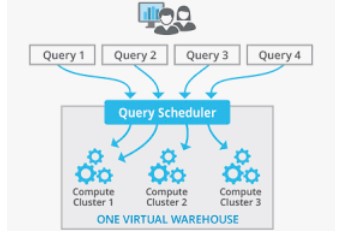
During this post we will discuss how Scale-out functionality works in Snowflake. Recently one of my colleague asked how and where we can verify the Multiclustering or Scale-out in Snowflake. Basically he wanted to create the scenario where the Multiclustering would be enable in his trial version. As we know, Scale out means adding warehouses to a multi-cluster warehouse. With multi-cluster warehouses, Snowflake supports allocating additional warehouses to make a larger pool of compute resources available. A multi-cluster warehouse is define by specifying the following properties: Maximum number of warehouses, greater than 1 (up to 10).
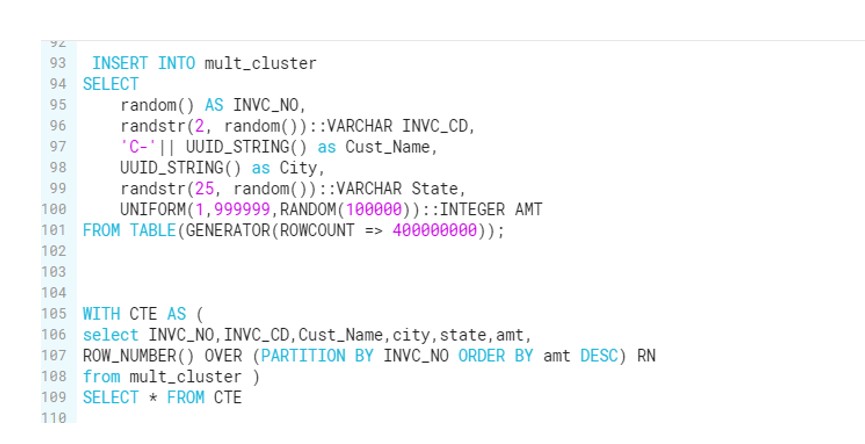
So to replicate the scenario, we would be requiring a table that holds a suffice amount of data. Also we would be requiring Query which will trigger from the multiple worksheets against this bulky table.
So we have created below table:
CREATE OR REPLACE TABLE mult_cluster (
INVC_NO BIGINT,
INVC_CD VARCHAR,
Cust_Name VARCHAR ,
City VARCHAR ,
State string ,
AMT INTEGER
);
We have inserted around 400M records in this table. Also develop the below query which will be running against this table:
WITH CTE AS (
select INVC_NO,INVC_CD,Cust_Name,city,state,amt,
ROW_NUMBER() OVER (PARTITION BY INVC_NO ORDER BY amt DESC) RN
from mult_cluster )
SELECT * FROM CTE;
For our use case we have considered XS warehouse with max 2 clusters. Currently 1 Cluster is in Active state.
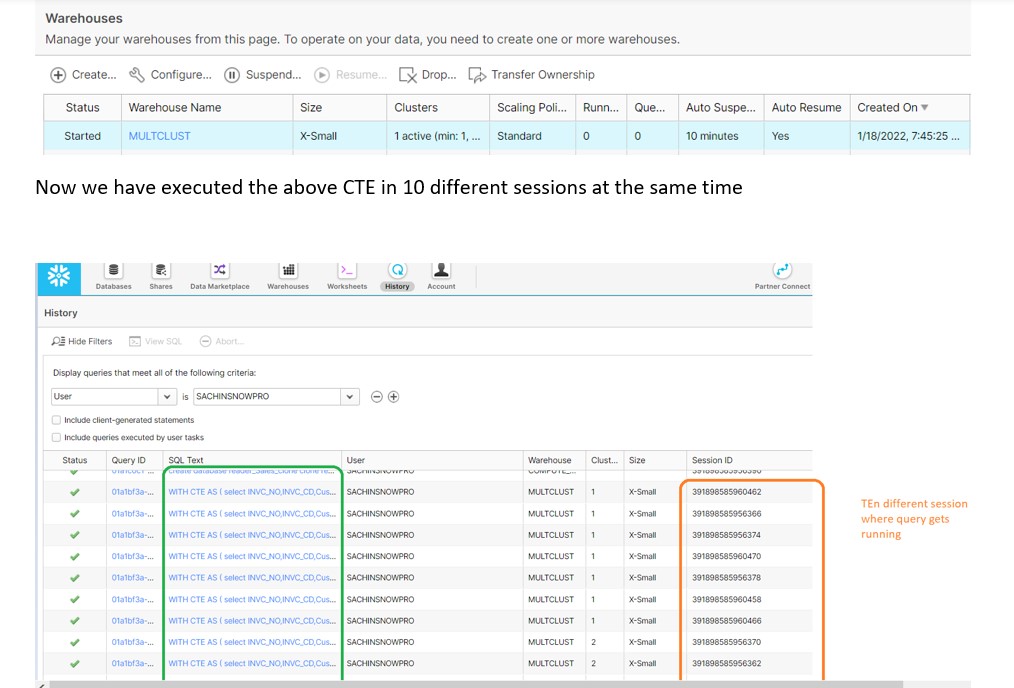
When each statement is submits to a warehouse, Snowflake allocates resources for executing the statement; if there aren’t enough resources available, the statement is queued or additional warehouses are started, depending on the warehouse.
