In modern data architectures, businesses rely on automated pipelines to ingest, transform, and analyze data efficiently. Automating CSV & Parquet File Ingestion from S3 to Snowflake becomes crucial when customers place different file types (such as CSV and Parquet) in a single S3 bucket. This scenario demands a seamless, automated mechanism to detect, process, and load these files into Snowflake without manual intervention.
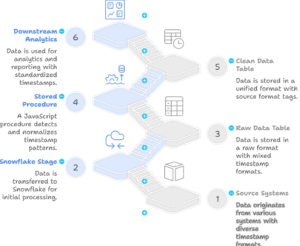
This blog explores a stored procedure in Snowflake that dynamically detects and processes CSV and Parquet files placed in an S3 bucket. The procedure leverages Snowflake’s INFER_SCHEMA function to create tables on the fly and uses COPY INTO to load data, ensuring a fully automated workflow.
Problem Statement
Problem Statement
A customer is placing CSV and Parquet files in the same S3 bucket and folder. Since the file format is unknown beforehand, a solution is required to:
- Automatically detect and process all files in the S3 location.
- Dynamically create tables based on the schema of the incoming files.
- Load data into the respective tables without requiring manual intervention.
- Handle multiple files in a single execution and log processed files.
We designed a Snowflake stored procedure to list the files in the S3 bucket, determine the format (CSV or Parquet), infer the schema, create tables dynamically, and load data accordingly.
- Below are the files available in AWS:

- No tables in Snowflake: These files needs to be ingested into INVOICE and PARQUET Table respectively. Currently we don’t have any such table in our database. Process will create these tables in the SP and ingest the data.
- Stored Procedure implementation:


- How It Works
-
List Files in S3 Bucket:
- Uses
LIST @demo_db.public.collection_stage/POCto retrieve all file names.
- Uses
-
Iterate Over Each File:
- Extracts the file name and extension (CSV or Parquet).
-
For CSV Files:
- Creates a table using INFER_SCHEMA (if not already existing).
- Loads data into the table using COPY INTO.
-
For Parquet Files:
- Creates a table using INFER_SCHEMA.
- Loads data with MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE.
-
Logs Processed Files:
- The processed file names are stored in an array and returned as output.
- Call the Procedure:

- Data Validation in Table:

Conclusion
This solution eliminates manual effort in handling multiple file formats within a single S3 location. With Snowflake’s powerful capabilities like INFER_SCHEMA, COPY INTO, and JavaScript Stored Procedures, businesses can automate their data ingestion seamlessly.