In this blog post, we’ll explore a practical approach to ensure the accuracy of file counts before they’re ingested into Snowflake. In current scenario the source system sends data files to a UNIX environment, which is then utilized by downstream systems. Planning to leverage Snowflake capabilities, Business wants to develop a POC where the same File has to be consumed inside the Snowflake. Primarily on to UNIX machine, the source team intends to upload the file to an AWS S3 bucket and the UNIX machine respectively. The source file is accompanied by control files that store the file name and its corresponding count. Before proceeding with the ingestion process from AWS into Snowflake, it’s crucial to establish a validation mechanism. This mechanism verifies whether the count of records in the data file aligns with the count specified in the control file. If the counts match, the file is considered authentic.
Furthermore, our process will establish a connection with Snowflake’s SQL and execute the insertion process, ensuring the data seamlessly enters Snowflake’s environment. One interesting aspect to consider is the dynamic nature of the source files. These files’ metadata can change over time due to business requirements. These feed files are generated using SQL Server, and modifications to the SQL Server table could alter the file’s structure. As a result, the files copied to AWS and the UNIX machine can exhibit varying structures.
Hence our process needs to be adaptive and capable of automatically inferring the schema changes in the dynamic files.
Technical Implementation:
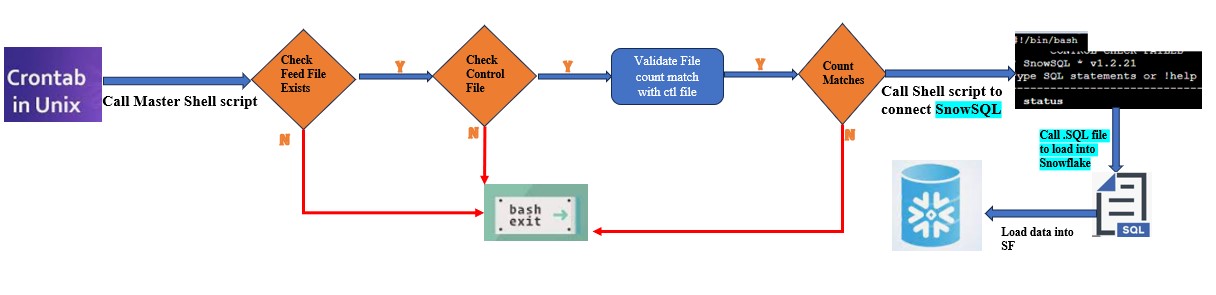
So finally the below technical flow has to be implement:
- A sql file contains Snowflake Create table and COPY commands.
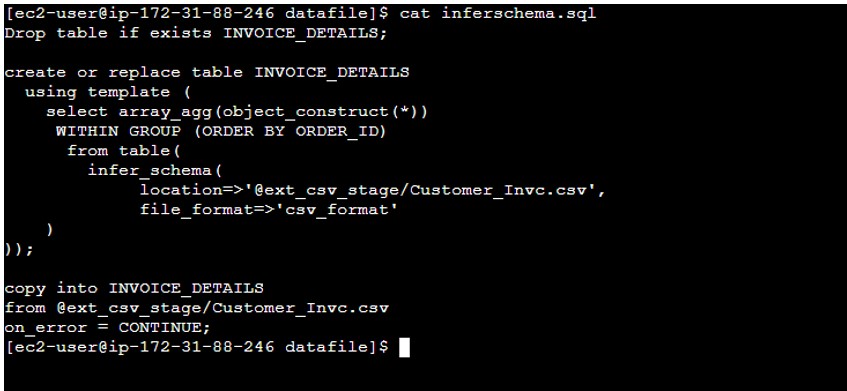
- Sql File is using INFER_SCHEMA for CSV file. Earlier INFER_SCHEMA was applicable to Parquet or ORC but now this can be use to determine the Dynamic meta structure of CSV file.
- A shell script to connect with SNOWSQL.
- Will see how we can connect to the SNOWSQL inside the shell script which in turn call the.sql file created in earlier step.
- Develop a UNIX script to validate the File count.
- This is the main script which validates the count of feed file with control file count, If it matches only then it connects to SNOWSQL and execute the .sql file we created in above steps.
