
In this post, we’ll explore Schema Evolution in Snowflake, a crucial feature allowing seamless adaptation to changing data structures. While Parquet files were initially supported, Snowflake has extended this feature to CSV and JSON files as well. Modern data systems often append new columns to accommodate additional information, necessitating downstream tables to adjust accordingly. Data pipeline should be robust enough that it should read the multiple file structure at run time and ingest them in a same table.
Imagine a scenario where a source system continuously feeds Snowflake with evolving CSV data. The data’s structure frequently changes, with new columns or alterations introduced. Meeting this challenge requires the development of robust data pipelines capable of modifying table columns to align with the evolving source data schema. Snowflake latest feature Schema Detection came to the rescue, It automatically detecting the schema i.e. Schema Detection Automate in a set of staged structured data files and retrieving the column definitions.
Technical implementation:
Below is the structure of CSV file we receive from the source system on day1 in S3 bucket.
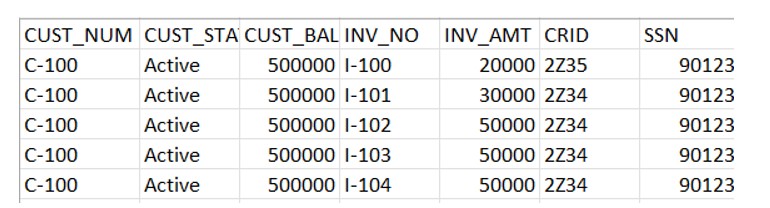
As we can see currently there are 7 columns in feed file. We will create the respective Stage and File formats to consume this file.
create or replace file format schema_evol_fmt
type = 'csv'
compression = 'auto'
field_delimiter = ','
parse_header = True
record_delimiter = '\n' ;
create or replace stage demo_db.public.ext_csv_stage
URL = 's3://srcbucketsachin/'
STORAGE_INTEGRATION = s3_int
file_format = demo_db.public.schema_evol_fmt;
CREATE OR REPLACE TABLE CUST_INVC
USING TEMPLATE (
SELECT ARRAY_AGG(object_construct(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@ext_csv_stage/Schema_Evol_day1.csv',
FILE_FORMAT=>'schema_evol_fmt'
)));
CUST_INVC table gets created with following structure.
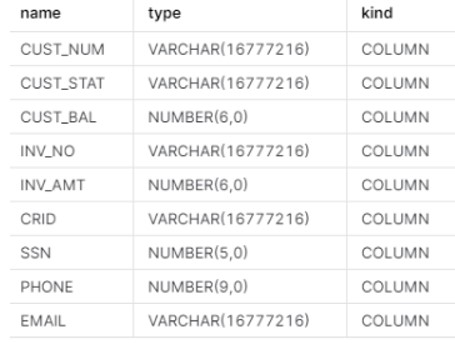
We will load the data into table using below command:
copy into CUST_INVC
from @demo_db.public.ext_csv_stage/Schema_Evol_day1.csv
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
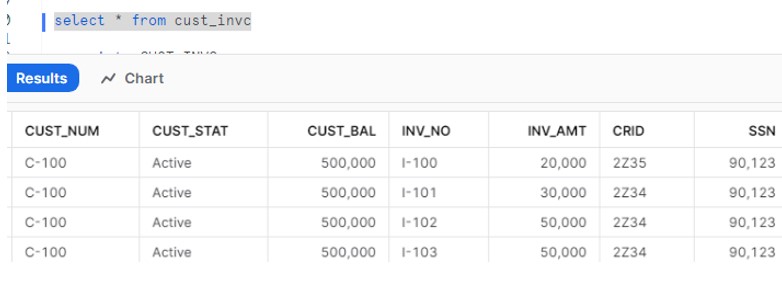
Verify the data in Snowflake:
Say next day we received the file from source with different architecture.

We can clearly see there are 9 columns in the feed file. Now our task is without dropping the existing table we need to load this data into same table.
So if we try to load the data using COPY command we get the below error.
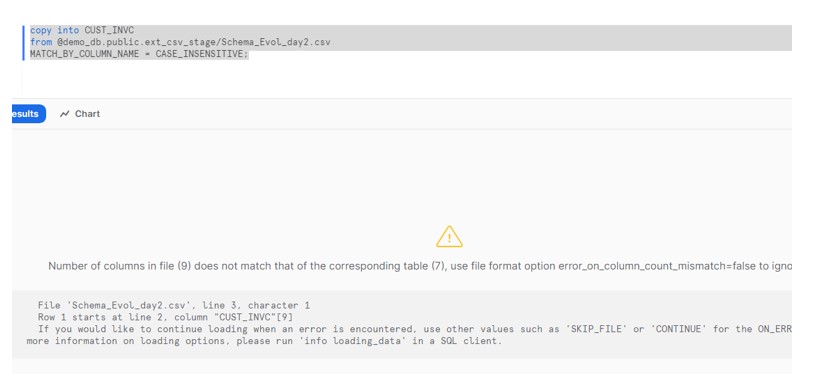
To resolve the issue we have modified the file format like below :
create or replace file format schema_evol_fmt
type = 'csv'
compression = 'auto'
field_delimiter = ','
parse_header = True
record_delimiter = '\n'
ERROR_ON_COLUMN_COUNT_MISMATCH = false
Now try to execute the COPY command and this time it gets completed successfully.
