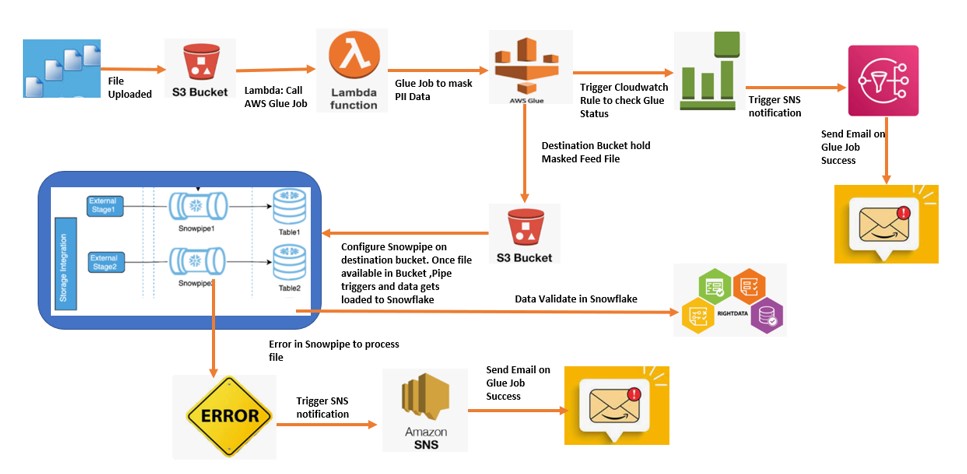
During this post we will discuss about below end-to-end pipeline.
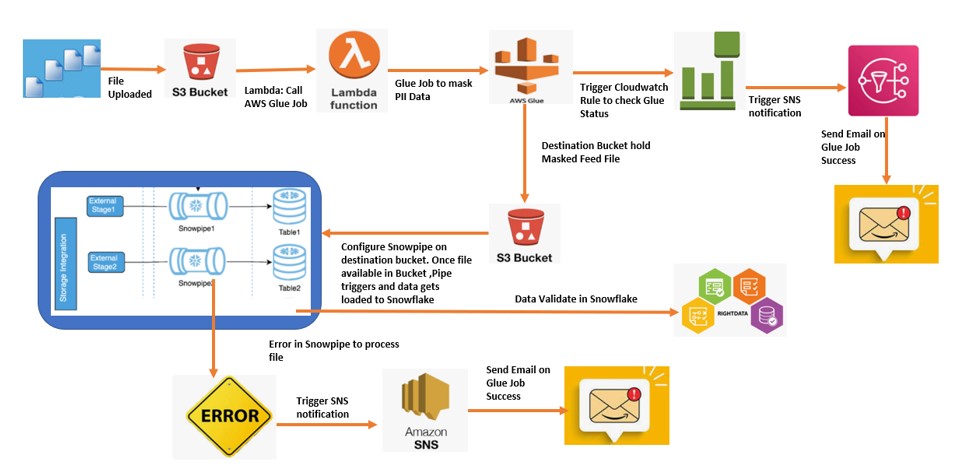
As we can see in above Datapipeline, we have used several AWS and Snowflake components at one place.
AWS Glue is a Serverless Extract, Transform, and Load (ETL) service combines the speed and power of Apache Spark. Moreover,we have Used Lambda function to automate and Call the AWS Glue Service. However, We have leveraged the Cloud watch events to define a Rule based on the status of Glue job. Finally, AWS SNS service is used to notify the stakeholders about Glue job.
Finally, Configure Snowpipe, consumes the file uploaded by Glue to the Bucket and ingest to the Snowflake. Implement snowflake Error notification which will send email in case of pipe failure.
Steps performed in the Pipeline:
- Firstly, Customer Feed file uploaded to the Source bucket.
- Once the File uploaded, Lambda gets trigger and call the AWS Glue job.
- Once the AWS Glue job runs it masks the data inside the Feed file.
- Therefore, Glue Job place this new file to the destination bucket.
- Moreover, Configure the Cloud watch Event Rules to check the status of Glue Job.
- Therefore, Based on the Glue Job Status ,SNS will be triggered to send an email to respective stakeholders.
- Snowpipe configure on the destination bucket and trigger once file uploads to Bucket.
