df.head(0).to_sql: During the last post i.e. Handle to_Sql Dataframe Error ,we discussed the limitations of df.to_Sql method during ingestion of large dataset. Though we have resolved the issue by segregating this dataframe into batches of 10K each.in addition to it we will talk about one more limitation of df.to_sql method. It sends one line of values per row in the data frame which is fine for smaller Datasets. The same method errored out or causes the memory issue if running big resources aka huge dataset. When you try to write a large pandas Data Frame with the to_sql method it converts the entire data frame into a list of values. During this transformation more RAM is utilizes than the original Data Frame. Moreover old Data Frame still remains present in RAM.
We can use chunksize argument inside the to_sql method but again it has it own limitations:
Using chunksize does not necessarily fetches the data from the database into python in chunks. By default it will fetch all data into memory at once, and only returns the data in chunks (so the conversion to a data frame happens in chunks).
So what if you have a large dataset and you want to create the table at run time as well. Also populates this table with dataset without struggling the memory issues.
df.head(0).to_sql
Once the empty table gets created, we will leverage the functionality of Snowflake COPY command to perform the BULK load which will insert the data in one go instead of Row-By-Row as in case of to_sql method.
import os
import pandas as pd
import sqlalchemy
import snowflake.connector
from snowflake.sqlalchemy import URL
from sqlalchemy import create_engine
engine = create_engine(URL(
account='dj03808.us-east-2.aws',
user='sachinsnowpro',
password='Thakurji@2020',
warehouse='TEST',
database='DEMO_DB',
schema='PUBLIC',
role='ACCOUNTADMIN'
))
connection = engine.connect().execution_options(stream_results=True)
sql = "select * from CUSTOMER_INVOICE"
df = pd.read_sql_query(sql, con=connection)
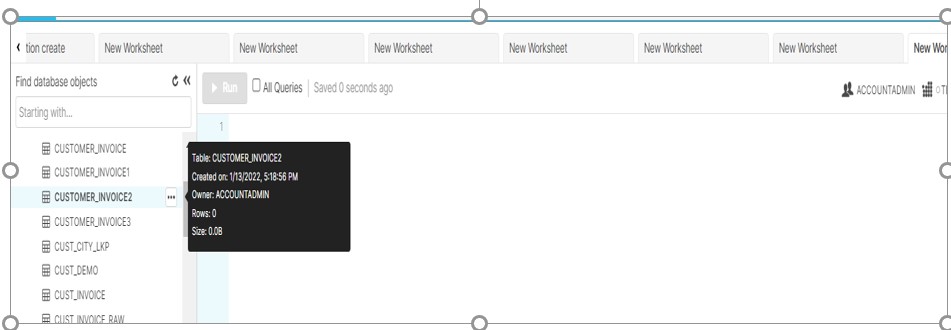
df.head(0).to_sql('CUSTOMER_INVOICE2', con=connection, if_exists="replace", index=False)
//This will create an empty table CUSTOMER_INVOICE2.
// Below is the way to load the CUSTOMER_INVOICE2 using COPY Command.
file_name = "customer_invoice.csv"
file_path = os.path.abspath(file_name)
print(file_path)
df.to_csv(file_path, index=False, header=False)
with engine.connect() as con:
con.execute(f"put file://{file_path}* @%CUSTOMER_INVOICE2")
con.execute(f"copy into CUSTOMER_INVOICE2")