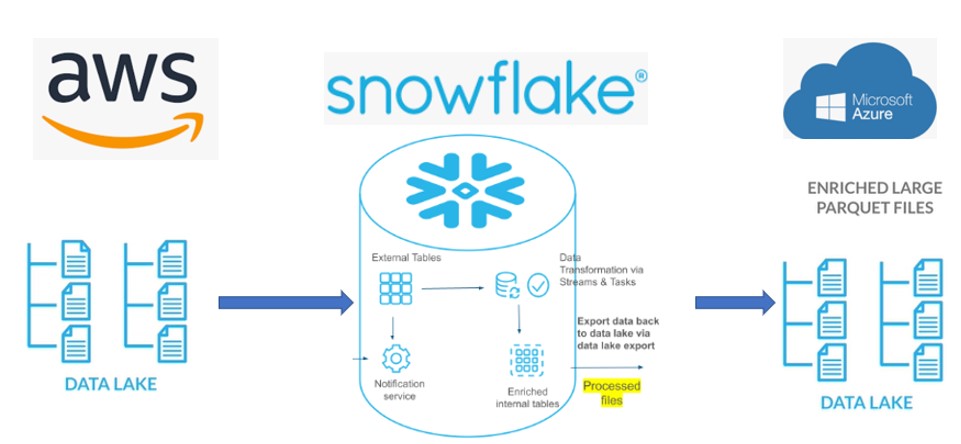
Streams on External Table: During this post we will discuss about STREAM property on External tables. We know in an external table, the data is stored in files on external stage. External tables are read-only, can use these tables to complement your existing data lake, and use it as a transformation engine without loading data into Snowflake. Landing zone accepts the files in as-is format and leveraging Snowflake computing power, converts these files to Parquet in Silver zone. Later on we can join these Parquet files with existing snowflake tables and produce meaningful data in Golden zone.
For our scenario, Customer has placed the files in S3 bucket but due to Azure expertise and ML capability the customer wants the processed data on Azure container. Beauty of External tables are without consuming the data into Snowflake we can enrich the data and export to cross cloud/cross region.
Streams on External tables are used to track any new files are coming to the Bucket instead of identifying the records from External table where count is cumulative, will use streams to find delta records.
Technical Implementation:
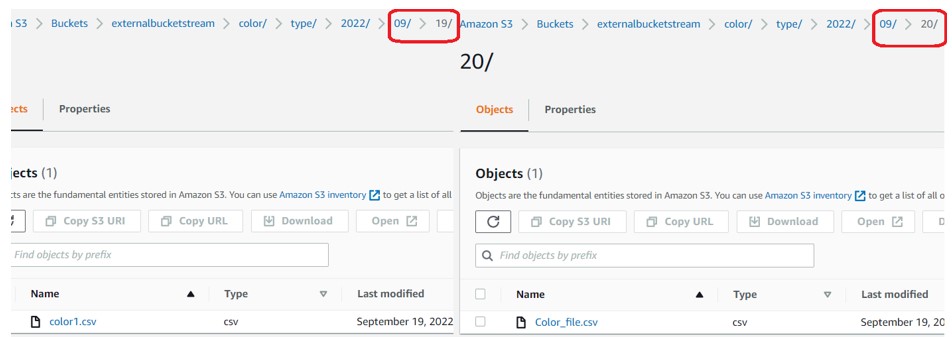
- Created the Folder structure on AWS Staging Area:
- Firstly, Create the stage pointing to S3 location:
create or replace stage demo_db.public.color_external_table
URL = 's3://externalbucketstream/color/'
STORAGE_INTEGRATION = s3_int
file_format = demo_db.public.csv_format;
- Secondly, Create External table and partition on YYYY-MM-DD
create or replace external table colors (
