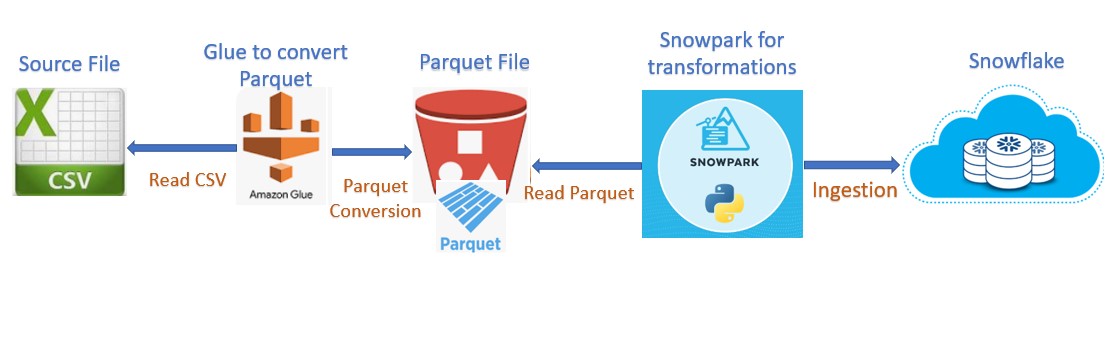
During this post we will discuss a simple scenario using AWS Glue and Snowpark. Since long time I was planning to start and learn Snowpark and has come up with this simple and basic use-case to implement Glue and Snowpark in one pipeline. As per the requirement source system has fed a CSV file to our S3 bucket which needs to be ingested into Snowflake. Instead of consuming the file as-is we are supposed to convert the file into Parquet format. Parquet, columnar storage file format saves both time and space when it comes to big data processing.
To convert the csv to Parquet, we have used AWS Glue service which reads the file from the S3 bucket. Job applies the transformations and convert the file and place it into another destination bucket. Also, we ensure that the file generates after the conversion should having proper naming convention and included the logic in Glue job as well.
Once the final file is available inside the bucket, we have used Snowpark framework to perform the multiple steps below and ingest the final into Snowflake.
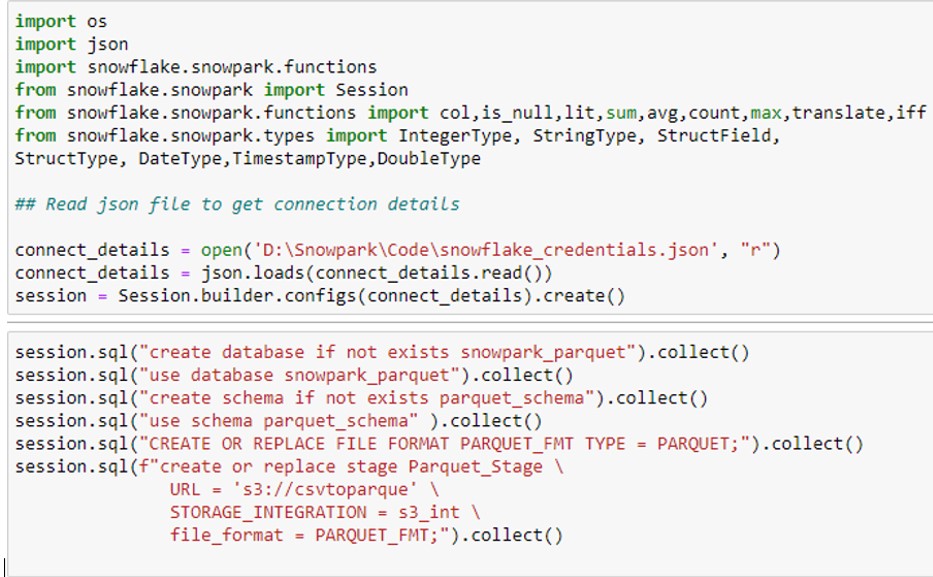
- Store the credentials into JSON file and establish a Snowpark session using JSON file.
