recently me and my colleague Mehani got a chance to work on one of the Data migration scenarios. As part of this module, we are supposed to move data present in Oracle AWS RDS to Snowflake. In RDS, we have ORACLE database setup with couple of tables present in it. In order to move the Table data from RDS to Snowflake we used Data Migration Service(DMS) service and implemented the following Data pipeline.
High level steps included to perform this migration:
- For this Demo we have launched RDS service for ORACLE in AWS and created some tables.
- Populate the table using sqlworkbench editor.
- Create S3 bucket to hold the Tables data.
- Launched Data Migration (DMS) service in AWS.
- Lambda function to trigger Glue job.
- Glue job to load data into Snowflake.
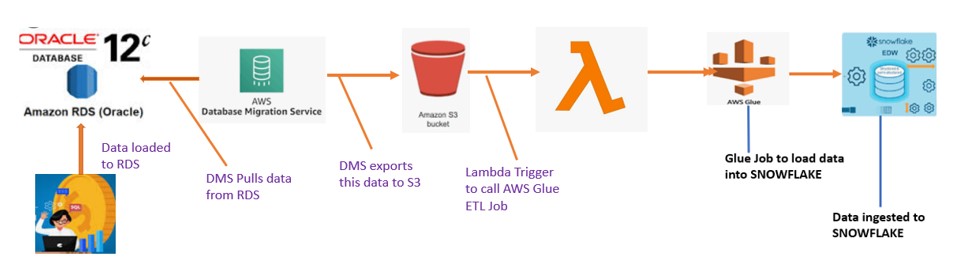
Data Migration steps
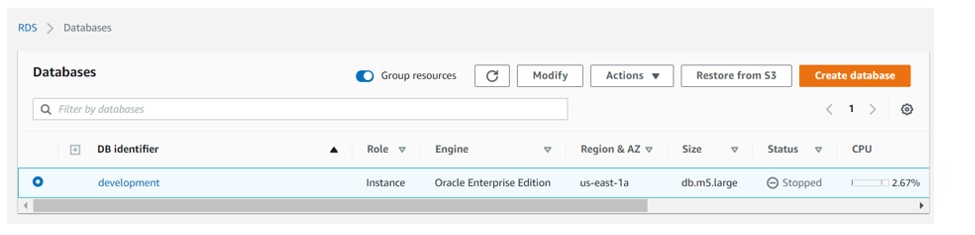
- Launching the RDS service for ORACLE database in AWS organization.
- Download and install the workbench where we can connect to oracle and execute some queries.
- Create some tables inside the Database and insert the data into tables.
- insert into CUSTOMERselect level, ‘Raj’, LEVEL ,’Active’,10000 from dualconnect by level <= 5000000;
- Create S3 bucket to hold the RDS table data.
- Question: How we should migrate this data from RDS to S3. Here we would be leveraging the AWS DMS (Data migration service) to export the records in Bucket
- Steps to be required to successful run DMS.
- Create an IAM role having full access to Bucket.
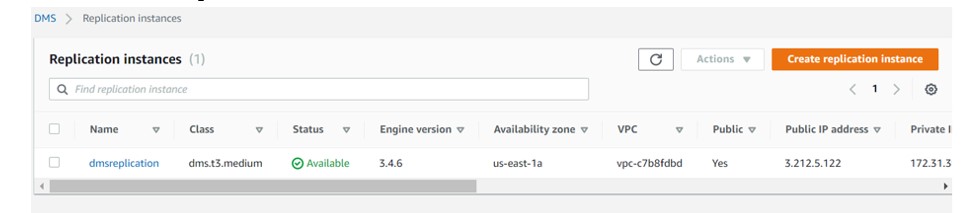
- Create Replication Instance.
-
- Create Source End Points
- On the similar lines, Create Target End Points.
- Create Database Migration task.
- Select the replication instance, source endpoint, target endpoint and migration type as migrate existing data. Set target table mode as drop tables on target and leave other options as default
- Start the data migration task , once the replication is started it will replicate all data to s3 bucket created
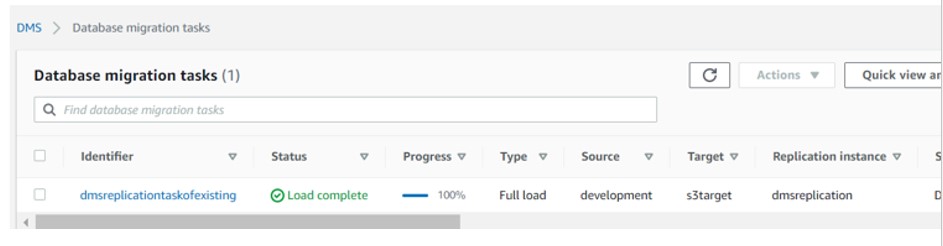
- Checkout the s3 bucket where we can get the output as a database folder wise and tables in csv format
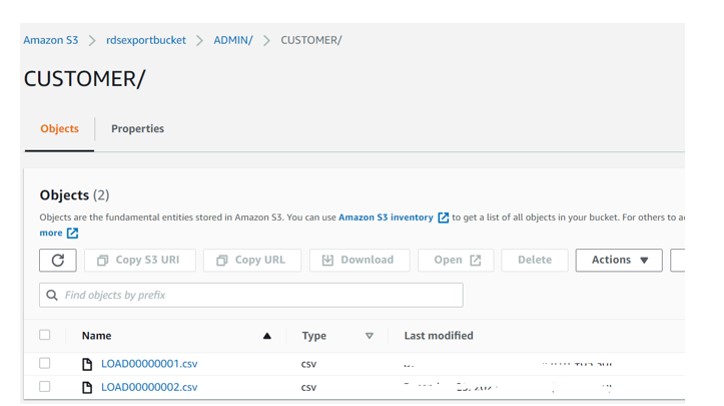
- Develop a Lambda function which will trigger once file uploaded to the bucket and call the Glue Job.
import json
import boto3
def lambda_handler(event, context):
s3_client = boto3.client("glue");
s3_client.start_job_run(JobName="AWStoSF ")
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
- Develop a Glue job which will be invoked by lambda.
- Glue Job: AWStoSF
- Inorder to connect Glue with Snowflake ,follow the below post:
- https://cloudyard.in/2021/12/aws-glue-connect-with-snowflake/
Happy
0 %
Sad
0 %
Excited
0 %
Sleepy
0 %
Angry
0 %
Surprise
0 %







