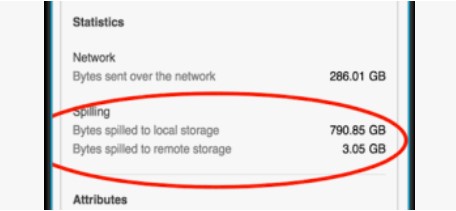
Consider the scenario when you executed the query and after some time you want to analyze the Query via Query Profile. And sometimes the information shows in query profile is Spilling (Bytes spilled to local/remote storage). So the Question comes : What is disk spilling?
When Snowflake warehouse cannot fit an operation in memory, it starts spilling (storing) data first to the local disk of a warehouse node, If the local disk space is not suffice, the spill data is then save to remote disks. These operations are slower than memory access and can slow down query execution a lot.
As this means extra IO operations, any query that requires spilling will take longer than a similar query running on similar data that is capable to fit the operations in memory.
To see if a query is spilling to disk, look at the right-hand side of the Profile tab:
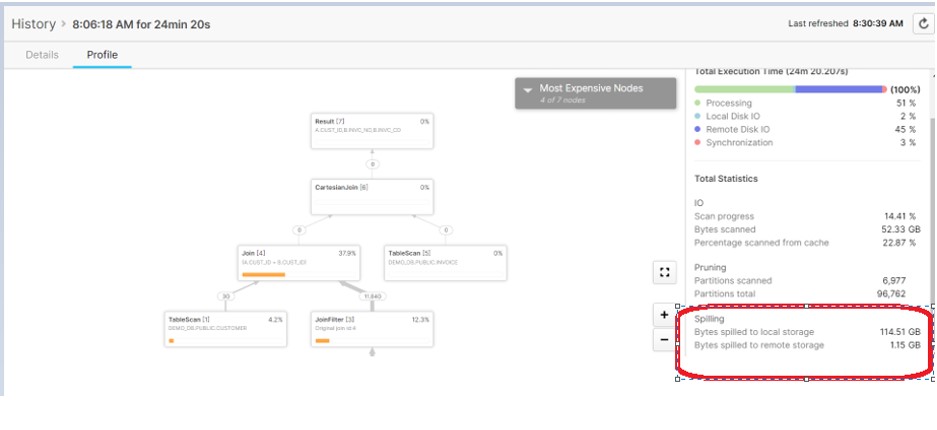
As per the above screenshot we have executed the query and it has started spilling the data to Local Disk. Once the DISK was not capable enough to store the results it started to save the output on remote storage i.e. Cloud provider space.
A query spilling bytes to the remote storage will notice even further performance degradation.
Solution Approach:
Solution Approach:
Though spilling can’t always be avoided in case we are processing large batch of data. But it can be decreased by in below way:
- Reducing the amount of data processed: Data clustering is one of the approach on larger tables as it allows to read the appropriate subset of the data that is really require.
- Decreasing the number of parallel queries running in the warehouse: It may be the possibility that other heavily queries running at the same time are eating up the warehouse resources.
- Processing data in smaller batches.
- Using a larger warehouse : This increases the total available memory and parallelism.