partdate date as to_date(split_part(metadata$filename, '/', 3) || '-' ||
split_part(metadata$filename, '/', 4) || '-' ||
split_part(metadata$filename, '/', 5),'YYYY-MM-DD'),
Color_Code varchar(10) as (value:c1::varchar),
Color varchar(20) as ( value:c2::varchar),
color_Type varchar(10) as (value:c3::varchar))
partition by (partdate)
location = @demo_db.public.color_external_table
auto_refresh = true
file_format = csv_format;
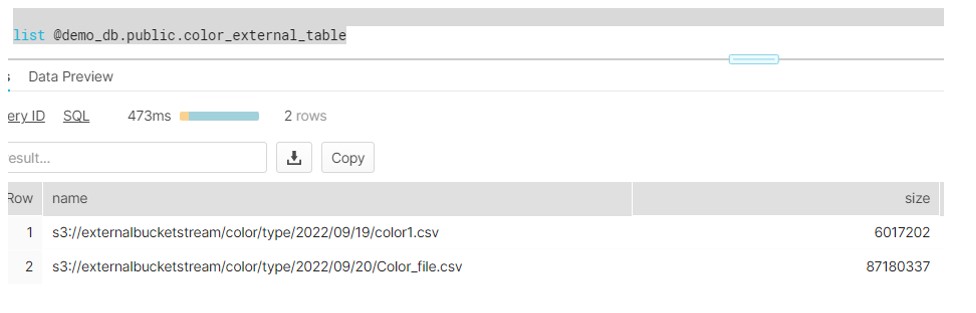
- Thirdly, Create stream on External table
create or replace stream color_stream on external table colors INSERT_ONLY = true;
- Upload the files into S3 staging location.
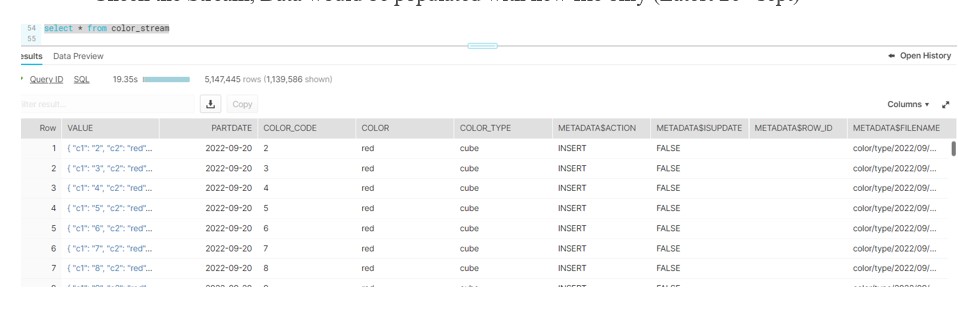
- Check the Stream, Data would be populated with new file only (Latest 20th sept).
To export this into Azure Container:
- Firstly, Create Storage Integration, Pointing to Azure Blob Container
create or replace storage integration azure_int
type = external_stage
storage_provider = azure
enabled = true
azure_tenant_id = '8bfd4cdf-17b0-4e3e-8d6f-a4312a644108'
storage_allowed_locations = ('azure://sachinazurelearning.blob.core.windows.net/snowbucket');
- Secondly, Create Parquet file format
create or replace file format demo_db.public.parquet_format_azure type = parquet;
- Thirdly, Create stage to export the Parquet files on Azure.
create or replace stage demo_db.public.az_stage
storage_integration = azure_int
url = 'azure://sachinazurelearning.blob.core.windows.net/snowbucket'
file_format = parquet_format_azure;
- Unload data to Azure container in Parquet format from Stream.