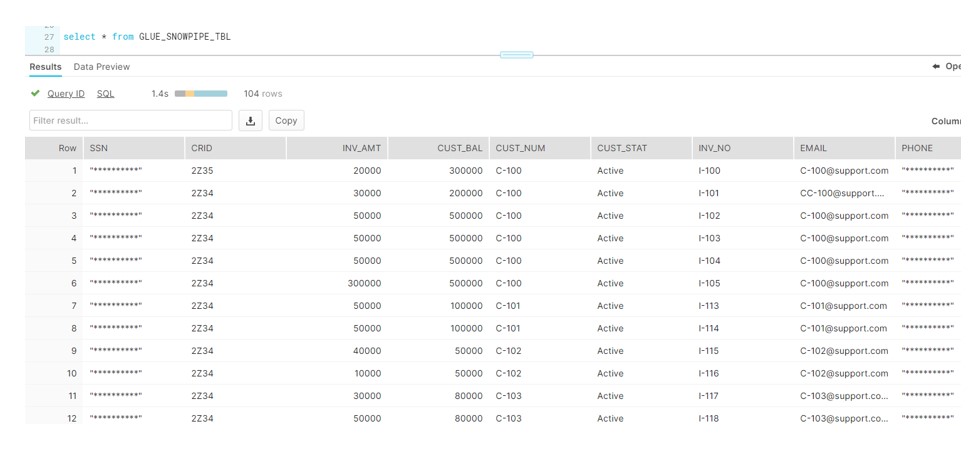
- Finally, Data gets ingest to the Snowflake.
- Above all, Configure the Snowpipe Error Notification to check the status of Snowpipe Job.
- In case of any error to the Snowpipe,SNS will be triggered to send an email to respective stakeholders.
Technical implementation (Code) of Data Pipeline:
Source bucket
Lambda function: Glue_Masking_Lambda
GlueJob: Job_Masking_PII_Data
Destination bucket: gluedatamasking
CloudWatch Rules:Masking_Glue_job_notify
SNS:EC2_LOGS_Email_Send
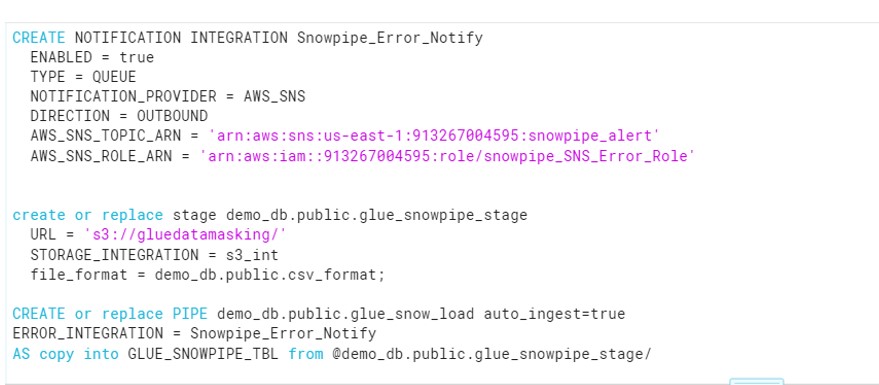
SnowPipe:glue_snow_load
Snowpipe Error notification:Snowpipe_Error_Notify
SNS:snowpipe_alert
Code
Lambda Function:
import json
import boto3
def lambda_handler(event, context):
s3_client = boto3.client("glue");
s3_client.start_job_run(JobName="Job_Masking_PII_Data")
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
Glue Script:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
def mask(dynamicRecord):
dynamicRecord['phone'] = '**********'
dynamicRecord['ssn'] = '**********'
return dynamicRecord
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
import boto3
client = boto3.client('s3')
BUCK_NAME = "gluedatamasking"
PREFIX = "run-"
response = client.list_objects(
Bucket=BUCK_NAME,
Prefix=PREFIX,
)
name = response["Contents"][0]["Key"]
client.delete_object(Bucket=BUCK_NAME, Key=name)
job.commit();
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "pii", table_name = "pii_customer_invoice_csv", transformation_ctx = "datasource0")
masked_dynamicframe = Map.apply(frame=datasource0, f=mask)
bucket_name = "gluedatamasking"
datasink4 = glueContext.write_dynamic_frame.from_options(frame = masked_dynamicframe, connection_type = "s3", connection_options = {"path": f"s3://{bucket_name}/"}, format = "csv", transformation_ctx = "datasink4")
Snowflake:
create or replace table GLUE_SNOWPIPE_TBL (
SSN VARCHAR(20),
CRID VARCHAR(4),
INV_AMT number(10) null,
CUST_BAL number(20) null,
CUST_NUM varchar(50) null,
CUST_STAT varchar(255) null,
INV_NO varchar(10) null,
Email VARCHAR(50),
phone varchar(20)
);