Huge file vs Smaller Chunks: During this post we will discuss about the benefits of splitting the Huge file into small chunks. We have seen that ingesting the one huge file using COPY command takes unexpecting load time as compare to the smaller chunks. Also this leads to the Warehouse costing as processing the huge file makes warehouse available during that whole period. As per snowflake its recommended to spilt the file with size of 150 MB .
According to the snowflake documentation:
Split larger files into a greater number of smaller files to distribute the load among the compute resources in an active warehouse. The number of data files that are processed in parallel is determined by the amount of compute resources in a warehouse. We recommend splitting large files by line to avoid records that span chunks.
To prove the above pointers we will try to process one huge file and notice the Time taken by complete process. Later on we will spilt the same file into smaller ones based on the lines and try to process these files in parallel. Later on we will see the time variance for both process.
Say we have copied a big file (3.2 GB for demo) to our S3 bucket.
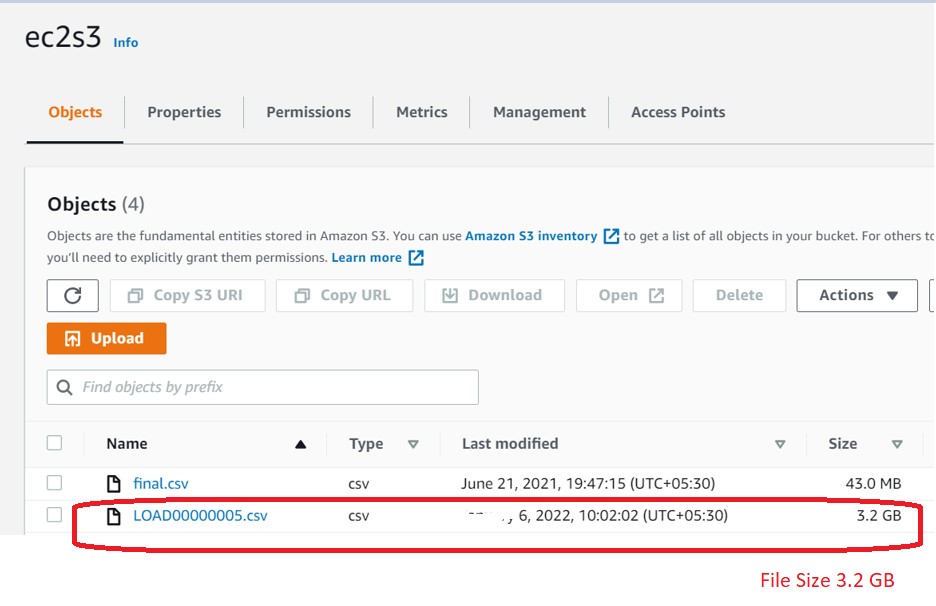
In Snowflake perform the following actions:
- Create Storage Integration.
- File Format.
- Create table and stages.
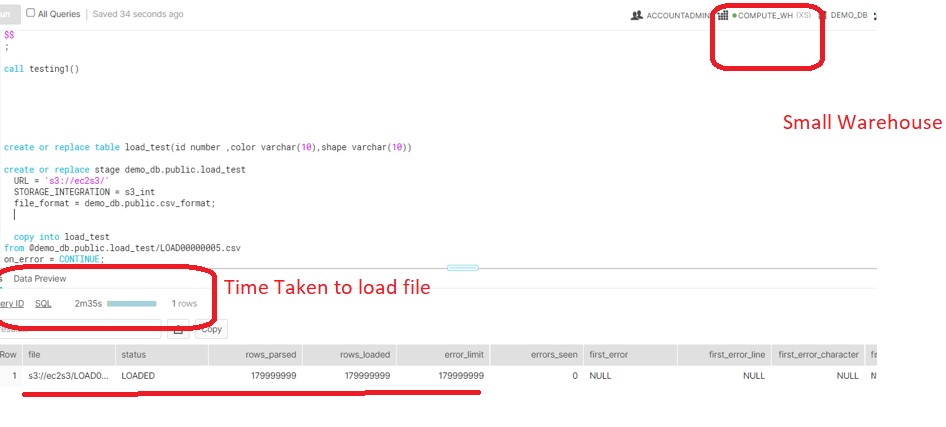
- Load the complete file into table using XS warehouse.
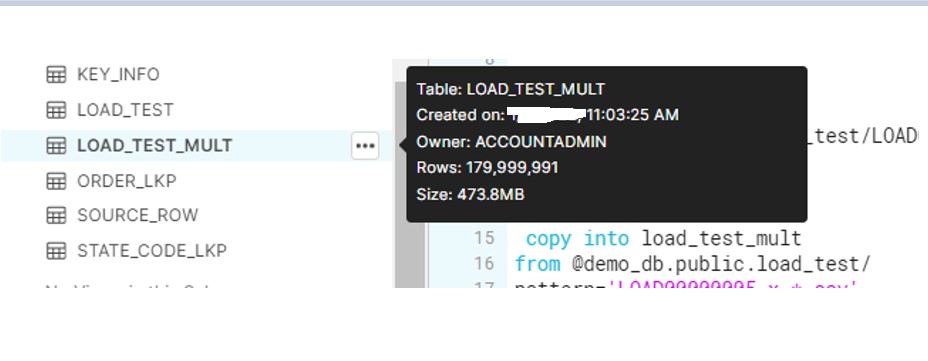
- File gets loaded to table in 2m35 sec.
