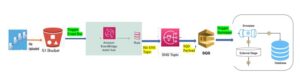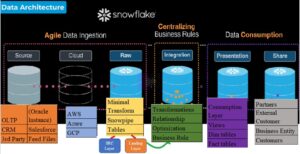
During this post we will discuss about the Data Quality features in Snowflake. As per the definition, Data quality is a measure of the condition of data based on factors such as accuracy, completeness, consistency, reliability and whether it’s up to date. Example of data Quality are duplicates, missing data, wrong or incorrect data, inconsistency, poor mismanagement etc. Meaningful data is utmost importance for Business, Issues in Data quality reduces the authenticity, credibility and reliability of data. With tracking the data quality, business ensures no data redundancy and ensures the meaningful data persist in system.
It is also fact that data quality goes toss up by multiple ways and one of the prominent factor is data getting from heterogeneous systems. Snowflake has addressed this concern seriously and provide multiple out-of-box features to handle data quality.
We will discuss some of the popular and commonly used features in rest of the section.
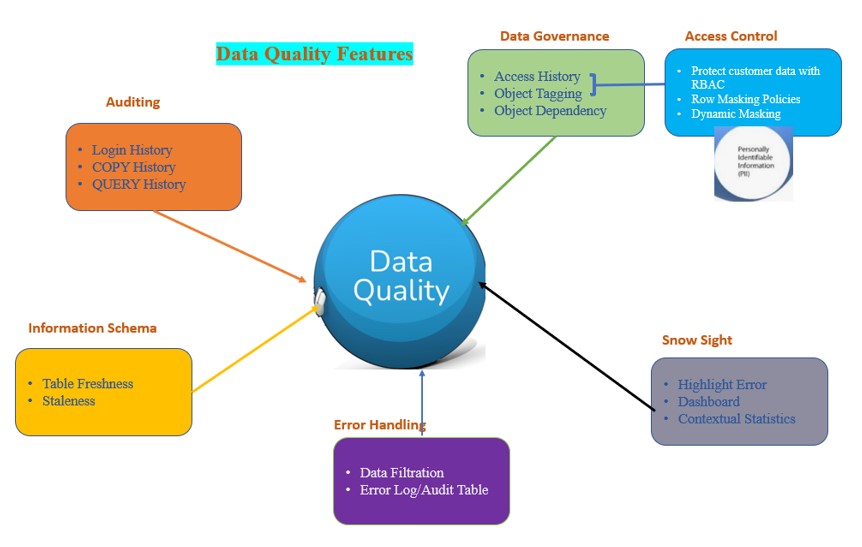
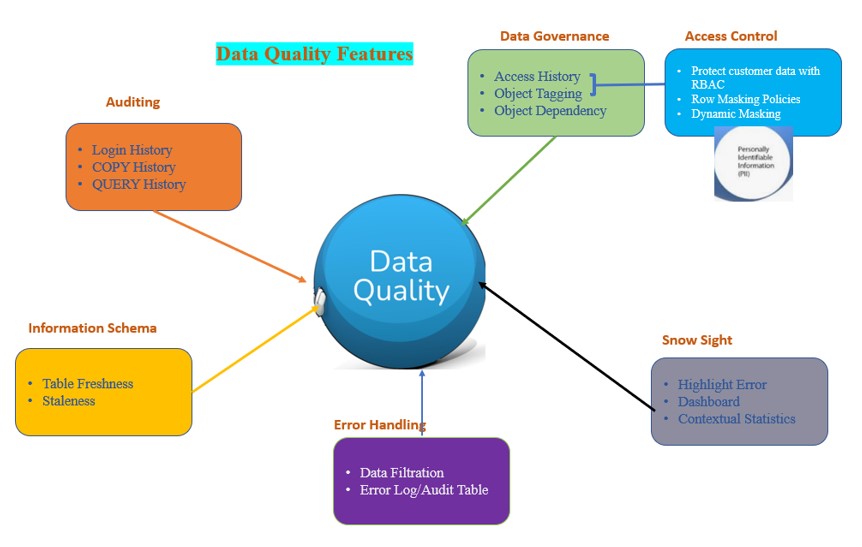
- Data Governance:
- Access History
- Object Tagging
- Object Dependency
- Auditing:
- Audit trail of Login History
- COPY HISTORY
- QUERY HISTORY
- Information Schema to identify Stale tables:
- Tables Freshness and last access
- Error Handling
- Snowsight
Data Governance:
Data Governance: Snowflake’s approach to data governance is founded on the core principles of knowing (Tagging and Access History), protecting (Masking), and data sharing.
- Access History: Use to track read operationhistory on Table or any Column. Common scenario is to help in formulating the decision to implement masking or not. Before implementing, Business wants to Audit, if users are really accessing PII data and are they entitle to access it. Moreover, how frequently they are trying to hit PII data. Based on their usage history and authorization business will further decide if these column to be masked or not.
- Object Tagging: Object tagging is used track sensitive data, such as PII (Personally Identifiable Information) data. We used tags to classify our sensitive data, so we can locate them with ease. Upper management can then easily break down who is accessing the sensitive fields data and can leverage this information for Reporting purpose.
So, to identify the user pattern and access behavior we have used the Object tagging and Access History governance features to get information in details
Refer: https://cloudyard.in/2022/09/object-tagging-with-dynamic-masking/
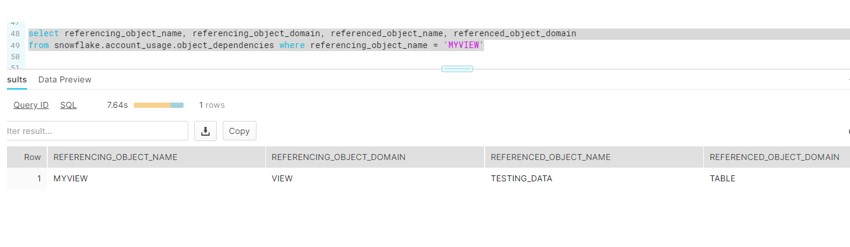
3. Object Dependency: Object dependency helps the analyst to identify the relationships between referencing objects and referenced objects. This also ensures that updates to referenced objects do not adversely impact users of the referencing object.
Create view CUST_DETAILS as select * from CUSTOMER;
Before ALTERING the table, Querying the OBJECT_DEPENDENCIES view base on the table name returns all of the objects (e.g. views) that will be affected.
select referencing_object_name,
referencing_object_domain,
referenced_object_name,
referenced_object_domain
from snowflake.account_usage.object_dependencies
where referencing_object_name = 'MYVIEW';
In next post we will continue to discuss the rest Data quality features in detail.
Note: Thanks to MonteCarlodata for making me understand the Data quality features in detail.