
Snowpark Magic: Auto-Create Tables from S3 Folders — In modern data lakes, it’s common for departments like Finance, Marketing, Sales, etc., to continuously drop data files into their respective folders within an S3 bucket. These files often arrive in CSV format, and over time, teams request new folders or refresh their data. With Snowpark, you can automatically detect new folders, create corresponding tables in Snowflake, and ingest the data seamlessly — all with minimal manual intervention
The challenge:
-
How do you automatically detect new folders, create tables, and load data without manual intervention?
-
And more importantly — how do you avoid reloading already processed files?
That’s exactly the scenario we’re solving in this blog using Snowflake Snowpark with an elegant real-time pattern.
Technical Solution Overview
We built a Snowpark Python procedure that:
-
Scans all folders in an S3 bucket stage (
@multiple_folders) -
Creates a table dynamically for each folder (e.g.,
FINANCE,SALES) -
Loads data from new files using the
COPY INTOcommand -
Skips already-ingested files by tracking them in a
FILE_LOAD_LOGtable -
Supports future folder additions without code changes!
This means your pipeline can evolve organically — as teams add new folders, new Snowflake tables are created automatically and data is seamlessly ingested.
Sample Folder Structure in Stage:

@multiple_folders/
Finance/Finance.csv
Sales/Customer_Invc.csv
Marketing/Marketing.csv
Accessories/Accessory.csv
Each of these maps to a Snowflake table: FINANCE, SALES, etc.
Technical Implementation:

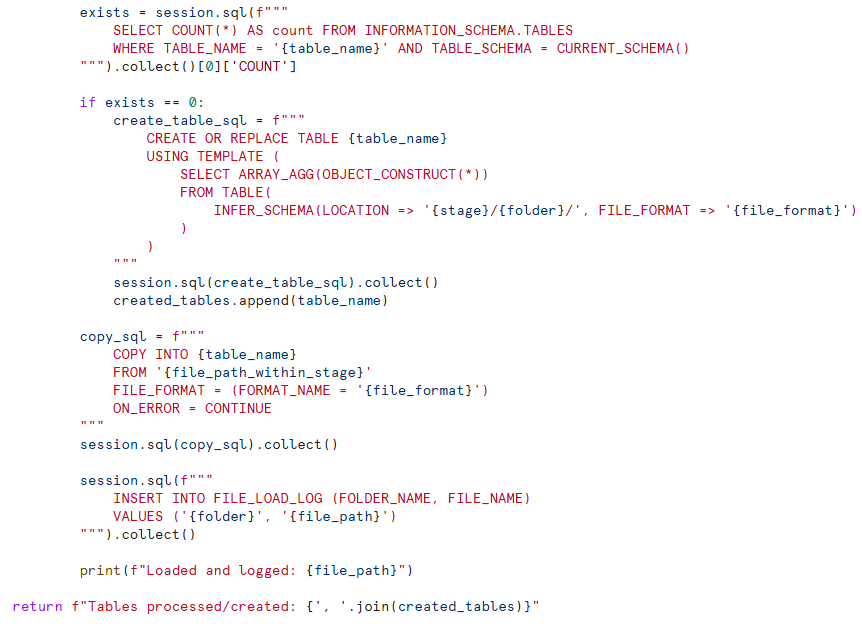
High-Level Explanation of the Code
-
Stage & File Format Initialization
-
Defines the stage name and file format to be use (CSV in this case).
-
-
Retrieve Files from Stage & Load Log
-
Lists all files available in the stage.
-
Queries the
FILE_LOAD_LOGtable to identify which files have already been processed.
-
-
Skip Already Loaded Files
-
Uses a Python
setto track and skip files that are already list in theFILE_LOAD_LOG.
-
-
Parse Folder and File Names
-
Splits the path of each file to extract the folder name, which is used as the target table name.
-
-
Dynamically Create Table (if it doesn’t exist)
-
Checks if a table named after the folder exists.
-
If not, uses
INFER_SCHEMAto dynamically create a table based on the file structure usingUSING TEMPLATE.
-
-
Load Data via
COPY INTO-
Loads the data from the file into the corresponding table using Snowflake’s
COPY INTO.
-
-
Track Loaded Files
-
Inserts a record into the
FILE_LOAD_LOGto mark the file as processed.
-
-
Return a Summary
-
Returns a string listing all newly created or processed tables.
-
The FILE_LOAD_LOG table plays a crucial role in ensuring idempotency—the process does not reload the same file twice.
Execute the Code:


Now to test how the code works if next day a new folder created. Or the new file uploaded to the existing folder say Marketing.

Execute the Procedure and observe the Output:

Key Features and Benefits
- Real-time Adaptability – Tables are created on-the-fly for any new department added to the landing zone.
- No Reprocessing – Files that are already processed are logged and skipped, saving compute and preventing duplicates.
- Schema Inference – We use
INFER_SCHEMAto automate schema detection without manual DDL. - Scalable for Multi-Department Architectures – Whether it’s 5 folders or 500, this approach scales easily.
- Clean and Maintainable Codebase – All logic is bundled in a clean Snowpark Python function for easy maintenance.