COPY into @az_stage/export
from
(select partdate,Color_Code,color,color_Type from color_stream)
partition by ('/date=' || partdate);

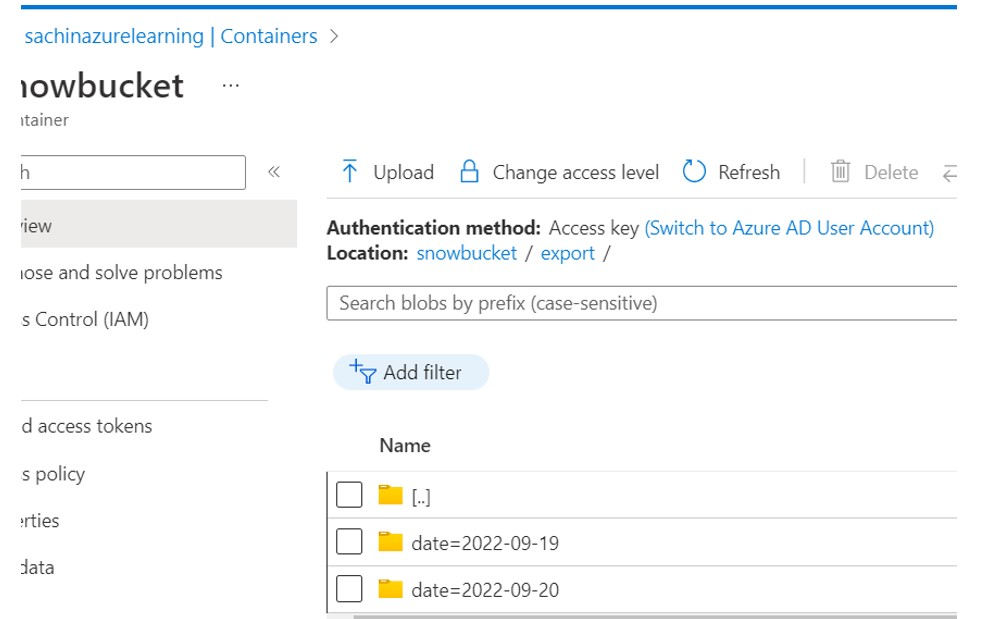
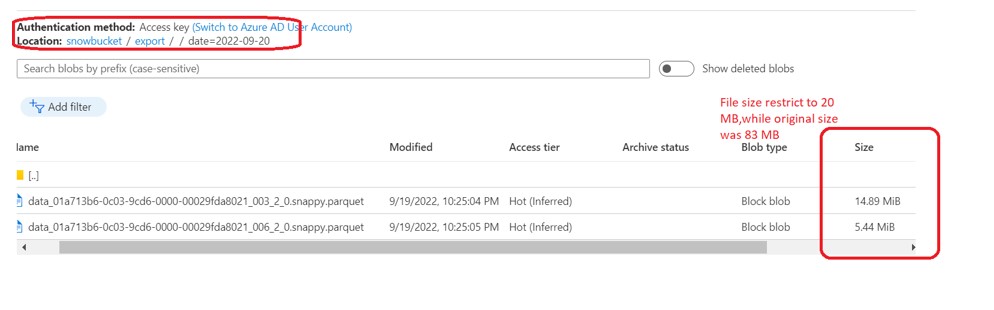
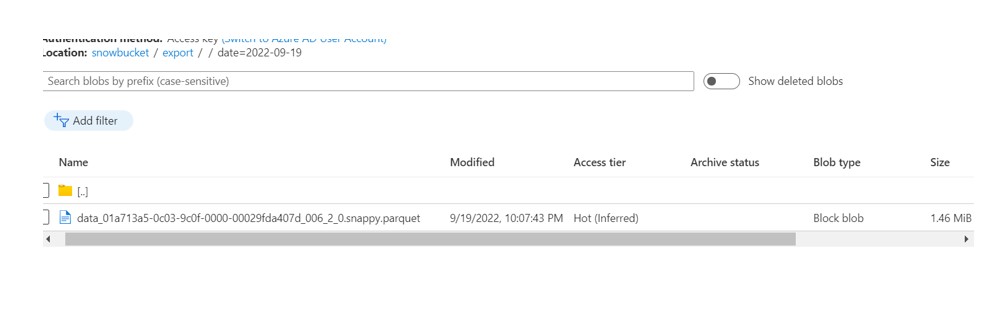
Verify at Azure:








Hi Sachin,
While I am doing same thing data is not populating in streams, can you please explain me.