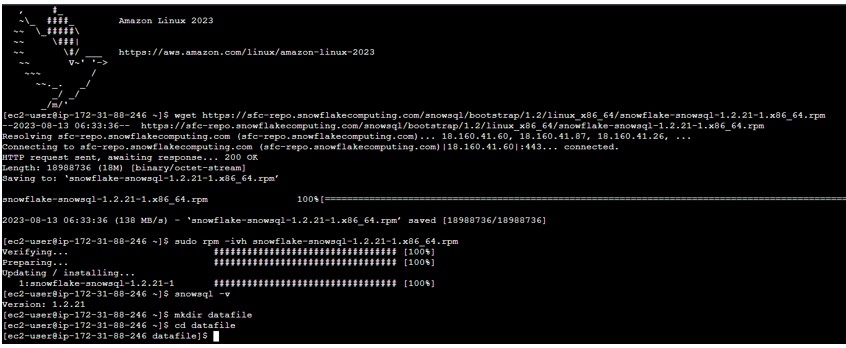
Steps on UNIX: Launch an EC2 Linux machine on AWS cloud and install the SNOWSQL on machine.
- wget https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowflake-snowsql-1.2.21-1.x86_64.rpm
- sudo rpm -ivh snowflake-snowsql-1.2.21-1.x86_64.rpm
- once installed, verify the installation by checking the version of SnowSQL.
snowsql -v
- Create directory on UNIX:
mkdir datafile
- Create inferschema.sql file to have the INFER_SCHEMA commands and COPY commands.
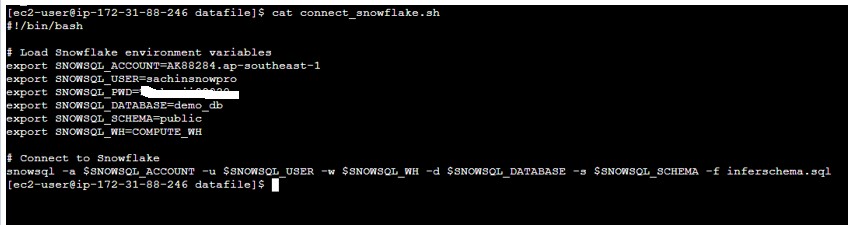
- Develop a shell script connect_snowflake.sh file which will connect to SNOWSQL and call above inferschema.sql file.
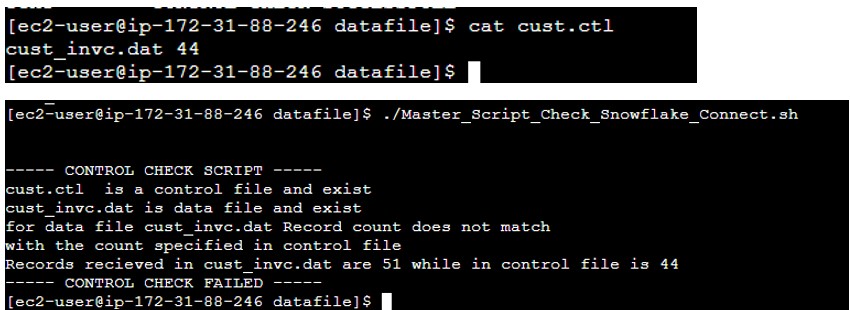
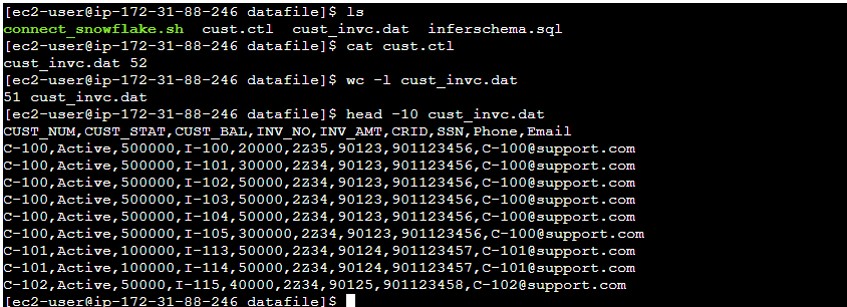
- Source team has placed the feed file along with the ctl file.
- Observe the content inside the ctl file: It has a feed file name and counts in the file.
- Observe the record count in the Feed file, currently, it is showing 52 (inclusive header).
- So our script we will validate the file count excluding the header.
