During the last two post , Glue Masking and Glue-Snowflake integration, we discussed how AWS Glue has been used to mask the data. Also, we talked about ingesting data into Snowflake using AWS Glue/Spark framework. Now me and my colleague Mehani Hakim has developed an Automated pipeline to integrate both AWS Glue jobs via AWS Lambda.
Once the feed file gets upload to the source bucket ,Data pipeline gets trigger automatically. This will mask the PII Data and load the updated information in Snowflake without any manual intervention.
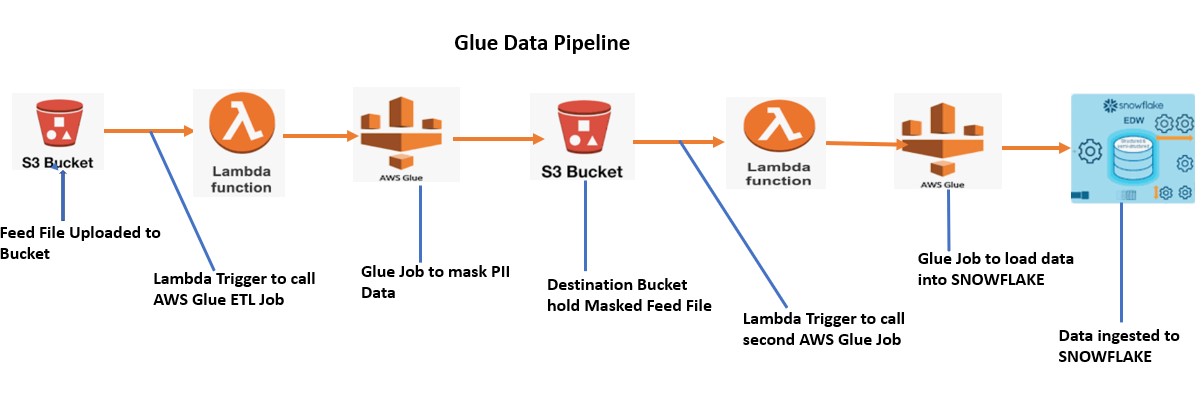
Following pipeline has been implemented in our AWS account.
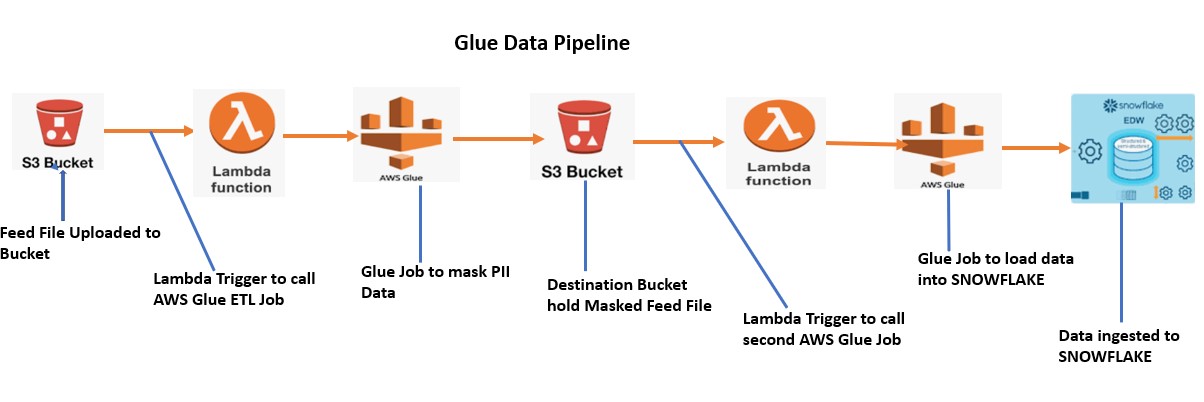
Steps performed in the Pipeline:
- Firstly, Customer Feed file uploaded to the Source bucket.
- Once the File uploaded, Lambda gets trigger and call the AWS Glue Job.
- AWS Glue job runs and mask the PII data and generate the new Feed File with name Invoice_mask.csv
- Glue Job place this new file to the destination bucket.
- As soon as the file upload to the bucket, another Lambda gets trigger and call the second Glue Job
- AWS Glue job reads the feed file from the bucket and integrate with Snowflake Data warehouse.
- Glue Job ingest the data into snowflake.
Following Component are use in this pipeline:
- Source bucket: gluemaskingsrcfeed
- Lambda function: Gluelambda
import json
import boto3
def lambda_handler(event, context):
s3_client = boto3.client("glue");
s3_client.start_job_run(JobName="Data_Masking_PII")
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
- Glue Job: Data_Masking_PII
- Destination Bucket: gluemaskingdestfeed
- Lambda function: gluesfload
import json
import boto3
def lambda_handler(event, context):
s3_client = boto3.client("glue");
s3_client.start_job_run(JobName="AWStoSF")
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
- Glue Job: AWStoSF