- Create:
- Database
- Schema
- File format
- Create the External stage point to the file generated by Glue Job
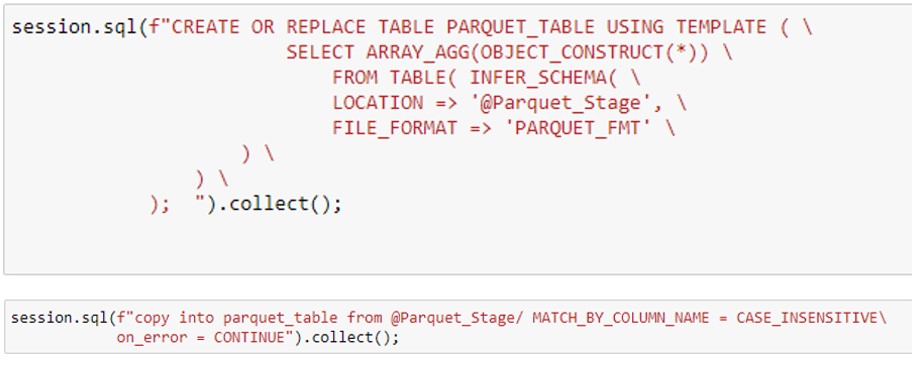
- Create the Table in snowflake using Snowflake Schema Detection and INFER_SCHEMA features which refers to the parquet file and create the structure automatically.
- COPY the data from external stage to Snowflake table created in previous step.
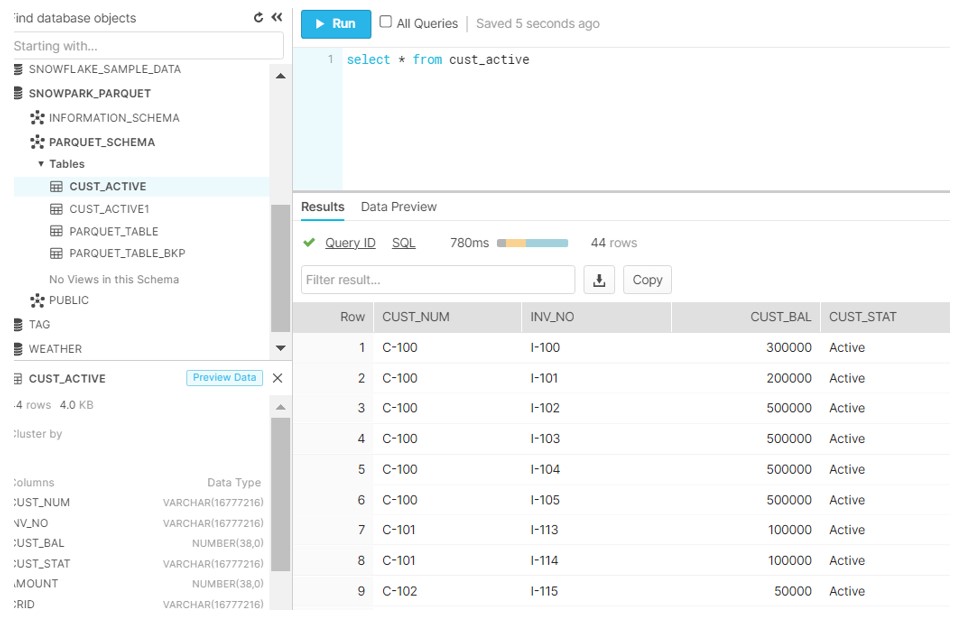
- Read the data from the table and filtered only Active status records in dataframe.
- Load the dataframe into Snowflake in the new table.
Technical Implementation:
- GLUE Job.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "pii", table_name = "customer_invoice_csv", transformation_ctx = "datasource0")
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("CUST_NUM", "string", "CUST_NUM", "string"), ("CUST_STAT", "string", "CUST_STAT", "string"), ("CUST_BAL", "long", "CUST_BAL", "long"), ("INV_NO", "string", "INV_NO", "string"), ("INV_AMT", "long", "INV_AMT", "long"), ("CRID", "string", "CRID", "string"), ("SSN", "long", "SSN", "long"), ("PHONE", "long", "PHONE", "long"), ("EMAIL", "string", "EMAIL", "string")], transformation_ctx = "applymapping1")
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://csvtoparque"}, format = "parquet", transformation_ctx = "datasink4")
import boto3
client = boto3.client('s3')
BUCKET_NAME = "csvtoparque"
PREFIX = "part-"
response = client.list_objects(
Bucket=BUCKET_NAME,
Prefix=PREFIX,
)
name = response["Contents"][0]["Key"]
copy_source = {'Bucket': BUCKET_NAME, 'Key': name}
copy_key = PREFIX + 'invoice_details.parquet'
client.copy(CopySource=copy_source, Bucket=BUCKET_NAME, Key=copy_key)
client.delete_object(Bucket=BUCKET_NAME,Key=name)
job.commit()
- Parquet file in Bucket:
- Snowpark Code.