
SNOWPIPE in CLONING: Recently got struck with a requirement where a PIPE was available in Source Database and we were supposed to CLONE this source DB to the new Database in same Account. At first glance the requirement seems very straightforward, and it can be achieve through a single command like CREATE DATABASE <<DB_NAME>> CLONE <<SRC_DB_NAME>>.
We executed the CLONE command and verify a CLONED DB along with the PIPE gets created successfully in the Account. Now as per the desire behavior, as soon as file gets upload to the S3 location , An S3 event notification informs Snowpipe via an SQS queue that files are ready to load. Snowpipe should copy the files into the target table on both Databases (Source as well CLONED DB)
To our surprise, after the successful CLONING, we saw following issues…
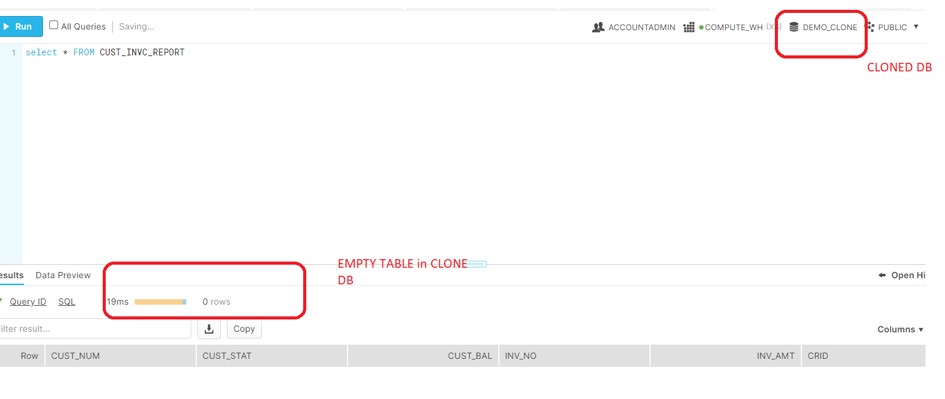
- Data gets loaded only in Source DB table; Cloned DB table was empty which should not be the case.
- After deep dive into the documentation, we came to know that CLONING the Database makes the PIPE in STOPPED State. Please see the PIPE status inside the CLONED DB.
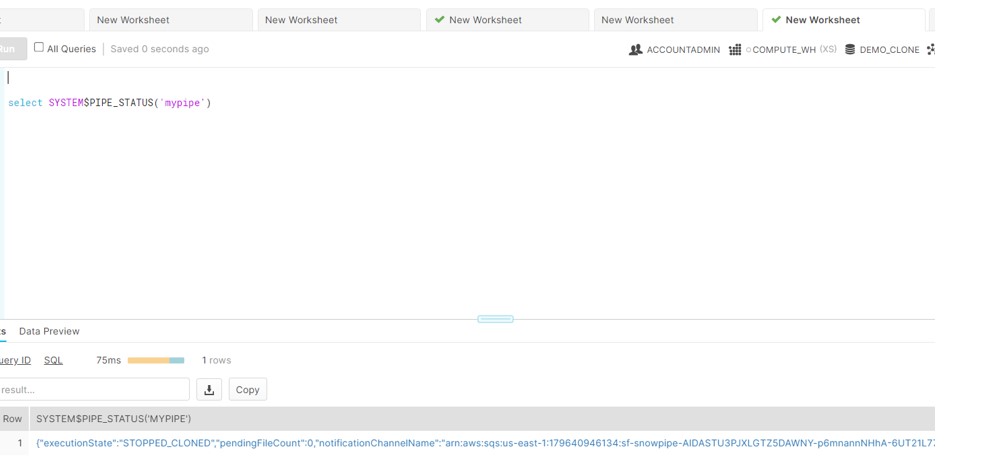
So to make PIPE running in the CLONE DB, we need to execute the below command:
ALTER PIPE mypipe SET PIPE_EXECUTION_PAUSED = FALSE
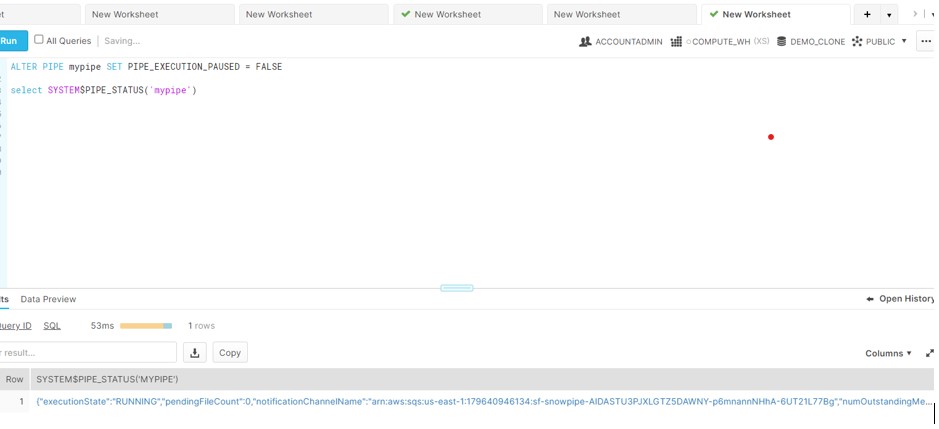
- Next issue, Duplicate records got loaded in the SOURCE Database table and the CLONED DB table was still empty.
