In this post, we will explore the process of splitting a large file into smaller ones based on the data count. Recently, we encountered a file in our Blob storage area that contained approximately 20 million records. The client’s requirement is to process this file in Snowflake.
While it’s possible to process this file as-is in Snowflake using the COPY command, it’s important to note that doing so may lead to performance issues due to the file’s substantial size. Additionally, Snowflake itself recommends avoiding this approach as it can result in increased warehouse costs, as the warehouse remains occupied during the entire processing period. As per Snowflake’s documentation:
“To distribute the load among the compute resources in an active warehouse, it is advisable to split larger files into a greater number of smaller files. The number of data files processed in parallel depends on the available compute resources in a warehouse. We recommend splitting large files by line to prevent records from spanning across chunks.”
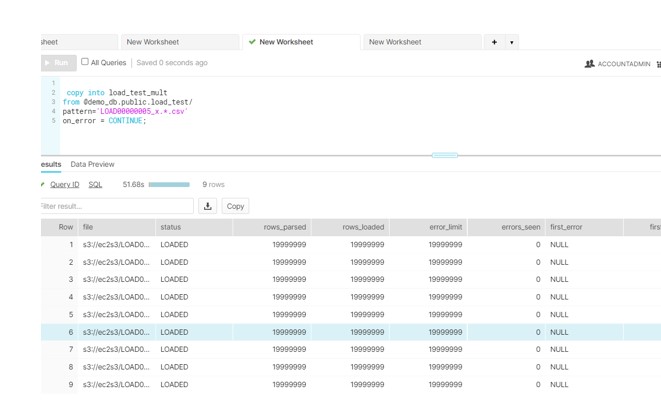
To address this, we utilized the ADF COPY activity command to divide the large file into smaller, more manageable files. Our approach was to segment the data so that each resulting file would contain approximately 2 million records.
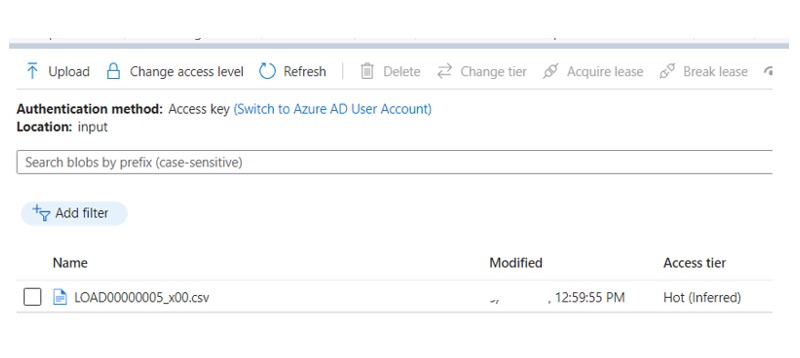
Below, you can see the original file that was located in our Container area.
ADF Details:
We developed below simple ADF pipeline leveraging the COPY utility to split and copy the data into destination container.
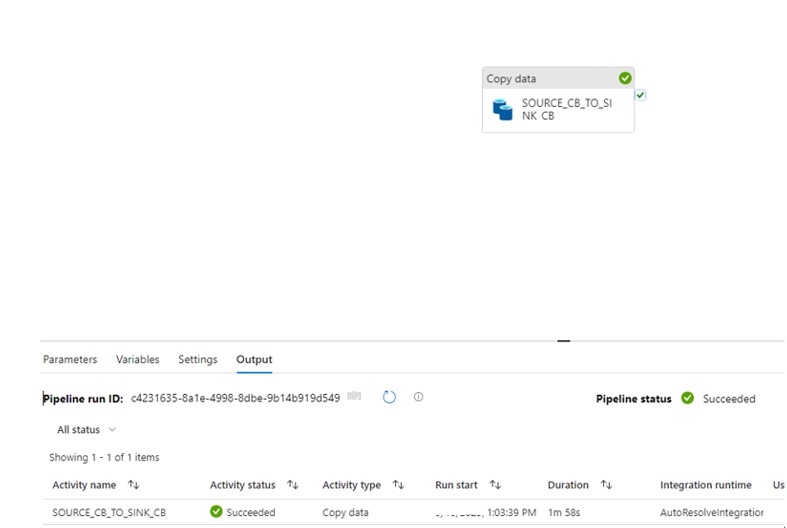
In the Sink, we can set the number of Rows per file. So I setup 2000000 count for each file which means it will split the source file based on the defined number of records.
