Cache is a type of memory that is used to increase the speed of data access. The process of storing and accessing data from a cache is known as caching. Snowflake architecture includes caching layer to help speed your queries. This article provides an overview of the techniques used, and some best practice tips on how to maximize system performance using caching.
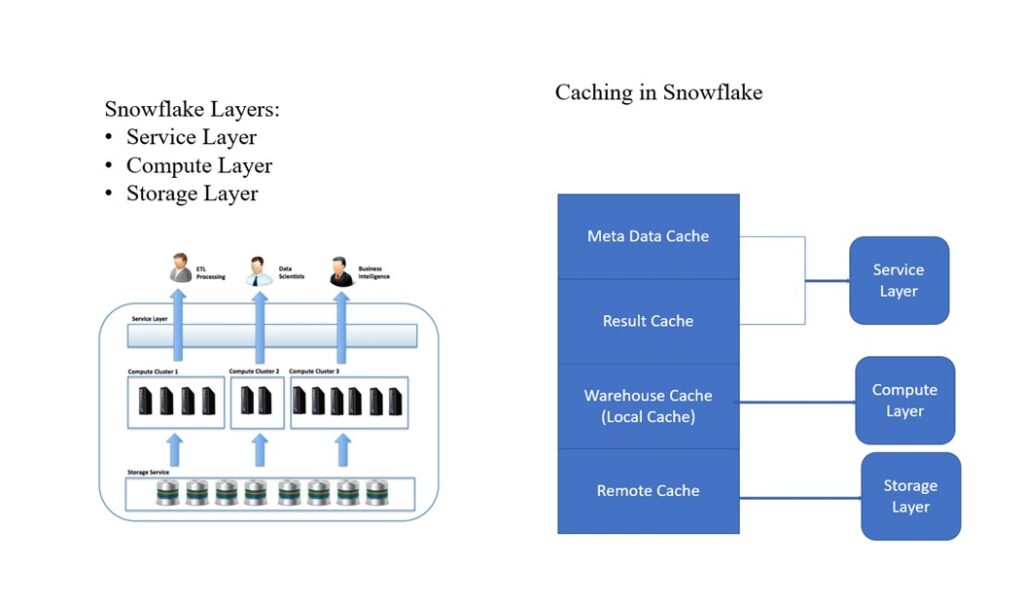
Below is the introduction of different Caching layer in Snowflake:
Metadata Caching:
This is not really a Cache. In other words, It is a service provide by Snowflake. Therefore,Snowflake automatically collects and manages metadata about tables and micro-partitions
- Row Count
- Table Size in Bytes
- File references and table versions
For Micro-Partitions, Snowflake stores:
- The range of values (MIN/MAX values)
- Number of distinct values
- NULL Count
- Some operations are metadata alone and require no compute resources to complete, like the query below
SELECT MIN(L_SHIP_DATE), MAX(L_SHIP_DATE) FROM LINE_ITEM; Query Results Caching:
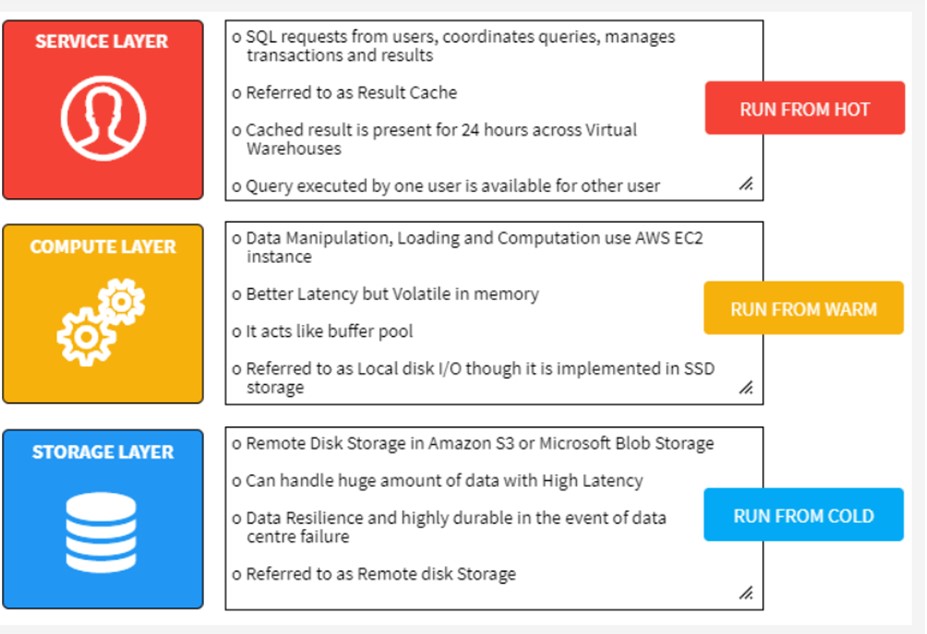
The Results cache holds the results of every query executed in the past 24 hours. These are available across virtual warehouses, In other words, query results return to one user is available to other user like who executes the same query. However, provided the underlying data has not changed.
Virtual Warehouse Local Disk Caching:
Therefore, whenever data is needed for a given query it’s retrieved from the Remote Disk storage, and cached in SSD and memory of the Virtual Warehouse. This data will remain until the virtual warehouse is active. When there is a subsequent query fired an if it requires the same data files as previous query, the virtual warehouse might choose to reuse the datafile instead of pulling it again from the Remote disk
Remote Disk: Which holds the long term storage. In addition, this level is responsible for data resilience, which in the case of Amazon Web Services, means 99.999999999% durability. Moreover, even in the event of an entire data center failure.
To understand Caching Flow, please Click here.