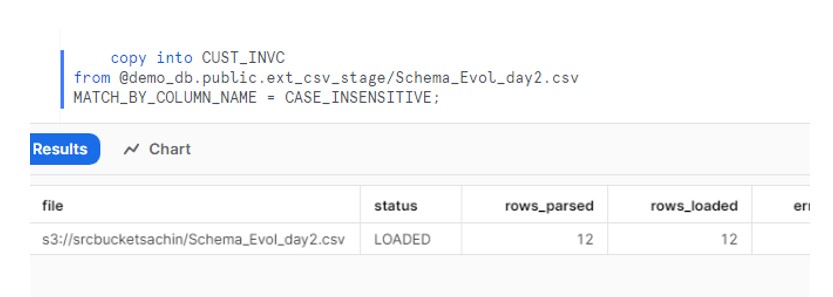
Verify the data in table.
Though the load got completed successfully but it has not created or populated the additional two columns.
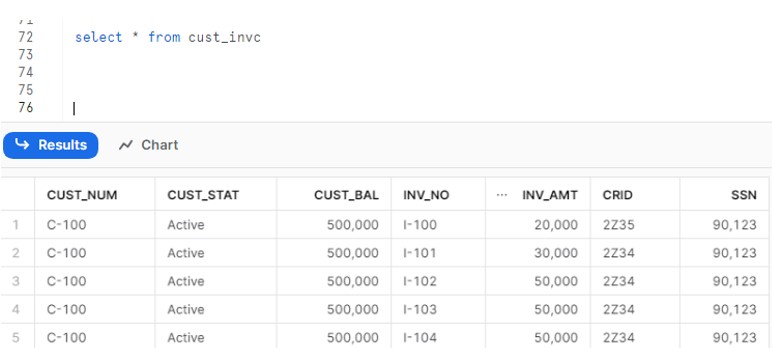
Question , How we should consume the feed file with all columns without dropping or deleting the existing table.
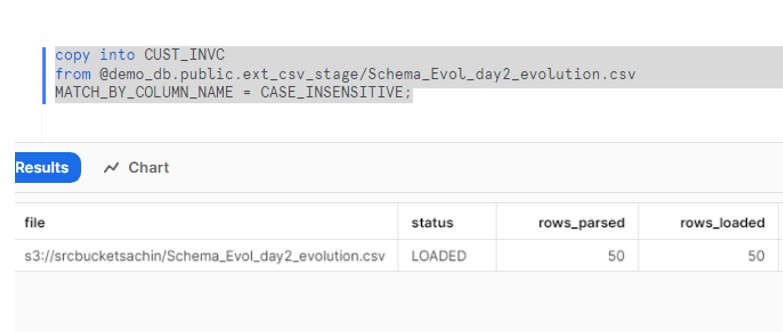
We need to enable SCHEMA Evolution property on the table.
ALTER TABLE CUST_INVC SET ENABLE_SCHEMA_EVOLUTION = TRUE;
Now try to load the file with 9 columns and verify the data.
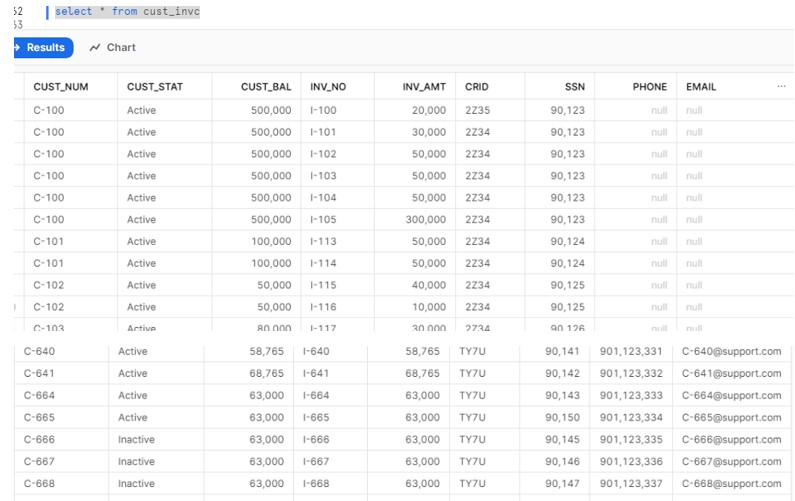
Verify the data and we can clearly see the table gets altered and include two new columns. So the existing previous day records having null value for these two columns. While the today’s record will have all the values in columns.













Hi Sachin, very nice. thank you for this explanation if you add some source columns.
One question if i may. If a column is deleted in the source (for example CUST_BAL) will it resolve this also?
Can you run this on the code or else i will test it in snowflake test db.
We actually see this happen sometimes.
Thanks again and have a great day. marco