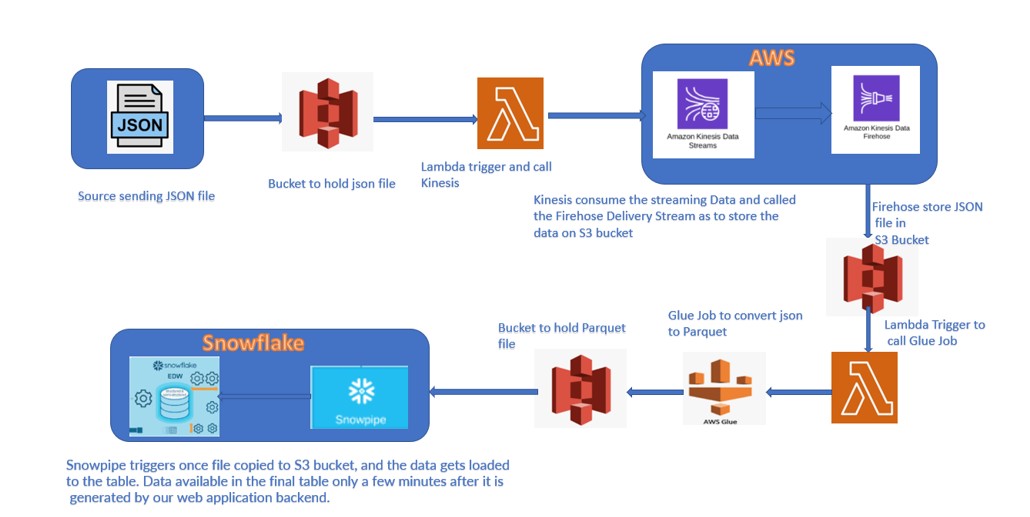
During the last post we discussed about the several components used in the data pipeline flow. We saw how the different services merged into one flow and finally ingested data into snowflake. Me and my colleague Mehani Hakim worked on the technical aspects of this data Pipeline flow . Here we will see implementation part along with the Code we have used in the process.
Following Component has been used in this pipeline:
Source bucket: salessnow
Bucket where source json file will be uploaded
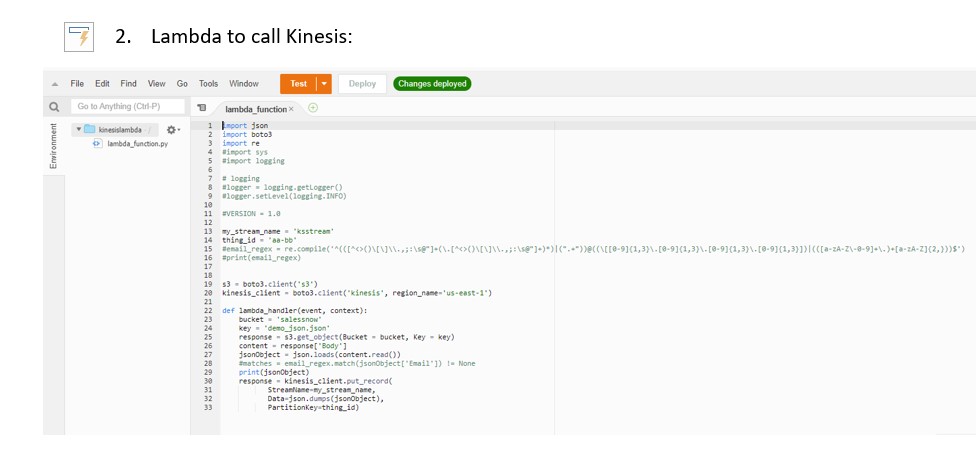
Lambda function: kinesislambda
Lambda to read JSON file from S3 bucket and trigger the Kinesis data stream
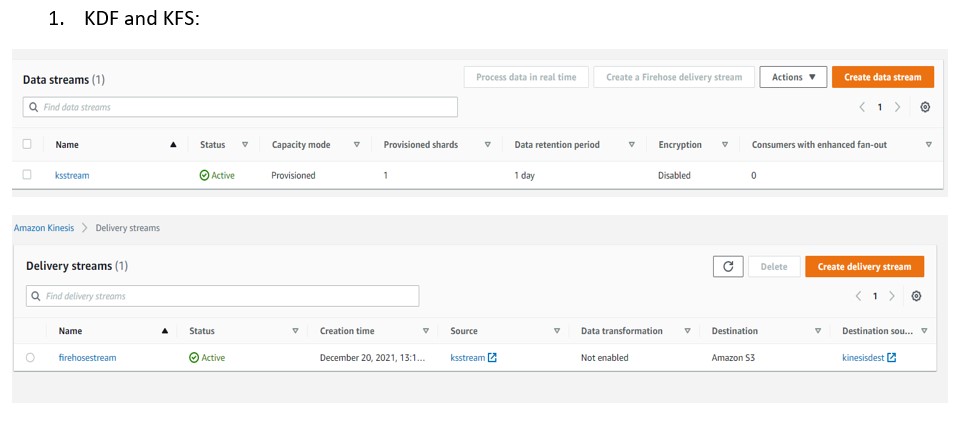
