
In one of the project, we were required to process large volume of data. In typical scenario we split huge file into the chunks at our on-premise before uploading them to the S3 bucket. Later on use the AWS CLI to copy these files of data from on-premise infrastructure to S3 buckets .
But consider the scenario, If the data is already present on the S3 bucket (say complete huge file )then we need to download it of course at our local premise and then split this huge file and upload these chunks to the S3 location. But this is not a viable solution and not ideal when clients deliver to your S3 buckets a few GBs.
The cp command initiates a copy operation to or from Amazon S3. aws s3 cp will copy all files, even if they already exist in the destination area. It also will not delete files from your destination if they are deleted from the source.
We have tested the functionality on Linux version where we executed a shell script which has splitted the large files into the smaller chunks based on the number of lines in file.
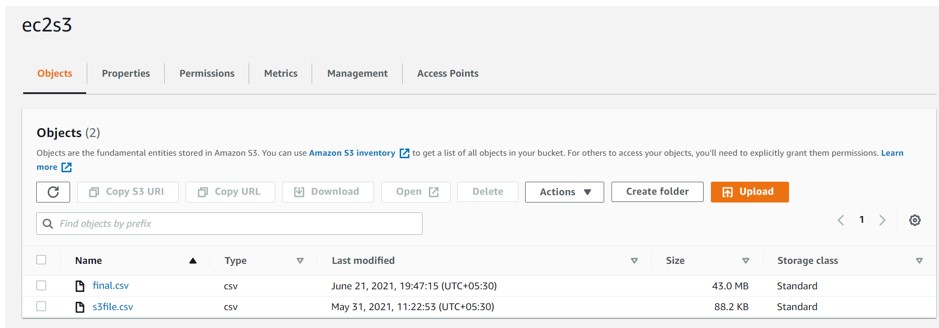
Please see the below screenshot from S3 location where we have CSV file: Here we will be trying to split the final.csv file into smaller chunks of 1000 lines each.
EC2 and Shell Script:
Login to the EC2 machine and create the shell script (Split_huge_file.sh) with below content.
Split_huge_file.sh:
S3_BUCKET=ec2s3
FILENAME=final.csv
INFILE=s3://”${S3_BUCKET}”/”${FILENAME}”
OUTFILE=s3://”${S3_BUCKET}”/”${FILENAME%%.*}”
echo $S3_BUCKET, $FILENAME, $INFILE, $OUTFILE
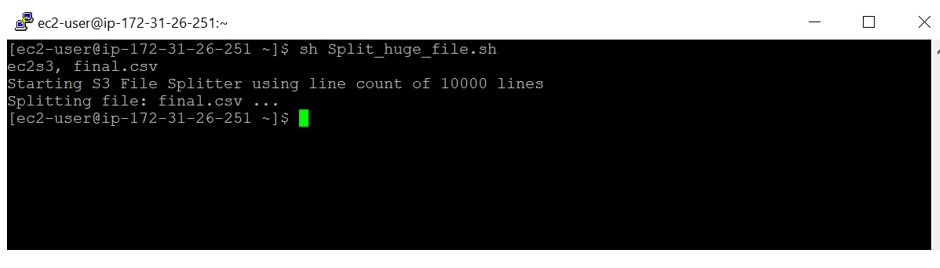
echo “Starting S3 File Splitter using line count of 10000 lines”
FILES=($(aws s3 cp “${INFILE}” – | split -d -l 10000 –filter “aws s3 cp – \”${OUTFILE}_\$FILE.csv\” | echo \”\$FILE.csv\””))
Run the Shell Script:
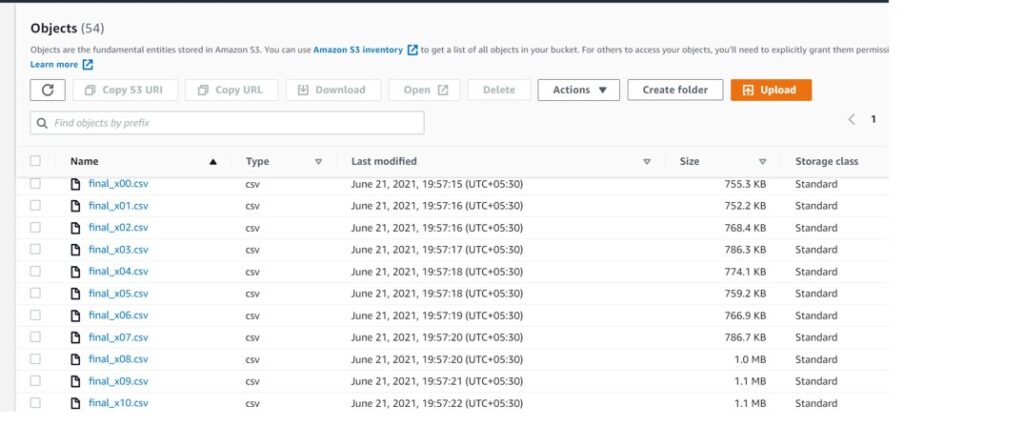
After running the script, File got splitted into the multiple files with 10000 lines per file.
Later on we can use the COPY command
copy into final_table from @<<S3 External Area>>
pattern=’.*[.]csv’;