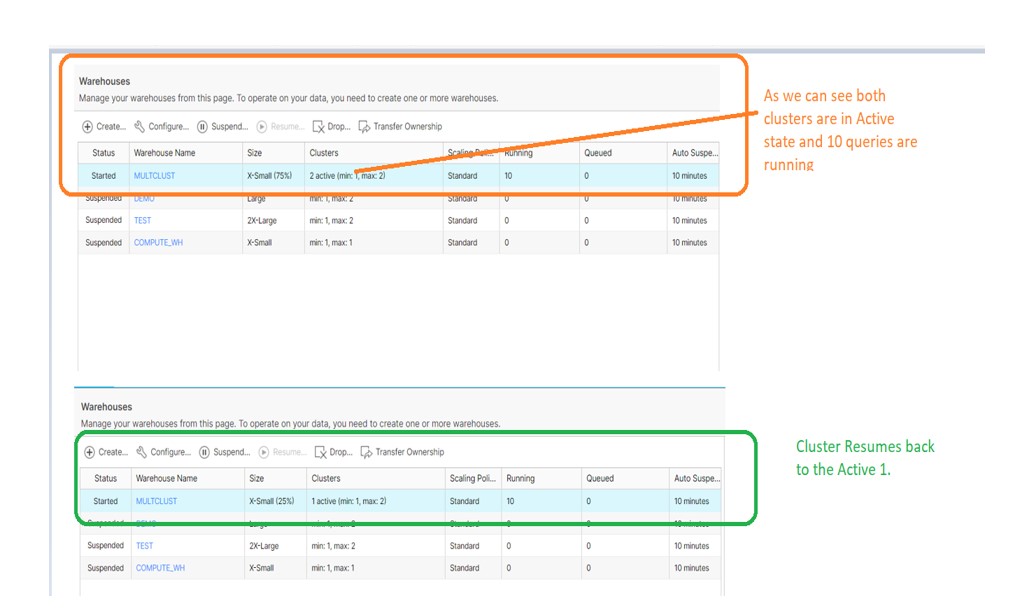
In conjunction with Multiclustering is must we should know about the MAX_CONCURRENCY_LEVEL parameter.
MAX_CONCURRENCY_LEVEL:
MAX_CONCURRENCY_LEVEL:
Specifies the concurrency level for SQL statements (i.e. queries and DML) executed by a warehouse. Default value 8. When the level is reached, the operation performs depends on whether the warehouse is a single or multi-cluster warehouse:
- Single or multi-cluster (in Maximized mode):Statements are queued until already-allocated resources are frees or additional resources are provision, which can be accomplish by increasing the size of the warehouse.
- Multi-cluster (in Auto-scale mode):Additional warehouses starts.
This parameter actually sets the maximum limit of compute resources each process or query can get. In reality there is no such hard limit of parallelism in Snowflake.
The actual number of statements executed concurrently by a warehouse might be more or less than the specified level:
- Smaller, more basic statements: More statements might execute concurrently because small statements generally execute on a subset of the available compute resources in a warehouse.
- Larger, more complex statements: Fewer statements might execute concurrently.
This 8 value is a default only and can be change at any time:
- Lowering the concurrency level for a warehouse increases the compute resource allocation per statement, but lead to increases the number of active warehouses at any time
- Raising the concurrency level for a warehouse decreases the compute resource allocation per statement.