Kinesis Stream: ksstream
Stream to capture the JSON file
Kinesis Firehose: firehosestream
Receive input from Kinesis stream and store output to kinesisdest bucket
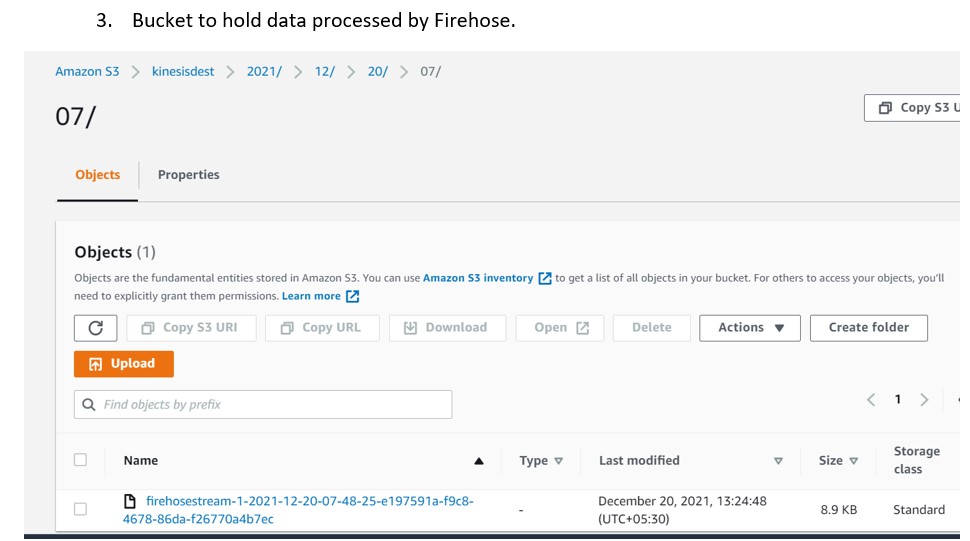
Firehose Destination Bucket : kinesisdest
Bucket to store the file by Firehose
Lambda: kinesistoglue
Lambda triggeres once file uploaded to kinesisdest bucket
Call the Glue job whcih will convert JSON to Parque
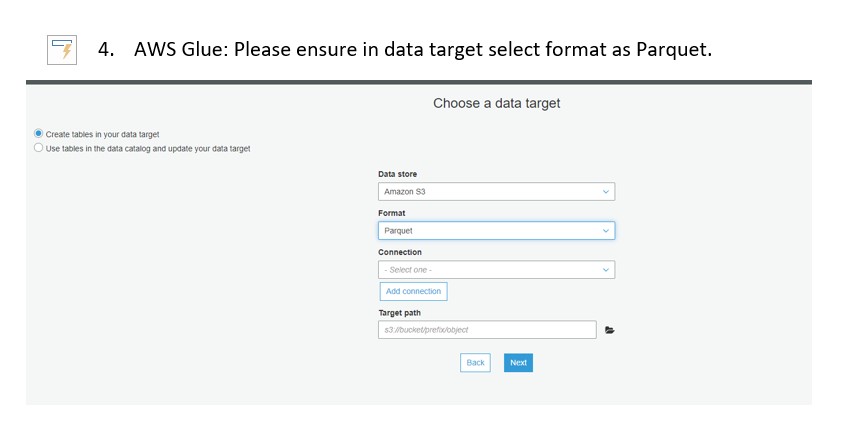
GlueJob: JSONtoPARQUET
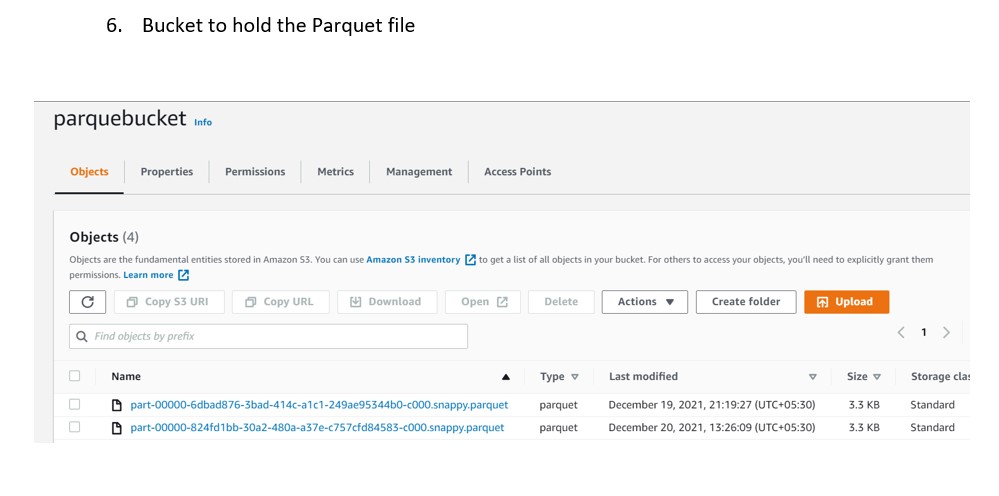
Job to convert JSON to Parquet and store file to bucket i.e. parquebucket
snowpipe: kinesispipe
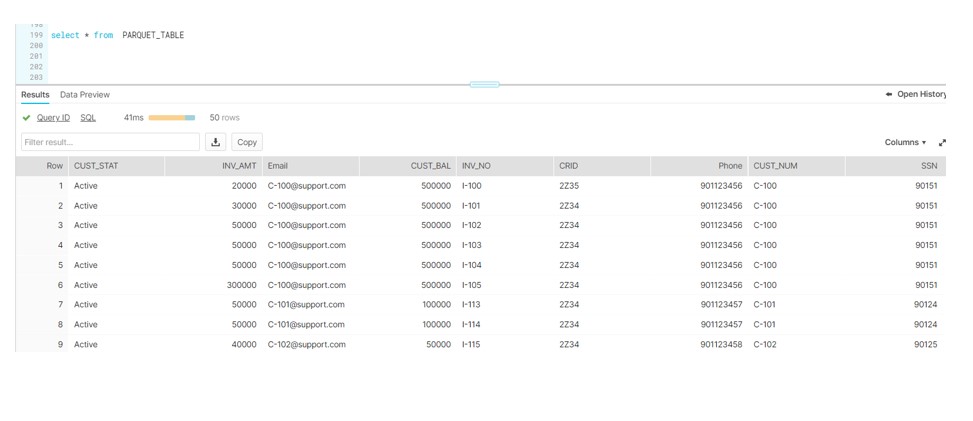
Parquet Table: PARQUET_TABLE
5. Glue Script:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "kinesis_db", table_name = "demo_json_json", transformation_ctx = "datasource0")
datasink4 = glueContext.write_dynamic_frame.from_options(frame = datasource0, connection_type = "s3", connection_options = {"path": "s3://parquebucket"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
7. Lambda : To Call Glue Service
import json
import boto3
def lambda_handler(event, context):
s3_client = boto3.client("glue");
s3_client.start_job_run(JobName="JSONtoPARQUET")
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
8. Snowflake: Finally see below snowflake commands to load data into snowflake. Moreover, Schema detection feature is used to generate the Parquet structure at run time instead of creating the table manually.