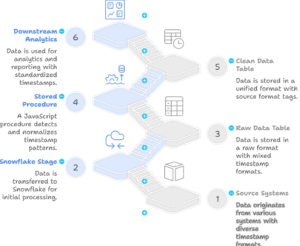
In fast-paced data environments, schemas evolve frequently to meet new business requirements. One of the common challenges in managing database views is ensuring they stay in sync with the underlying table schema. For example, when new columns are added to a table, the corresponding view might not automatically reflect these changes, leading to errors or incomplete data in downstream processes.
In this blog, I’ll demonstrate how to automate the process of refreshing views in Snowflake when the table schema changes. Using a stored procedure, we can ensure that views remain aligned with the latest table definitions, avoiding manual intervention.
The Real-Time Scenario
Imagine a retail company that stores sales data in a table (CUST_INVC). Analysts use a view (CUST_INVC_VW) built on top of this table to generate reports. Whenever a new column is added to CUST_INVC (e.g., Phone or EMail), the view becomes outdated. This can disrupt reporting and delay business insights.
To solve this, we’ve developed a stored procedure that:
- Compares the table’s schema with the view’s schema.
- Identifies any new columns added to the table.
- Refreshes the view to include all the latest columns from the table.
Technical:
Table CUST_INVC created with ENABLE_SCHEMA_EVOLUTION = TRUE and load the data on day1 with 7 cols in feed file.
create or replace file format schema_evol_fmt
type = 'csv'
compression = 'auto'
field_delimiter = ','
parse_header = True
record_delimiter = '\n'
ERROR_ON_COLUMN_COUNT_MISMATCH = false;
create or replace stage demo_db.public.evolution file_format = demo_db.public.schema_evol_fmt;
CREATE OR REPLACE TABLE CUST_INVC
USING TEMPLATE (
SELECT ARRAY_AGG(object_construct(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@evolution/Schema_Evol_day1.csv',
FILE_FORMAT=>'schema_evol_fmt'
)
));
ALTER TABLE CUST_INVC SET ENABLE_SCHEMA_EVOLUTION = TRUE;
copy into CUST_INVC
from @demo_db.public.evolution/Schema_Evol_day1.csv
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;

Next day, we received feed file with 2 new fields i.e. PHONE and EMAIL. Due to Schema evolution our Table got modify automatically and added these two new cols.

Because VIEW is till holding the older definition while the table definition has been changed to 9 cols. So if we query the VIEW Columns we see still 7 columns are there.

Here’s the Snowflake stored procedure that handles the view refresh:


Execute the stored procedure:
How It Works
How it works:
- Retrieve the Current Schema:
The procedure retrieves the column definitions of the table and the view using the INFORMATION_SCHEMA.COLUMNS table. - Identify New Columns:
It compares the columns in the table against the columns in the view to find any new additions. - Update the View:
If new columns are detected, the procedure recreates the view using the latest table schema. - Feedback:
It returns a success message, listing the newly added columns
Now able to execute query on the view:

Conclusion
This stored procedure exemplifies how Snowflake’s flexibility and JavaScript support can automate routine tasks in a data ecosystem. By implementing such solutions, you can save time, ensure data consistency, and focus on delivering business insights.