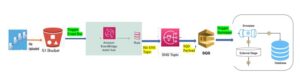
Snowflake has become a phenomenon across industries with its focus on analytical data storage and impressive performance. There is common misconception that scaling up the bigger warehouse will improve query performance, but this is not a true case always. In reality, there are certain factors which determines the performance of your application or queries . It depends upon the ingestion, transformation, or end-user queries. Please note most effective solutions are based upon a design approach rather than pure query tuning.
Tips:
- Never disable Cloud Service Result Cache layer as this is the layer holds the result of your query. If users executes same query , instead of routing to VW and Storage get output from Result Cache layer itself. Here no computation cost is involves.
- Dedicated warehouse for Querying: Snowflake automatically caches data in the Virtual Warehouse (local disk cache). Place users querying the same data/tables on the same virtual warehouse. This maximizes the chances that data retrieve to the cache by one user will also be use by others. No Storage layer gets involve.
-
Avoid Scanning Files: Before copying data, Snowflake checks the file has not already been loaded by using the mdm checksum approach, and this leads to the check of entire stage files. Easiest way to maximize load performance by partitioning staged data files to avoid scanning terabytes of files that have already been loaded.
-- Most Flexible method: Limit within directory
copy into sales_table
from @landing_data/sales/transactions/2020/05
pattern='.*[.]csv';
-- Fastest method: A named file
copy into sales_table
from @landing_data/sales/transactions/2020/05/sales_050.csv;
Split:
4. Clustering the table: Partition the large tabes:A clustering key is a subset of columns in a table or an expression that are explicitly used to co-locate the data in the table in the same micro-partition.
-
- Clustering keys does not intend for all tables. The size of a table, as well as the query performance for the table.
Apart from the above, please also understand why the performance of a table will deteriorate over a period of time. Snowflake physically stores data in 16MB micro-partitions which are immutable. So, when you are constantly inserting/updating records in the tables, those micro-partitions are gets recreate. When they get recreated, it is not possible for Snowflake to ensure that the records are clustered together. Hence, the clustering deteriorates over a period of time. If you create clustering key, auto clustering is turned on and Snowflake automatically reclusters the records based on an algorithm. It does not cluster the entire table at the same time, it does it gradually.
- Clustering keys does not intend for all tables. The size of a table, as well as the query performance for the table.
5. Files need to be Split on Snowflake: Split your data into multiple small files than one large file, to make use of all the nodes in Cluster. Loading a large single file will make only one node at action and other nodes are ignore even if we have larger warehouse.
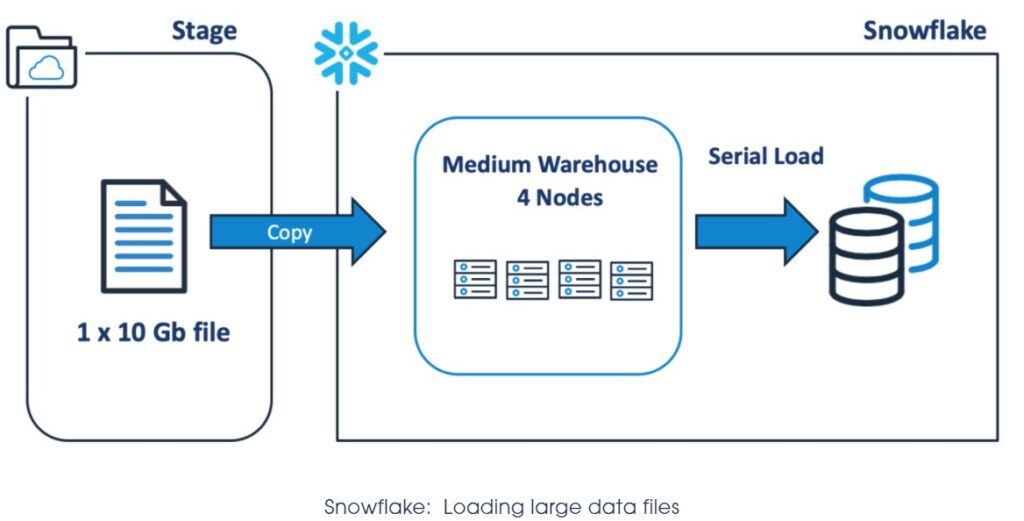
The above COPY statement will open the 10Gb data file and sequentially load the data using a single thread on one node, leaving the remaining servers idle. Unless you have other parallel loads using the same virtual warehouse, the above solution is also remarkably inefficient, as you will pay for four servers, while using only one.
