
Recently me and my colleague Mehani, got a chance to work on the Data Masking Requirement. As per the scenario w are getting customer demographic feed file into S3 Bucket. File contains some sensitive information which should not be routed to the downstream system. Client want the PII data inside the file should be masked and protects it from unauthorized access.
We can leverage Snowflake data masking feature; allows you assign role-based access control (RBAC) dynamically. We can define the masking policies at the column level which restrict access to data in the column of a table. Authorized roles view the column values as original, while other roles see masked values. But Client want the PII data should be mask at S3 Bucket itself and they do not want this information to be routed at Snowflake level. Once the Data is mask at S3 bucket , we will consume this updated file in Snowflake with no masking.
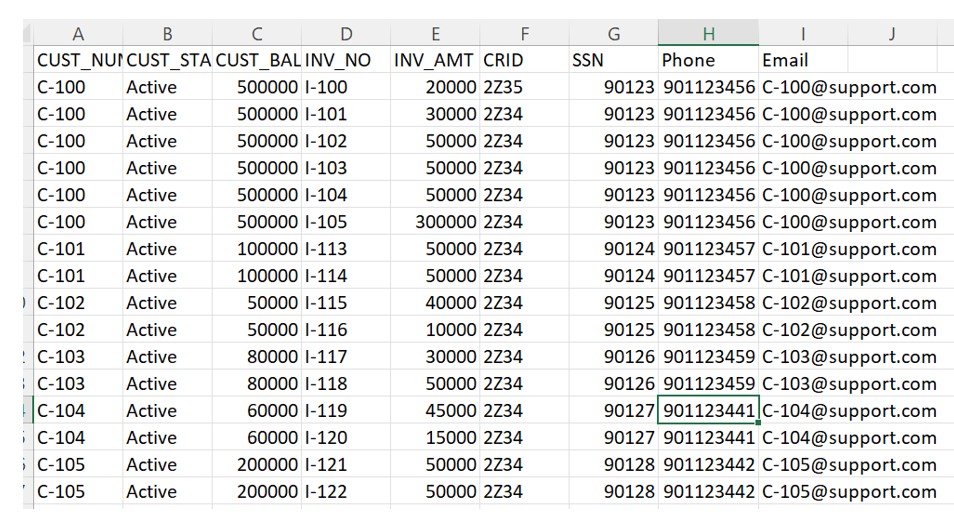
We have used AWS Glue service to mask the data inside the file and create a new updated file in S3 bucket.
At very first, we have created a Crawler in AWS Glue.
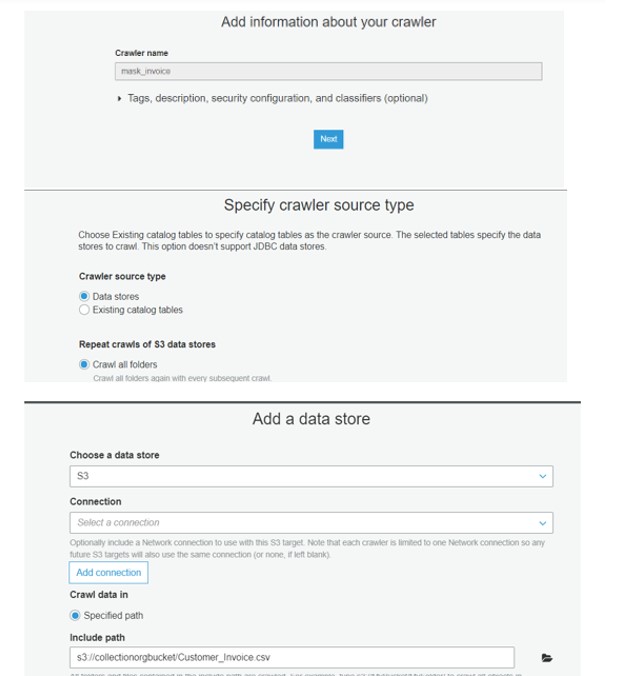
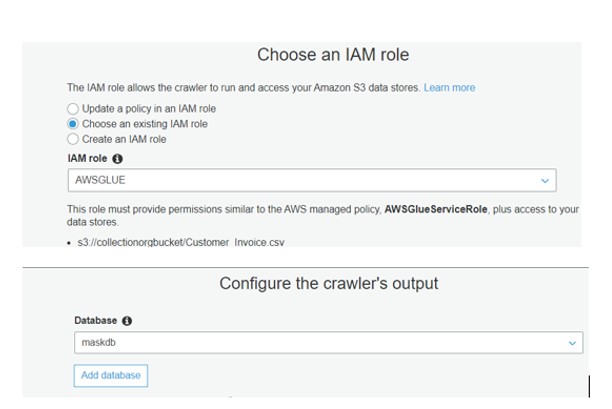
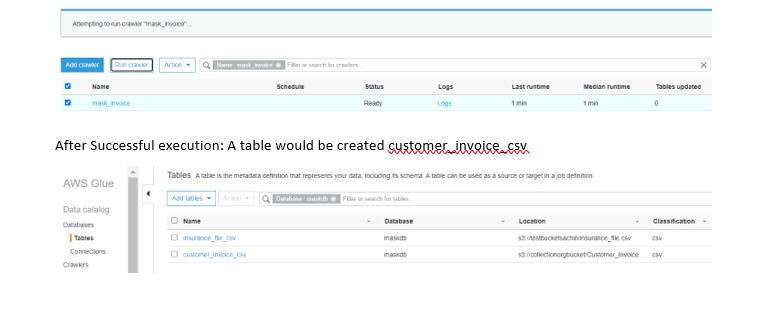
Run the Crawler:
Now create the GLUE JOB:
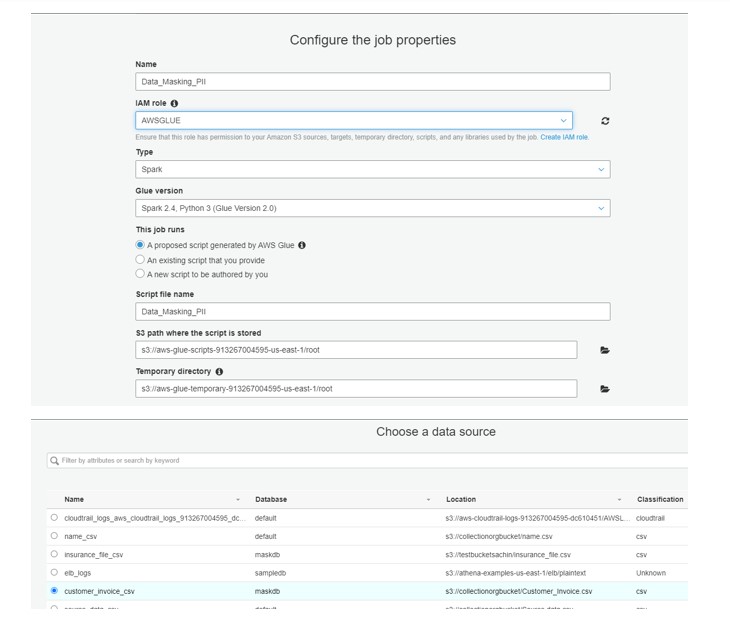
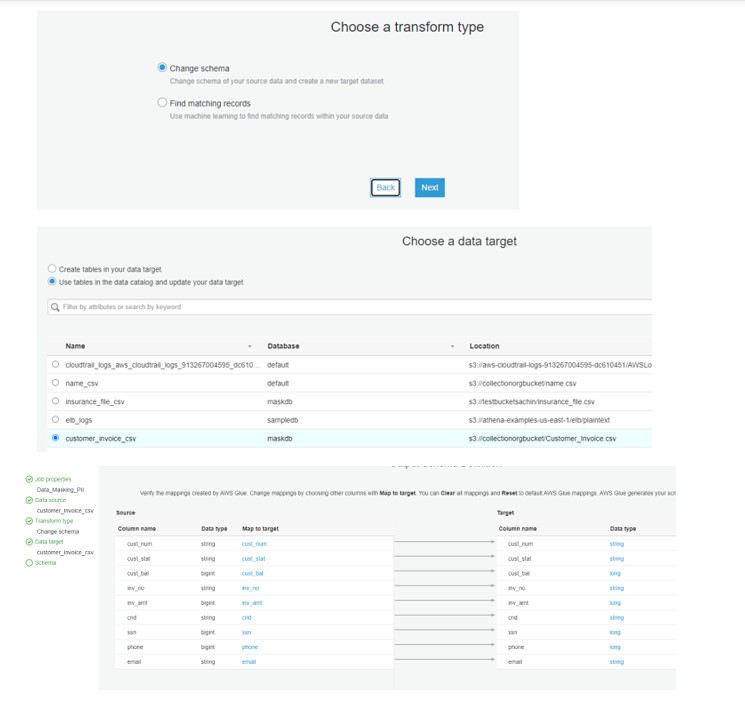
Now change the GLUE script as follows and run the program:
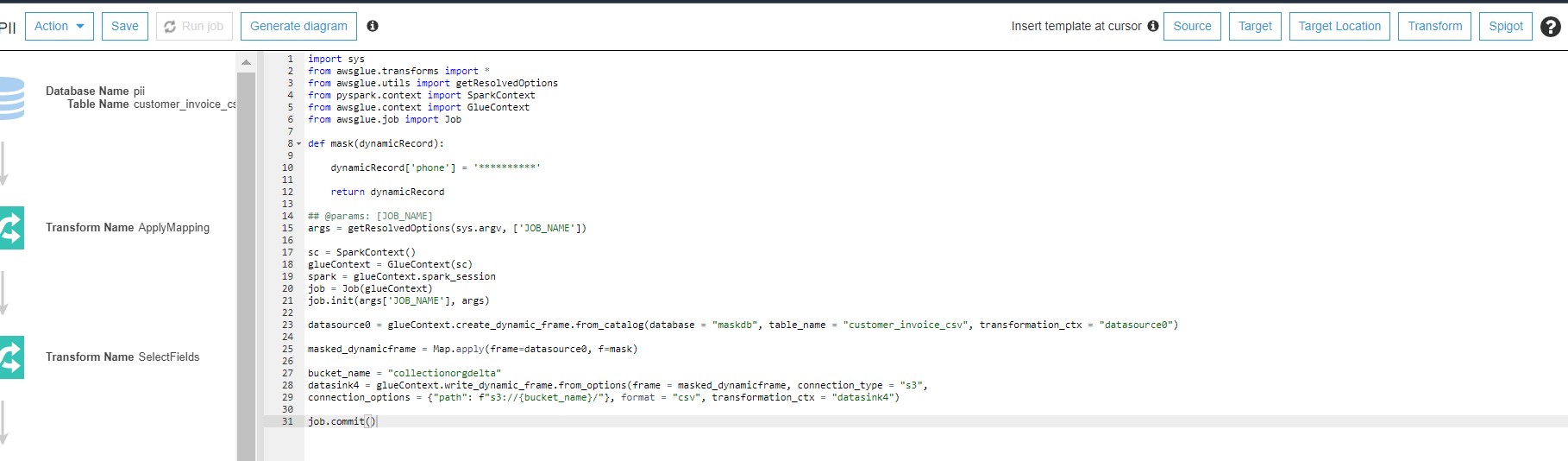
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
def mask(dynamicRecord):
dynamicRecord['phone'] = '**********'
return dynamicRecord