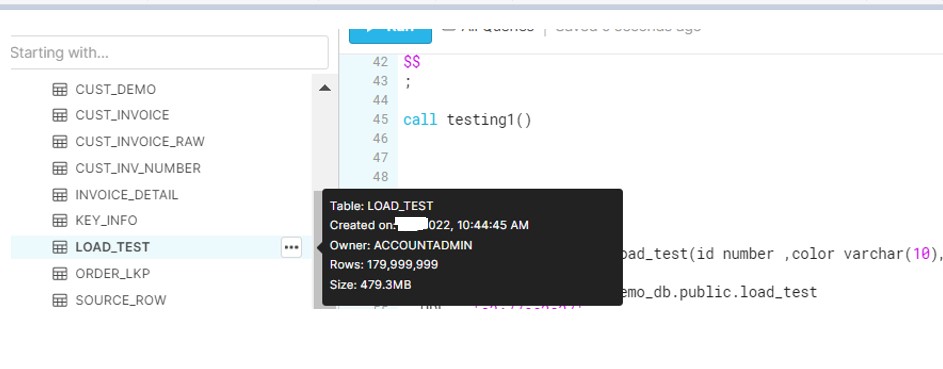
After the file load, check the size in Snowflake and it reduces to only 480 MB.
Split Files:
Now test the same on multiple files. We will see how Snowflake leverage the multiple CORES features and instead of occupying only one thread ,parallel thread would be used to copy the files at same time.
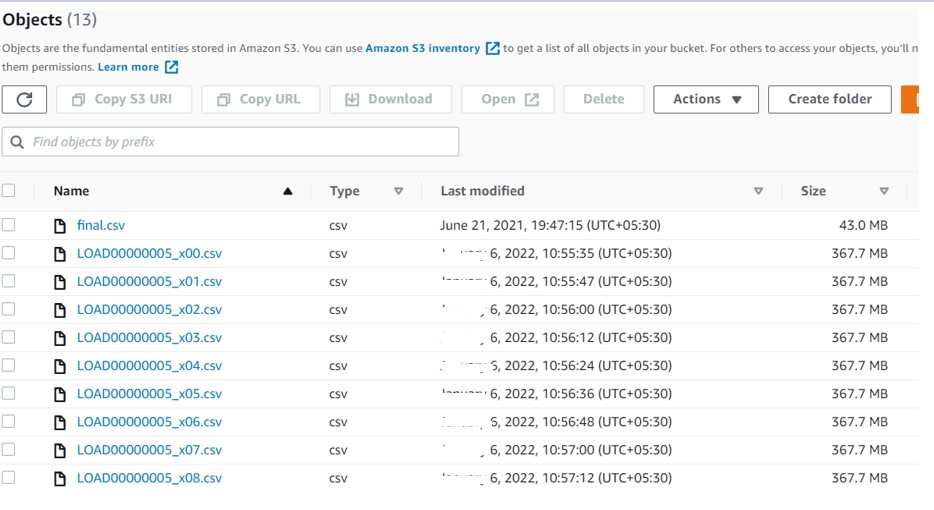
Now load these files in snowflake:
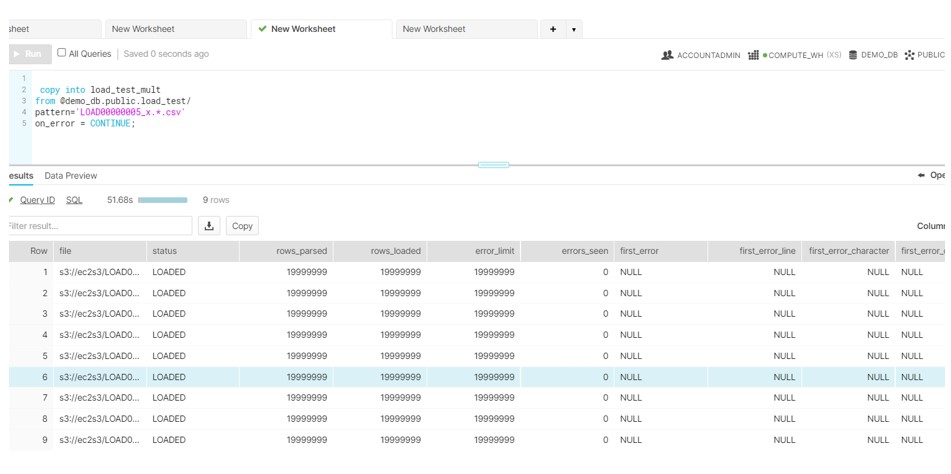
Here we see. All data gets load in only 51 sec. There is huge improvement compare to the loading the big file as against to split the file in smaller chunks.