During the last post we discussed about Streams on External tables. In continuation of the same I explored more on External tables and encountered a word vectorized scanner. Initially I ignored this but observe this has been used multiple time in context with External tables. To know more about this feature I followed Snowflake blogs and found the below explanation:
The External Tables comes with a new vectorized scanner for parquet files, which is eight times faster than the previous, non-vectorized parquet scanner. Vectorized data processing helps with developing faster analytical query engines by making efficient utilization of CPU cache. In case of vectorized model instead of pushing one tuple at a time the complete block process. A block we can say, block of vectors, and each vector has a set of records or column values. The new vectorized scanner is designed to take advantage of parquet’s columnar file format.
So in terms of practical how the Parquet file vectorization on External tables has improved the performance we will compare the below two statements.
Say we have huge amount of parquet data stored in the S3 bucket. As part of the testing we would be ingesting this data into Snowflake Table via conventional COPY command.
First Approach:
- Create the stage pointing to the Parquet file on S3.
create or replace stage public.external_files_stage
storage_integration = s3_int
url = 's3://srcbucketsachin/parquet_vector'
file_format = (type = parquet);
- Create the Snowflake table
create or replace table SNOW_PARQUET_TABLE (
SR_RETURNED_DATE_SK NUMBER(38, 0) ,
SR_ITEM_SK NUMBER(38, 0) ,
SR_CUSTOMER_SK NUMBER(38, 0),
SR_CDEMO_SK NUMBER(38, 0),
SR_HDEMO_SK NUMBER(38, 0) ,
SR_ADDR_SK NUMBER(38, 0) ,
SR_STORE_SK NUMBER(38, 0),
SR_TICKET_NUMBER NUMBER(38, 0) ,
SR_FEE NUMBER(38, 0),
SR_NET_LOSS NUMBER(38, 0));
- Run the COPY command to load data from Staging to Table
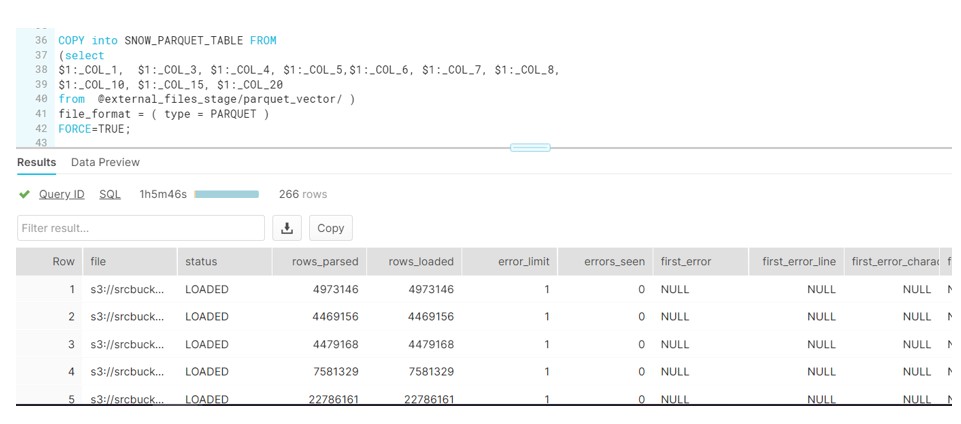
As we can see it took around 65 mins to load complete data via COPY command.
Second approach:
Second approach:
External Tables: Vectorized Parquet Scanner
- Create an External table pointing to the S# staging area where Parquet files are present.
create or replace external table ext_table_parquet (
SR_RETURNED_DATE_SK NUMBER(38, 0) as (value:"_COL_1"::number),
SR_ITEM_SK NUMBER(38, 0) as (value:"_COL_3"::number),
SR_CUSTOMER_SK NUMBER(38, 0) as (value:"_COL_4"::number),
SR_CDEMO_SK NUMBER(38, 0) as (value:"_COL_5"::number),
SR_HDEMO_SK NUMBER(38, 0) as (value:"_COL_6"::number),
SR_ADDR_SK NUMBER(38, 0) as (value:"_COL_7"::number),
SR_STORE_SK NUMBER(38, 0) as (value:"_COL_8"::number),
SR_TICKET_NUMBER NUMBER(38, 0) as (value:"_COL_10"::number),
SR_FEE NUMBER(38, 0) as (value:"_COL_15"::number),
SR_NET_LOSS NUMBER(38, 0) as (value:"_COL_20"::number))
location=@external_files_stage/parquet_vector/
file_format = (type = parquet);
- Create another Snowflake Table with same structure as of SNOW_PARQUET_TABLE.
- Now insert the data into this new table from External table and see the magic of Vectorization scanner processing:
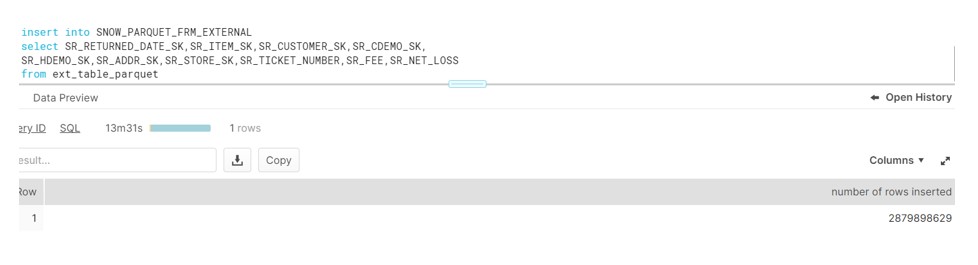
As we can see the same records gets inserted in only 14 mins.
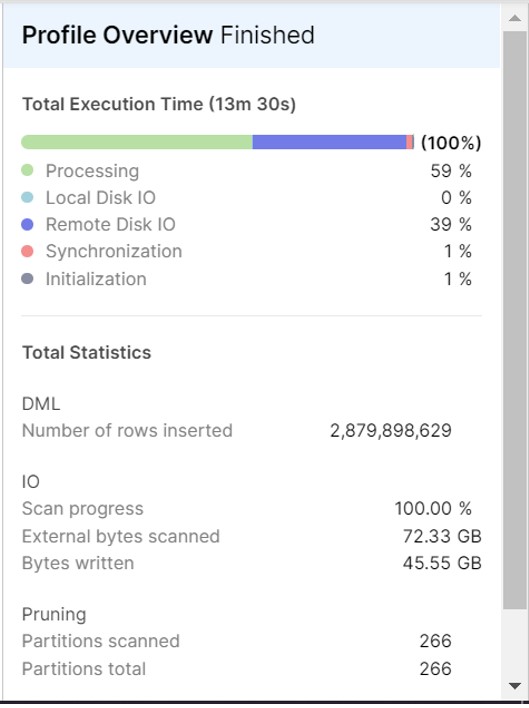
As we can see clearly,Vectorized scanner has improved the performance significantly