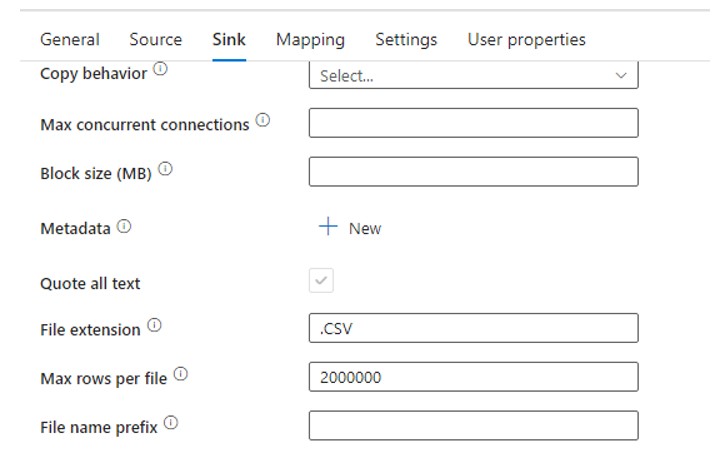
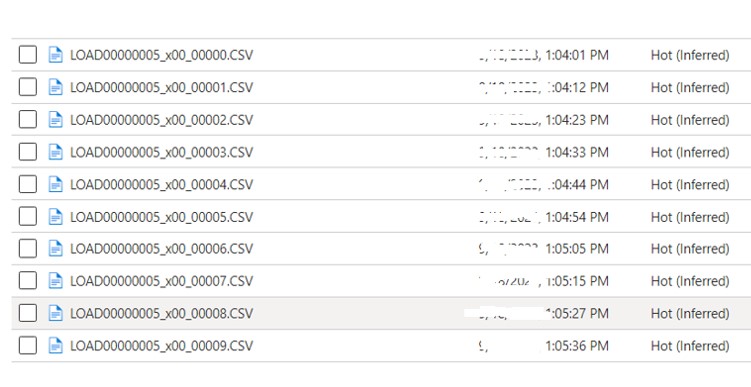
After the execution of Pipeline below 10 files gets created inside the destination container.
To process the file into Snowflake we need to create Secure Integration, stage, file format etc…
Now load the data using COPY with Pattern command.
copy into cust_tbl
from @demo_db.public.az_stage
on_error = CONTINUE
pattern='LOAD0000005_x.*.csv’;
AWS implementation:
AWS implementation:
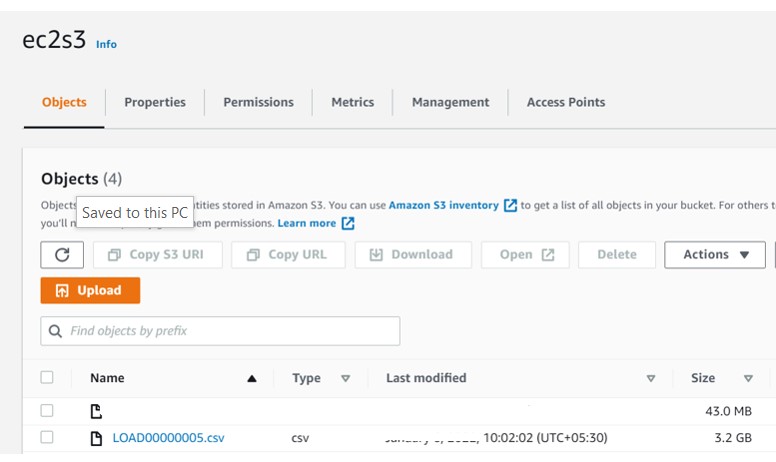
What if we encounter a similar file in an AWS S3 bucket, and the customer doesn’t have access to Azure Data Factory (ADF) or Azure licenses? In such cases, we have the option to create a UNIX script that can split the files based on the number of lines and execute it using the AWS CLI.
Technical implementation:
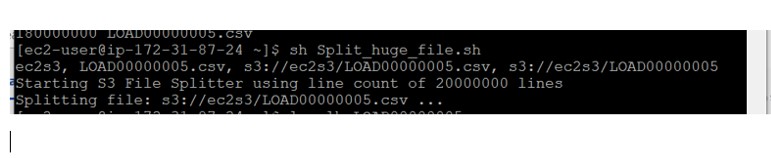
Login to the EC2 machine and create the shell script (Split_huge_file.sh) with below content. Here we have separated the file with 20 Millions lines per file. Hence 9 files should be generated.
S3_BUCKET=ec2s3
FILENAME= LOAD00000005.csv
INFILE=s3://"${S3_BUCKET}"/"${FILENAME}"
OUTFILE=s3://"${S3_BUCKET}"/"${FILENAME%%.*}"
echo $S3_BUCKET, $FILENAME, $INFILE, $OUTFILE
echo "Starting S3 File Splitter using line count of 20000000 lines"
echo "Splitting file: "${INFILE}" ..."
FILES=($(aws s3 cp "${INFILE}" - | split -d -l 20000000 --filter "aws s3 cp - \"${OUTFILE}_\$FILE.csv\" | echo \"\$FILE.csv\""))
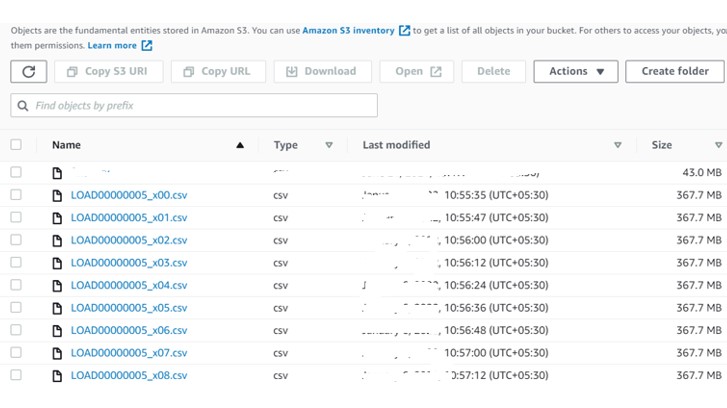
Now load these files parallelly in Snowflake.