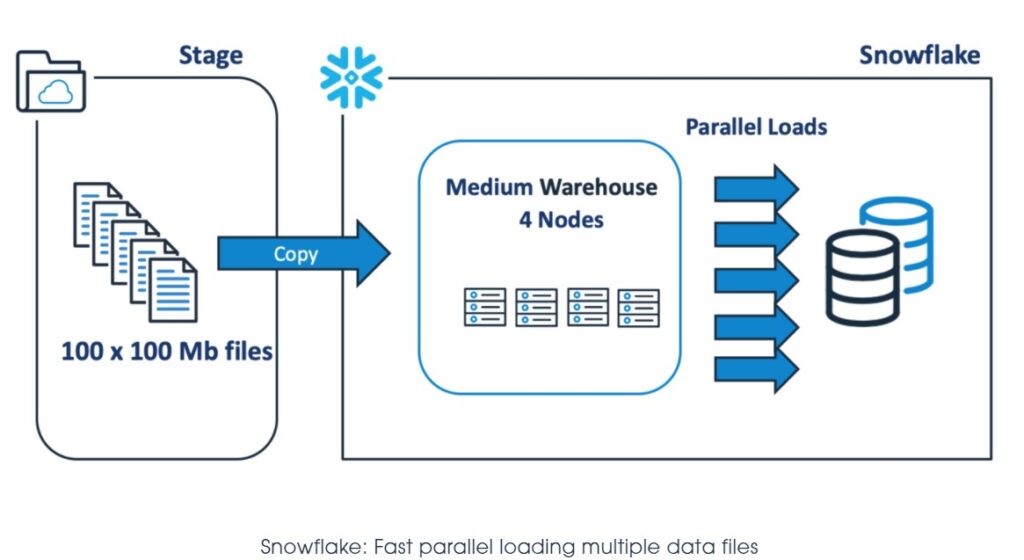
The diagram below illustrates a much better approach, which involves breaking up the single 10Gb file into 100 x 100Mb files to make use of Snowflake’s automatic parallel execution.
Common Tips:
6. Materialized View on Eternal tables: Querying data stored external to the database is likely to be slower than querying native database tables; however, materialized views based on external tables can improve query performance.
7. SELECT Few Attributes: Always use Limit Clause with Select * from table, Because Virtual warehouse pulls the complete data from storage layer and execute the query and store all the results into Result Cache. This way you charged for computation even we use SELECT * to know only type of data.
8. Warehouse Resizing Improves Performance: Resizing a warehouse generally improves query performance, particularly for larger, more complex queries. It can also help reduce the queuing that occurs if a warehouse does not have enough servers to process all the queries that are submitted concurrently
Resizing a running warehouse does not impact queries that are already being processed by the warehouse; the additional servers are only use for queued and new queries.
9. Date/Time Data Types for Columns:When defining columns to contain dates or timestamps, choose a date or timestamp data type rather than a character data type. Snowflake stores DATE and TIMESTAMP data more efficiently than VARCHAR, resulting in better query performance.
Spill:
10. Data is spilling to the remote disk: The amount of memory available for the servers used to execute the operation might not be sufficient to hold intermediate results. As a result, the query processing engine will start spilling the data to local disk. If the local disk space is not enough, the spilled data is then save to remote disks.
This spilling can have a profound effect on query performance (especially if remote disk is used for spilling).
To alleviate this, we recommend:
- Using a larger warehouse (effectively increasing the available memory/local disk space for the operation), and/or
- Processing data in smaller batches.