Data Pipeline: During this post we will talk about the basics of Kinesis data stream and Firehose services of AWS . A Kinesis data stream is basically a publish/subscribe system used to collect and process large streams of data records in real time. Web applications generates the streaming data, and this data can be gather by tools like Amazon Kinesis. Amazon Firehose is used to capture and load data into other Amazon services such as S3 and Redshift.
Kinesis Data Streams and Firehose are design to work well together, so when you create a Firehose, you can tell it to use an already created Data Stream as input.
AWS Glue is a Serverless Extract, Transform, and Load (ETL) service combines the speed and power of Apache Spark. Here we have used Glue to convert JSON data format to Parquet format. Parquet, columnar storage file format saves both time and space when it comes to big data processing.
We have Used Lambda function to automate the below two things in pipeline:
- Lambda to Trigger the Kinesis Data stream once file uploaded to Bucket.
- Call the AWS Glue Service
Snowpipe, consumes the file uploaded by Glue to the Bucket and ingest to the Snowflake.
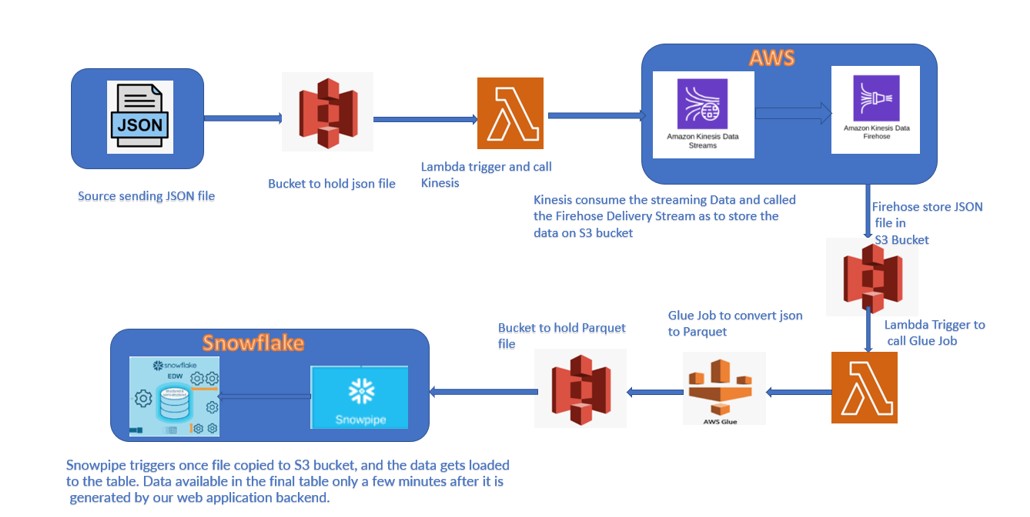
Following data pipe line we have implemented in the project:
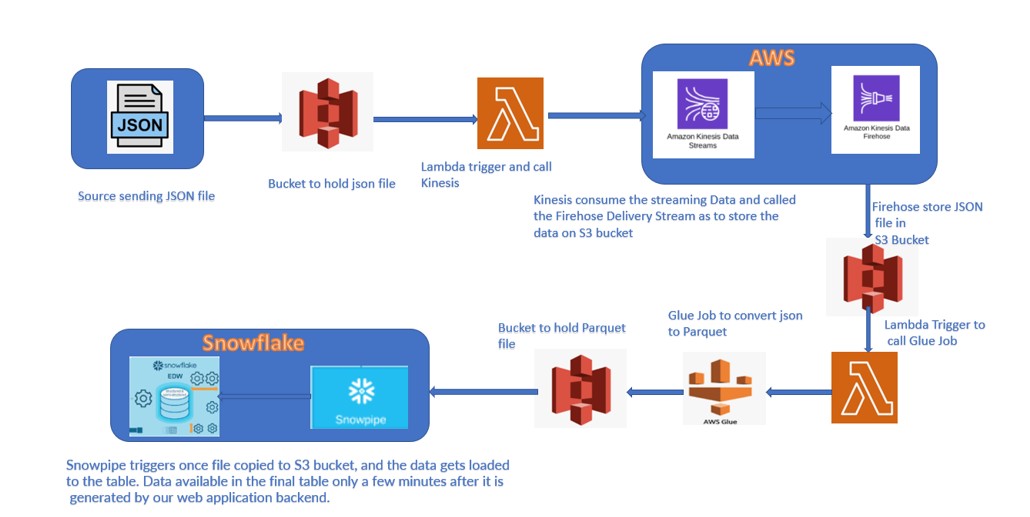
Steps performed in the Pipeline:
- Customer Feed file uploaded to the Source bucket.
- Once the File uploaded, Lambda gets trigger and call the Kinesis Data Stream.
- Kinesis Data stream calls the Firehose and store the file on S3 bucket.
- As soon as the file upload to the bucket, another Lambda gets trigger and call the Glue Job.
- AWS Glue job runs and convert the JSON file format to Parquet file format
- Glue Job place this new file to the destination bucket.
- Snowpipe configure on the destination bucket and trigger once file uploads to Bucket.
- Data gets ingest to the Snowflake.
We will share the technical implementation (Code) of Data Pipeline in next part of this series.







