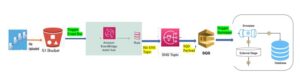
In Snowflake Data Flow , Data pipelines eliminates most of manual and error-prone processes involved in Data transportation. Automation helps , a high-performance data pipeline can effectively fight data latency and bottlenecks.

- Snowflake data flow features or a third-party data integration tool (not shown) loads data continuously into a staging table.
- One or more table streams capture change data and make it available to query.
- One or more tasks execute SQL statements (which could call stored procedures) to transform the change data . Later on this changed data move the optimized data sets into destination tables for analysis.
- Transformation process capture data in stream and perform the DML operations on the target table.
- Later on consumes the change data when the transaction commits.
What’s the difference between ETL and a data pipeline? .
ETL is usually a sub-process in the data pipeline (and depending on the nature of the pipeline, may not be included).
It really only refers to the (often batch) process of extracting, transforming, and loading data from one system to another. A data pipeline, on the other hand, is the entire process involve in migrating data from one location to another.
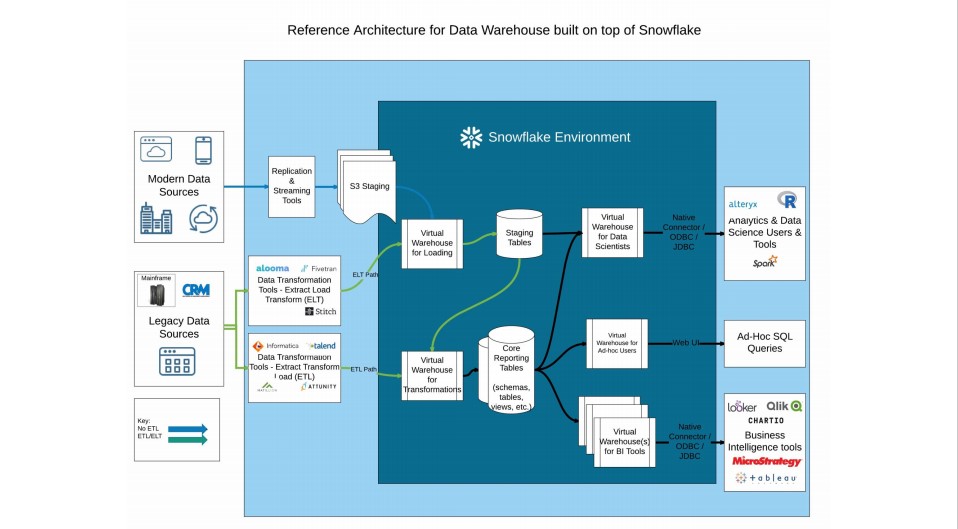
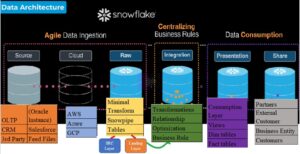
Below figure depicts 360 degree holistic view about the Snowflake Architecture .
According to the process, Data imports from various source system via Streaming/Task or ETL tools. For few systems data copies on Cloud platform in Buckets which is later consume by Snowflake.
Final Transformed data is being extracted or presented via Reporting tools to be used by Business.