Consider a scenario, where we are getting multiple Invoice files from the Source system to the S3 bucket. However, there are few records which are common in all these files .As per the business need we are supposed to load only unique records into the staging table to avoid the data duplicity or redundancy.
Following two tables got created:
create or replace table S_INVOICE (CUST_NUM varchar(8) null, CUST_STAT varchar(255) null, CUST_BAL number(20) null, INV_NO varchar(10) null, INV_AMT number(10) null, CRID VARCHAR(4), SSN number(10) null, Phone number(10) null, Email varchar(255));
create or replace table S_INVOICE_TARGET (CUST_NUM varchar(8) null, CUST_STAT varchar(255) null, CUST_BAL number(20) null, INV_NO varchar(10) null, INV_AMT number(10) null, CRID VARCHAR(4), SSN number(10) null, Phone number(10) null, Email varchar(255));
There can be two approaches to deal with duplicity,
- Load the as-is data into the Invoice table and use DISTINCT while copying to S_INVOICE_TARGET.
- Eliminate the duplicate at first place while loading the data into S_INVOICE table.
We will talk about second approach to eliminate the data duplicity.
copy into S_INVOICE(CUST_NUM,CUST_STAT,CUST_BAL,INV_NO,INV_AMT,CRID,SSN,Phone,Email)
from (select distinct t.$1, t.$2 , t.$3, t.$4 , t.$5, t.$6 , t.$7, t.$8, t.$9 from @DEMO_DB.public.ext_csv_stage t)
pattern='Invoice.*.csv'
on_error = CONTINUE;
Above command will process all Invoice files and we are filtering the duplicate record initially at the time of loading into S_INVOICE table.
Query to verify:
select CUST_NUM,CUST_STAT,CUST_BAL,INV_NO,INV_AMT,CRID,SSN,Phone,Email,count(*) from s_invoice
group by CUST_NUM,CUST_STAT,CUST_BAL,INV_NO,INV_AMT,CRID,SSN,Phone,Email
having count(*) > 1
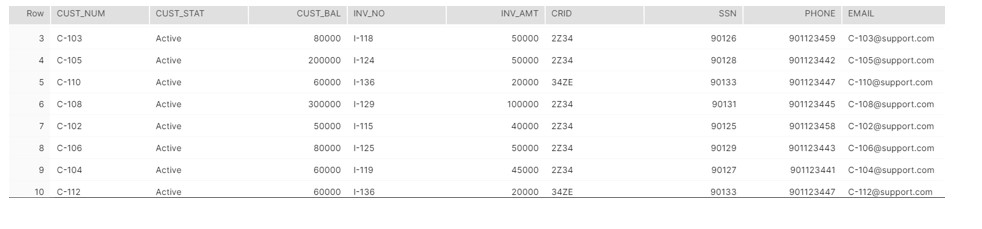
Now in addition to it we want to develop the DELTA process such that for next day run, if we get the same records along with new data, then Process should be able to load only the new records.
Major glitch here is that we don’t have any matching key defined on the table based on that we can identify whether the same records has been processed during previous run or not.
HASH
To handle such scenario we are using the HASH(*) function , HASH(*) returns a single value per row based on the column values.
So in below query
- First we have calculated the HASH(*) along with the ROW_NUMBER() analytical function
- If there is any new record in source table i.e. S_INVOICE ,hash return a new unique value
- Matches the HASH key of Source table with target table (generated on all columns) and if matches record gets ignore else we insert the data into the TARGET table.

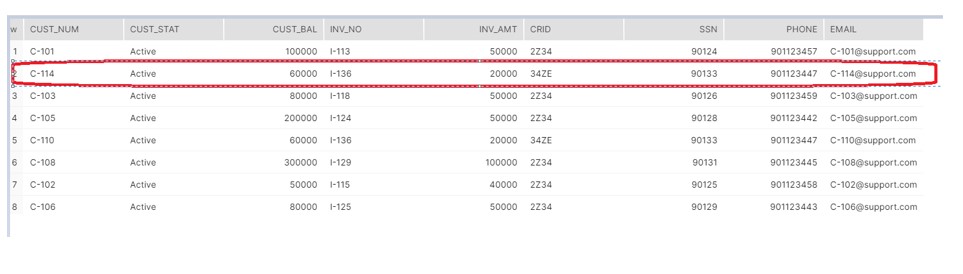
Now assume on next day we are getting a new record in the file lets say C-114 record along with the existing Invoice data which we processed previous day.
Execute the process in below sequence:
- Load file into S_INVOICE.
- Run the MERGE statement, which will insert only C-114 customer record.