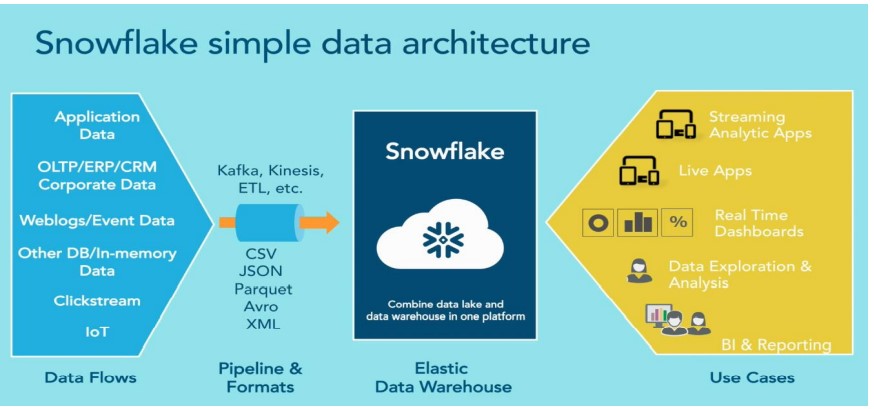
A Snowflake data pipeline architecture is a system that captures, organizes, and routes Data. Raw data contains too many data points that may not be relevant. Snowflake Data pipeline architecture organizes data events to make reporting, analysis, and using data easier.
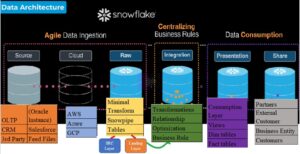
Data pipelines automate many of the manual steps involved in transforming and optimizing continuous data loads. Frequently, the “raw” data is first loaded temporarily into a staging table. Later on transformed using a series of SQL statements before it is inserted into the destination reporting tables. The most efficient workflow for this process involves transforming only data that is new or modified.
A Data pipeline refers to the process of moving data from one system to another. The standard data engineering goal of a data platform is to create a process that can be arbitrarily repeated without any change in results.
Modern data pipelines provide many benefits to the enterprise, including easier access to insights and information, speedier decision-making and the flexibility and agility to handle peak demand. Modern, cloud-based data pipelines can leverage instant elasticity at a far lower price point than traditional solutions. They offer agile provisioning when demand spikes, eliminate acess barriers to shared data, and, unlike hardware-constrained pipelines, enable quick deployment across the entire business.
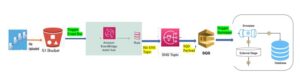
Belong diagram shows the Snowflake Data pipelines: