During last post we talked about to Handle Duplicate Records with No matching Key. Consider the scenario where source team would provide the complete file instead of Delta on daily base. Snowflake Developer team has to process this feed file in Database. Instead of consuming the complete file in Snowflake Database which will cause duplicate records ,Team has to identify the new records . Only the new records needs to be process existing records should be left out.
In addition to it there was no matching key defined on the table so that we can identify whether the same records has been processed during previous run or not. To handle such scenario we are using the HASH(*) function , HASH(*) returns a single value per row based on the column values.
We developed the MERGE Statement along with CTE and HASH function. But the solution we implemented was not dynamic and requires manual intervention for any new table. Say you have to develop the same process for multiple tables. Either we can write the same piece of code (of course change table name and table columns) multiple times. Or we can develop a process where input is Source table name and output is Target table name. Process should be flexible enough to pick the columns dynamically ,no need to mention explicitly.
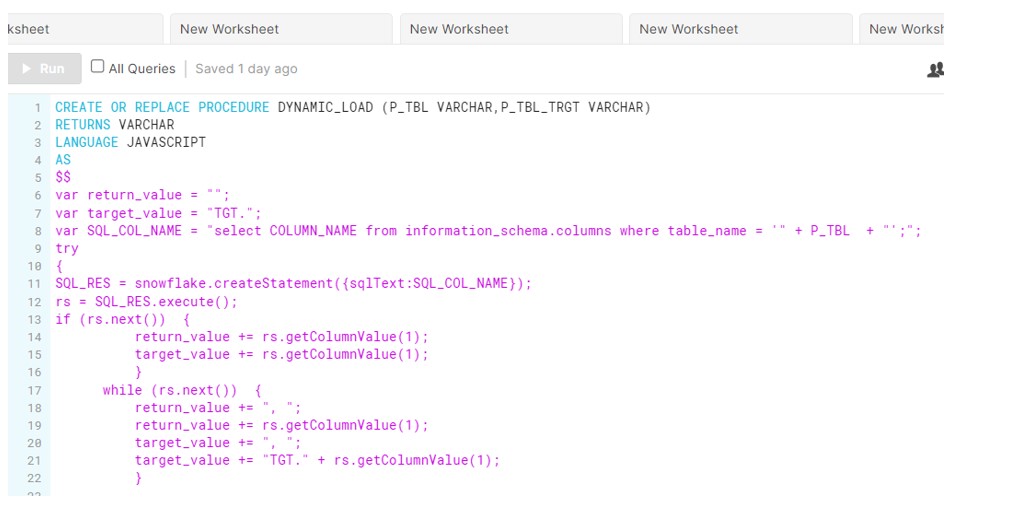
So we have developed a below Javascript procedure with two input arguments. It will generate the list of columns programmatically and build the Dynamic Merge sql which will handle Duplicate Records Dynamically.
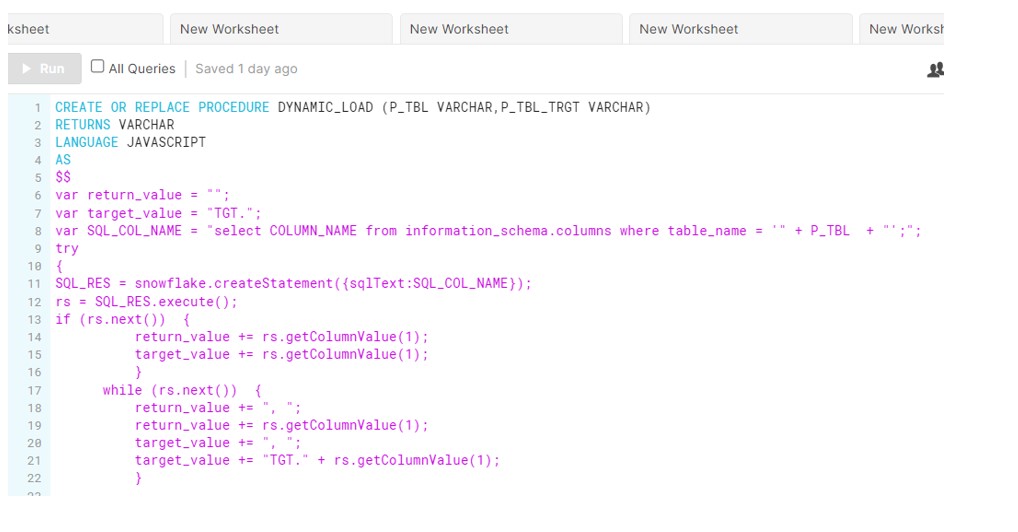
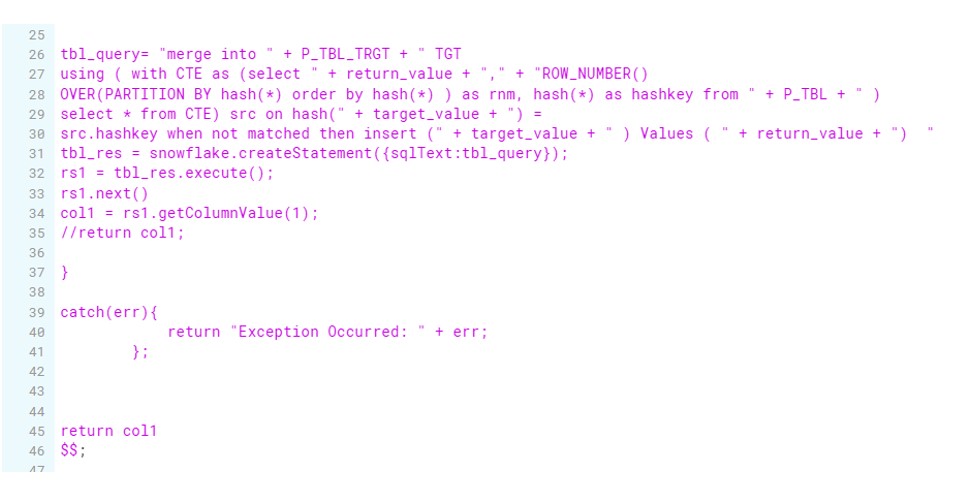
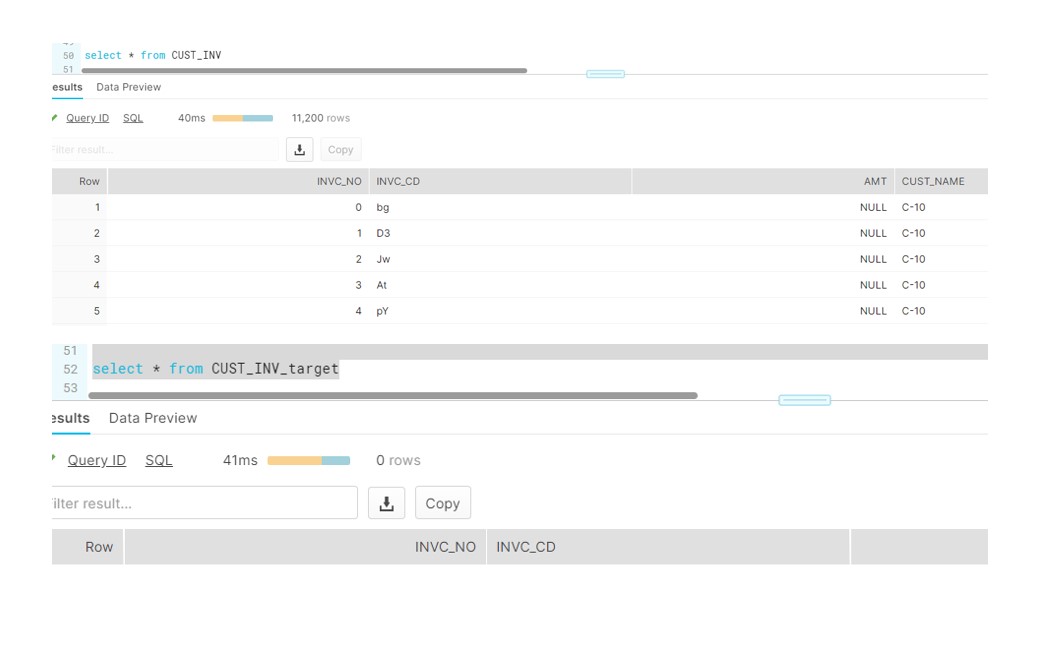
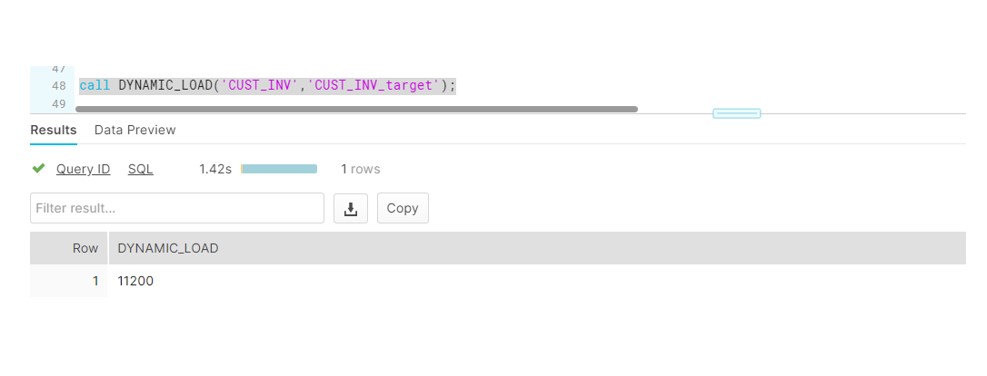
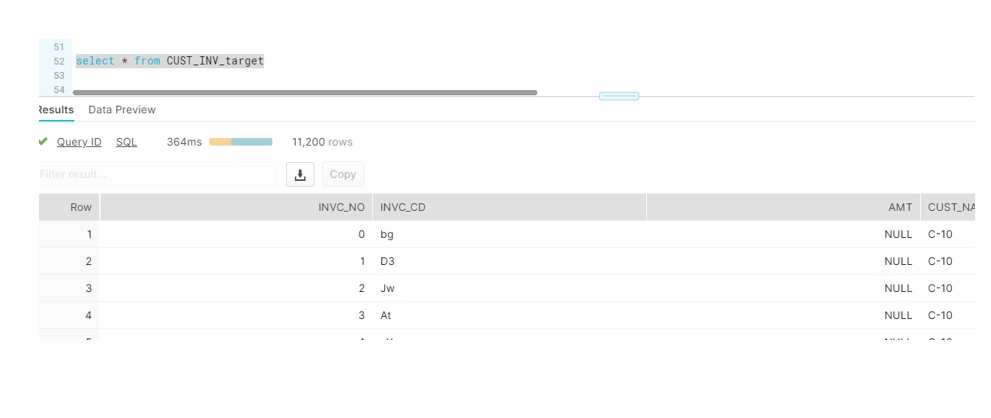
So for our scenario, we will test it on CUST_INV and CUST_INV_TARGET table. CUST_INV is the source table comprising 11k records, we will run Procedure which will merge the data into target table.
Before Procedure Run: