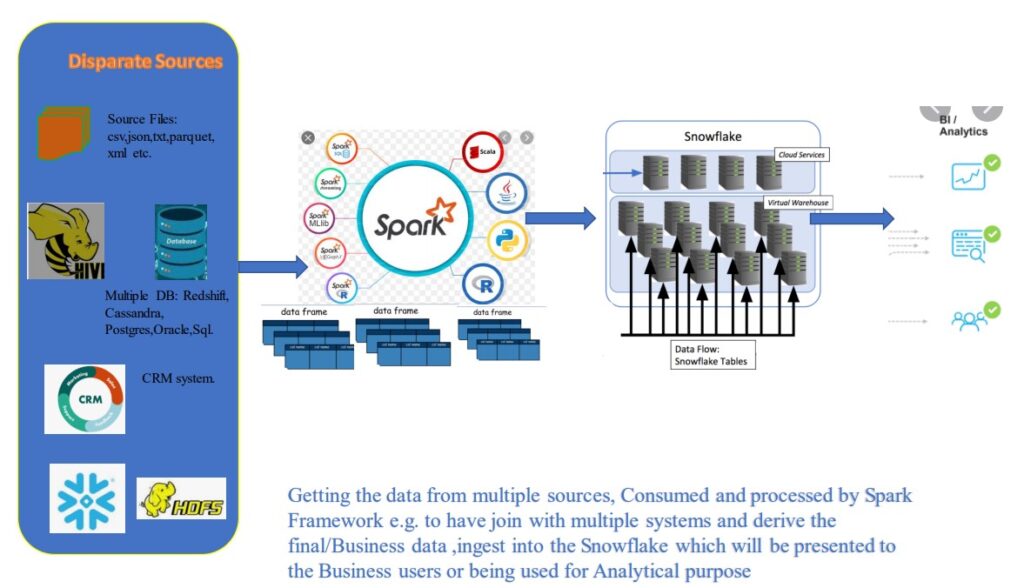
Spark can easily build complex, functionally rich and highly scalable data ingestion pipelines for Snowflake. In other words ,Spark and Snowflake provide an optimized built-in connector. Therefore allows customers to seamlessly read from and write data to SF.
The Spark/Snow Connector supports two transfer modes:
- Internal transfer uses a temporary location created and managed internally/transparently by Snowflake.
- External transfer uses a storage location, usually temporary, created and managed by the user.
Internal Data Transfer:
The transfer of data between the two systems is facilitated through a Snowflake internal stage that the connector automatically creates and manages:
External Data Transfer:
The transfer of data between the two systems is facilitated through a storage location that the user specifies and files automatically created by the connector:
Column Mapping
When you copy data from a Spark table to a Snowflake table, if the column names do not match, you can map column names from Spark to Snowflake using the columnmapping parameter.
With optimized connector, complex workloads like data cleansing, data consolidation ,unification accomplished by Spark. Therefore via Snowflake Connector, the data produced by complex ETL pipelines easily store in Snowflake using standard SQL tools.
However, migrating data among different database, datatype mapping is a hard thing . Snowflake connector handled this when loading the data to Snowflake at some extent.
Using the connector, you can perform the following operations:
Populate a DataFrame from a table (or query) in Snowflake.
Write the contents of a ApacheSpark DataFrame to a table in Snowflake.
Please find the technical implementation for Spark/Snow Integration. Click here.







