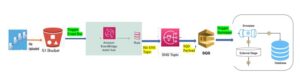
Snowflake’s Serverless Tasks are designed to automate workflows without requiring a dedicated warehouse. Instead, Snowflake dynamically allocates compute resources based on workload demands, making it a cost-effective and scalable solution for scheduling data transformations, ELT processes, and real-time analytics.
However, to fully optimize serverless tasks, Snowflake provides three key parameters that control compute scaling and execution efficiency:
- SERVERLESS_TASK_MAX_STATEMENT_SIZE → Defines the maximum compute power allocated to a task.
- SERVERLESS_TASK_MIN_STATEMENT_SIZE → Ensures a minimum compute allocation for predictable performance.
- TARGET_COMPLETION_INTERVAL → Determines the preferred time window within which Snowflake should try to complete the task.
Why These Parameters Matter
Without fine-tuning these settings, serverless tasks can either:
- Underperform due to insufficient compute power.
- Over-utilize compute, leading to unnecessary Snowflake costs.
- Fail to execute on time, delaying critical pipelines.
By strategically configuring SERVERLESS_TASK_MAX_STATEMENT_SIZE, SERVERLESS_TASK_MIN_STATEMENT_SIZE, and TARGET_COMPLETION_INTERVAL, you can ensure reliable execution, control costs, and prevent performance bottlenecks in your workflows.
Understanding Task Precedence: Which Setting Takes Priority?
Understanding Task Precedence: Which Setting Takes Priority?
When multiple parameters are used, Snowflake follows this execution order.
Key Takeaway:
- If MAX_STATEMENT_SIZE is reached, Snowflake won’t allocate more compute even if the task takes longer than TARGET_COMPLETION_INTERVAL.
- If MIN_STATEMENT_SIZE is set, Snowflake guarantees at least this compute size to prevent slowdowns.
Breaking Down Each Parameter with Examples
Breaking Down Each Parameter with Examples
- SERVERLESS_TASK_MAX_STATEMENT_SIZE
This parameter caps the maximum compute size Snowflake can allocate to a task. It prevents excessive scaling while ensuring tasks have enough power to be completed on time.
Use Case:
Imagine you have a large ETL process that consolidates raw sales data into a summary table. You want the task to complete in a reasonable time but not overuse compute resources.
Example: Limiting a task’s compute to LARGE prevents cost overruns while ensuring execution efficiency.
CREATE TASK ETL_PROCESS
SCHEDULE='USING CRON 0 * * * * UTC' -- Runs every hour
SERVERLESS_TASK_MAX_STATEMENT_SIZE='LARGE'
AS
INSERT INTO SALES_SUMMARY
SELECT REGION, SUM(SALES) FROM RAW_SALES_DATA
WHERE SALE_DATE = CURRENT_DATE
GROUP BY REGION;
Why?
- Ensures the task never exceeds “LARGE” compute, keeping costs under control.
- Snowflake allocates the needed compute power but stops scaling beyond the limit.
2. SERVERLESS_TASK_MIN_STATEMENT_SIZE
This parameter forces Snowflake to allocate at least a minimum compute size, ensuring tasks don’t get too little compute and slow down unexpectedly.
Use Case:
Suppose you have a data cleanup job that removes outdated customer records daily. Even if it’s a small operation, you don’t want it running on insufficient compute, leading to performance delays.
Example: Setting a minimum compute size to MEDIUM ensures the job runs efficiently every time.
CREATE TASK CLEANUP_JOB
SCHEDULE='USING CRON 0 3 * * * UTC'
SERVERLESS_TASK_MIN_STATEMENT_SIZE='MEDIUM'
AS
DELETE FROM CUSTOMER_TABLE
WHERE LAST_LOGIN < DATEADD(YEAR, -1, CURRENT_DATE);
Why?
- Prevents the task from running on low-power compute.
- Ensures consistent execution time, avoiding slow performance on busy days.
3. TARGET_COMPLETION_INTERVAL (Execution Time Optimization)
This parameter tells Snowflake how quickly a task should complete, allowing dynamic scaling to meet the deadline.
Use Case:
A real-time fraud detection job that flags suspicious transactions must complete within 10 minutes. Snowflake should allocate enough compute to ensure it runs quickly.
Example:
CREATE TASK FRAUD_MONITOR
SCHEDULE='USING CRON */5 * * * * UTC' -- Runs every 5 minutes
TARGET_COMPLETION_INTERVAL='10 MINUTE'
SERVERLESS_TASK_MAX_STATEMENT_SIZE='XLARGE'
AS
INSERT INTO FRAUD_ALERTS
SELECT TRANSACTION_ID, USER_ID
FROM TRANSACTION_LOGS
WHERE AMOUNT > 10000;
Why?
- Ensures task completes within 10 minutes by allocating more compute if needed.
- Snowflake dynamically adjusts compute power to meet this time constraint.
Advanced Scenario: Combining All Three Parameters
Advanced Scenario: Combining All Three Parameters
Use Case:
A daily data transformation that must complete within 3 hours and requires at least a MEDIUM warehouse but should not exceed a LARGE warehouse.
Solution:
CREATE TASK SCHEDULED_T3
SCHEDULE='USING CRON 0 0 * * * UTC' -- Runs once per day
TARGET_COMPLETION_INTERVAL='180 MINUTE'
SERVERLESS_TASK_MIN_STATEMENT_SIZE='MEDIUM'
SERVERLESS_TASK_MAX_STATEMENT_SIZE='LARGE'
AS
SELECT 1;
Ensures task completes within 3 hours
Scales compute between MEDIUM and LARGE dynamically
Prevents failures due to system load by allowing flexible execution time
Final Thoughts
By fine-tuning SERVERLESS_TASK_MAX_STATEMENT_SIZE, SERVERLESS_TASK_MIN_STATEMENT_SIZE, and TARGET_COMPLETION_INTERVAL, you can:
Improve Performance → Faster, more reliable task execution.
Control Costs → Prevent unnecessary scaling and high compute usage.
Enhance Stability → Avoid slow execution or unexpected failures.