- This issue routes us again to the Snowflake Documentation and found very critical information about the PIPES in CLONING database
PIPE Behavior in CLONING:
PIPE Behavior in CLONING:
When a data file creates in a stage location (e.g. S3 bucket), a copy of the notification is sent to to every pipe that matches the stage location. This results in the following behavior:
- If a table is fully qualified in the COPY statement in the pipe definition (in the form of db_name.schema_name.table_name or schema_name.table_name), then Snowpipe loads duplicate data into the source table (i.e. the database.schema.table in the COPY statement) for each pipe.
- If a table is not fully qualified in the pipe definition, then Snowpipe loads the data into the same table (e.g. mytable) in the source and cloned databases/schemas.
So as per the first point, we verified the definition of PIPE in our SOURCE DB and found the below code:
create or replace pipe demo_db.public.mypipe auto_ingest=true as
copy into DEMO_DB.PUBLIC.CUST_INVC_REPORT
from @demo_db.public.ext_csv_stage
on_error = CONTINUE;
This clearly shows PIPE definition refers the fully qualify name of TABLE which is pointing to the source DB and the same has been clone to the CLONED Database. Hence when the file gets upload to the S3 location a copy of the notification is send to every pipe in both DB and ingest the data in SOURCE DB two times.
So ,In order to populate the TABLE inside the CLONED DB we should follow the above mentioned second point (2) and which requires the change in PIPE definition and we have modified the CODE in below way:
create or replace pipe demo_db.public.mypipe auto_ingest=true as
copy into CUST_INVC_REPORT
from @demo_db.public.ext_csv_stage
on_error = CONTINUE;
create or replace database DEMO_CLONE clone DEMO_DB;
ALTER PIPE mypipe SET PIPE_EXECUTION_PAUSED = FALSE
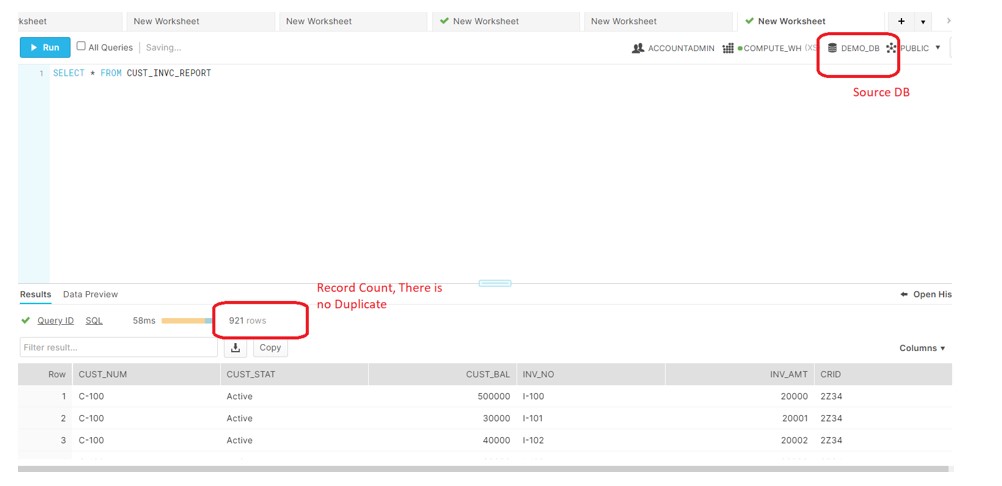
After the PIPE creation,we have uploaded the file to S3 bucket and verified the recors in SOURCE and CLONED DB.
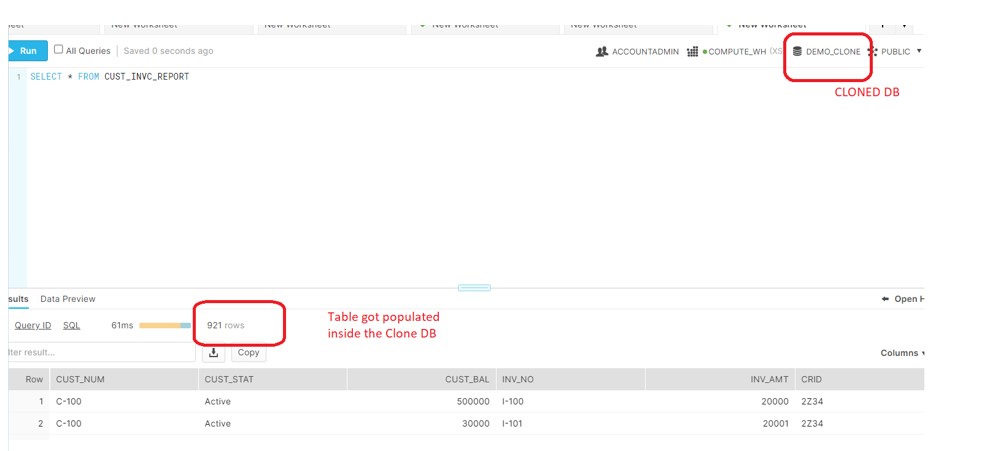
Please be cautious during the CLONING of DB o schema specially when there SNOWPIPE used in CLONE .












