Even though Snowflake a crucial part of the cloud data warehouses landscape, they are still misunderstood in important ways. During this post we will talk about some of the CDW common mistakes people does while using the Snowflake and it is the high time for the companies that they should recognize the following myths about cloud
data warehouses (CDW).
1. Keep your warehouse running: Auto suspend not configured properly….
Consider you have Large warehouse (around 8-nodes, ~$50/hour) with auto-suspend 15 mins. You are running a query which takes 5 mins to complete and running it per hour.
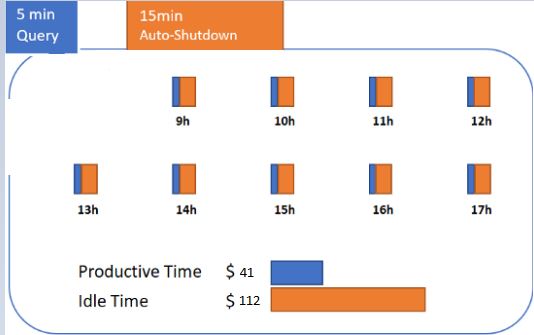
Here we are paying more for non-productive work than productive work.
Possible workaround:
- Adjust your auto-suspend time according to your usage pattern.
- Change the auto-suspend to 2-3 minute, looking to the logs.
- Educate your users to, when using expensive clusters, suspend the warehouse after their execution.
2. Pay-Per-Availability vs Pay-Per-Use model:
In the pay-per-use model, you do not need to pay for availability. As we know “pay-per-availability” can end up costing more for idle time than for actual use time.
People coming from the DB background like Oracle use the database in a traditional way, for them there is a database which is always available and they used it as per their convenience. Hence this is biggest mistake company does while migrating to the Snowflake. People don’t always understand the consequences of their action.
Not explaining to teams that their usage is directly linked to cost, is a very expensive mistake
Concurrency:
3. Concurrency:
Companies should not assume that an unlimited number of users can be on the Cloud Data warehouse without encountering any issues. If more than eight users need to access Snowflake concurrently, it will either queue up those additional users until a concurrency slot become available, or it will spin up a new compute warehouse to facilitate those additional users. This autoscaling in Snowflake can drive up costs rapidly.
4. Use ACCOUNTADMIN for every operation:
ACCOUNTADMIN is an extremely powerful role and should only be used for the initial setup of Snowflake. Being Top most in the hierarchy, this role should not be granted to number of people. Limits the number of users who can use this account to just 2 or 3 people.
5. Single Warehouse for all workloads:
Using a single warehouse for all workloads can create concurrency and contention issues. Best practice is to separate workloads by the type of workload rather than user group. This means running business intelligence queries from marketing users on one warehouse, while running a separate virtual warehouse to support ultra-fast finance dashboard queries on another.
Roles
6.No Consistent RBAC followed: Logically separate the Roles into Domain, Functional and Access roles.
Access Role: These roles will be the lowest level which will have actual access privileges on DB objects.
Functional Roles: These are roles that map to business functions within the organization, such as those for HR Specialists or Financial Analysts or Managers. Naturally, such roles are typically assigned to users based on their job functions.
Domain Roles: multiple independent domains under the same account, this will help to realize that. E.g. when there needs to be a separation of production or UAT/development domains.
This approach promotes re-use of roles and hence reducing the number of roles to administer
7.Complete Support for Hybrid Operation :
Many companies assume their Cloud Data warehouse will support hybrid operation and deployment. Snowflake, do not have options to deploy on-premise. They don’t support federated queries. And for companies that want or need to continue to integrate legacy infrastructure, this poses a huge problem and can lead to substantial cost overruns.
Above mentioned were some of the CDW common mistakes. Please feel free to add based on your experience.