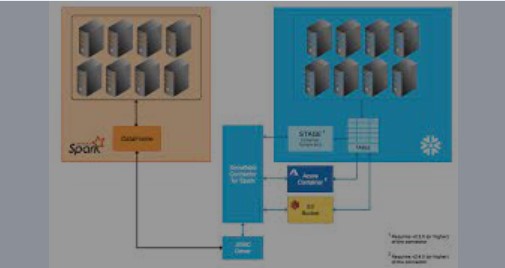
In addition, To the previous post related to Spark and Snowflake provide an optimized built-in connector. Below is the final technical implementation. Using the connector, you can perform the following operations:
- Populate a DataFrame from a table or from query in Snowflake.
- Write the contents of a ApacheSpark DataFrame to the table in Snowflake.
Moreover,The Databricks version 4.2 native Snowflake Connector allows your Databricks account to read data from and write data to Snowflake without importing any libraries.
Similarly, The connector automatically distributes processing across Spark and Snowflake, without requiring the user to specify the parts of the processing that should be done on each system. Queries also benefit from Snowflake’s automatic query pushdown optimization.
- Firstly , Load order file and create the Dataframe “Orders”.
- Consume order item file and create Dataframe “orderItems”.
- Load Product file and create Dataframe “products”.
- Joined these Dataframes and create new DF “joinResults”.
- Declare the Snowflake credential.
- Read the data from Snowflake table and store in Dataframe “sfdf”.
- Join the Snowflake Dataframes with previous DF: “joinResults” and “sfdf” and create new Dataframe “filesfResults”.
- Create the Hive table and load the file inside the Hive
- Create the Hive Dataframe “sqlDF”
- Join Hive Dataframe and “filesfResults” dataframe , Finally store into the “sfhiveResults”.
- Ingest the final dataframe i.e. sfhiveResults into Snowflake table called “Spark_Databricks”
Finally, Please follow the below Notebook to showcase the technical integration of Spark and Snowflake.
// Databricks notebook source
%scala
val orders = spark.read.schema("order_id INT, order_date TIMESTAMP,
order_customer_id INT, order_status STRING").
csv("/FileStore/tables/part_00000")
orders.printSchema()
orders.show()
orders.count()
// COMMAND ----------
%scala
val orderItems = spark.read.schema("order_item_id INT,
order_item_order_id int, order_item_product_id INT, order_item_quantity
int,order_item_subtotal FLOAT,order_item_product_price FLOAT").
csv("/FileStore/tables/ord_items")
orderItems.printSchema()
orderItems.show()
orderItems.count()
// COMMAND ----------
%scala
val products = spark.read.schema("product_id INT, product_category_id
int, product_name STRING, product_description STRING,product_price
FLOAT,product_imgae STRING").
csv("/FileStore/tables/product")
products.printSchema()
products.show()
products.count()
// COMMAND ----------
val ordersCompleted = orders.filter("order_status in
('CLOSED','COMPLETED')")
ordersCompleted.show()
ordersCompleted.count
// COMMAND ----------
val joinResults = ordersCompleted.
join(orderItems, ordersCompleted("order_id") ===
orderItems("order_item_order_id")).
join(products, products("product_id") ===
orderItems("order_item_product_id")).
select("order_id","order_date","product_id", "product_name",
"order_item_subtotal","order_status")
joinResults.count
joinResults.show(false)
// COMMAND ----------
spark.conf.set("spark.sql.shuffle.partitions", "2")joinResults.
write.
mode("overwrite").
csv("/FileStore/tables/joinresult")
// COMMAND ----------
%scala
val options = Map(
"sfUrl" -> "https://fpa95179.us-xxxx-xxxx.snowflakecomputing.com/", //
replace this with your own connection information
"sfUser" -> "sachinsnowpro",
"sfPassword" -> "xxxxxxxx",
"sfDatabase" -> "DEMO_DB",
"sfSchema" -> "PUBLIC",
"sfWarehouse" -> "COMPUTE_WH",
"sfRole" -> "ACCOUNTADMIN"
)
// COMMAND ----------
%scala
val sfdf = spark.read
.format("net.snowflake.spark.snowflake") // or just use "snowflake"
.options(options)
.option("dbtable", "sf_orders")
.load()
sfdf.show(true)
// COMMAND ----------
val filesfResults = sfdf.
join(joinResults, sfdf("O_ORDERKEY") === joinResults("order_id")).
select("order_id","order_date","product_id","product_name","order_status"
,"O_CUSTKEY","O_ORDERSTATUS","O_TOTALPRICE","O_ORDERDATE",
"O_ORDERPRIORITY")
filesfResults.show(false)
// COMMAND ----------
%scala
import spark.implicits._
import spark.sql
sql("CREATE TABLE spark_hive (H_ORDERKEY INTEGER, H_CUSTKEY
INTEGER,H_ORDERSTATUS STRING,H_TOTALPRICE INTEGER,H_ORDERDATE
DATE,H_ORDERPRIORITY STRING,H_CLERK STRING,H_SHIPPRIORITY INTEGER,
H_COMMENT STRING) row format delimited fields terminated by ','")
sql("LOAD DATA INPATH '/FileStore/tables/result.csv' INTO TABLE
spark_hive")// Queries are expressed in HiveQL
//sql("SELECT * FROM spark_hive").show()
// Aggregation queries are also supported.
//sql("SELECT COUNT(*) FROM src").show()
// +--------+
// |count(1)|
// +--------+
// | 500 |
// +--------+
// The results of SQL queries are themselves DataFrames and support all
normal functions.
val sqlDF = sql("SELECT H_ORDERKEY, H_CUSTKEY
,H_ORDERSTATUS,H_TOTALPRICE,H_ORDERDATE,H_ORDERPRIORITY,H_CLERK FROM
spark_hive")
sqlDF.show()
// COMMAND ----------
val sfhiveResults = filesfResults.
join(sqlDF, filesfResults("order_id") === sqlDF("H_ORDERKEY")).
select("order_id","order_date","product_id","product_name","order_status"
,"O_CUSTKEY","O_ORDERSTATUS","O_TOTALPRICE","O_ORDERDATE",
"O_ORDERPRIORITY",
"H_ORDERKEY","H_CUSTKEY","H_ORDERSTATUS","H_TOTALPRICE","H_ORDERDATE","H_
ORDERPRIORITY","H_CLERK")
sfhiveResults.show(false)
// COMMAND ----------
%scala
import org.apache.spark.sql.SaveMode
sfhiveResults.write.format("snowflake")
.options(options)
.option("dbtable", "Spark_Databricks")
.mode(SaveMode.Overwrite)
.save()