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "maskdb", table_name = "customer_invoice_csv", transformation_ctx = "datasource0")
masked_dynamicframe = Map.apply(frame=datasource0, f=mask)
bucket_name = "collectionorgdelta"
datasink4 = glueContext.write_dynamic_frame.from_options(frame = masked_dynamicframe, connection_type = "s3",
connection_options = {"path": f"s3://{bucket_name}/"}, format = "csv", transformation_ctx = "datasink4")
job.commit()
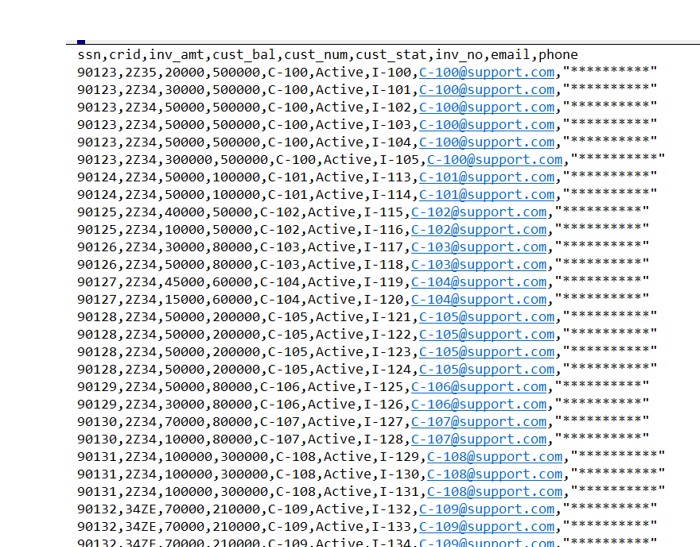
After the execution ,we can see new File is available in bucket.
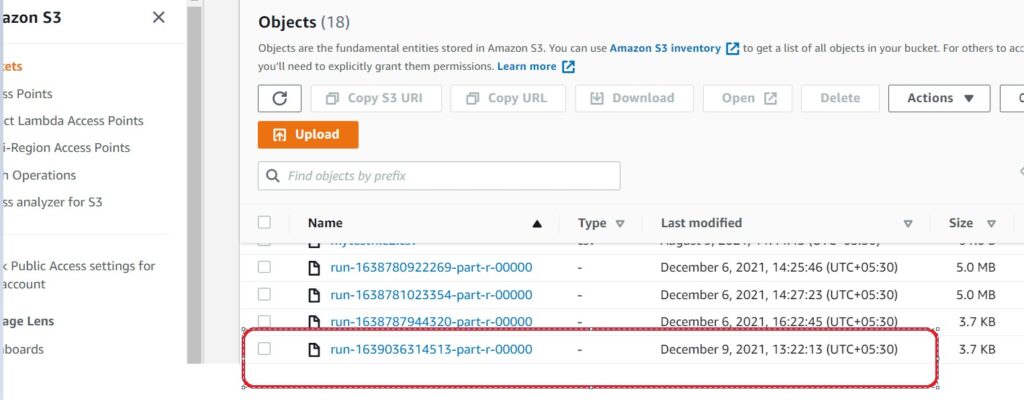
We can verify the masked data inside the file:








Hey, thanks for this.
Couple of questions:
1. Since we are masking data in S3 itself, I’ll not be able to see the actual data in snowflake which is the requirements here but what will happen if I need to use the actual value of column in some ETL operation in snowflake?
2. Do you have a such usecase? I was thinking of using external data masking/encryption through protegrity software, any post for that?
Hi Naveen,Thanks for the question
For this use case if you noticed we are generating the new masked FEED file and will upload into another S3 bucket. There Lambda function would be triggerd and in return it will call the Glue job to connect with snowflake. This way we are consuming the masked file only for snowflake and the original file will remain same in original bucket whcih can be consumed by downstream systems.
Another approach is that we can use the KMS service to encrypt the file at Bucket level,but this will encrypt the complete file while our requirement was masking only PII data