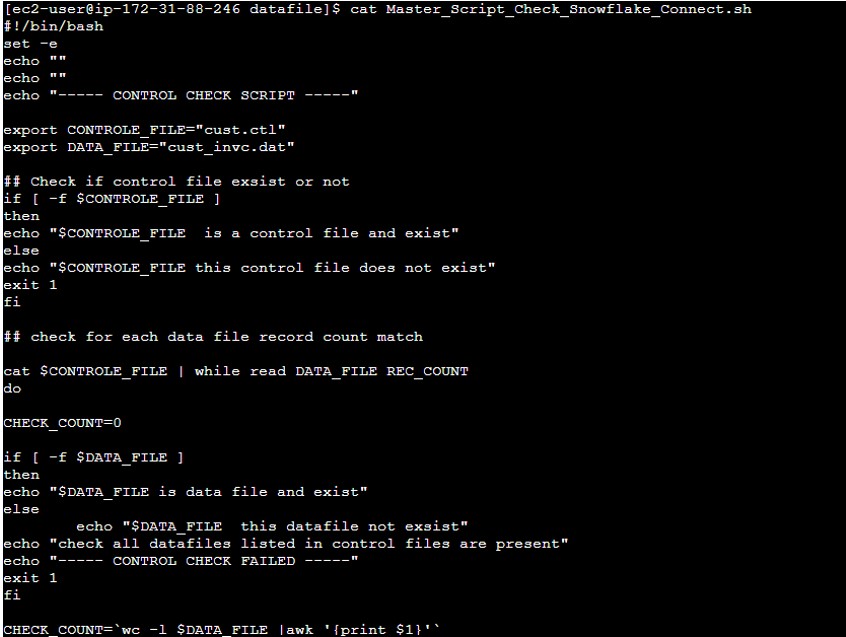
- Develop the Master_Script_Check_Snowflake_Connect.sh which will validate the count and if I matches then trigger the connect_snowflake.sh
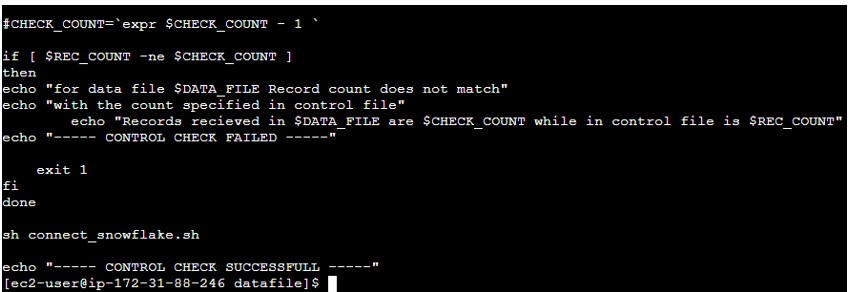
- Execute the Script and verify the output.
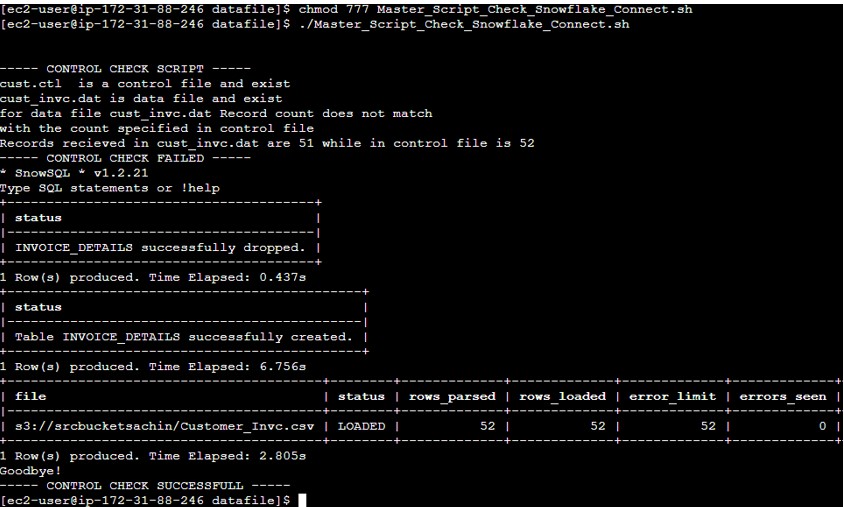
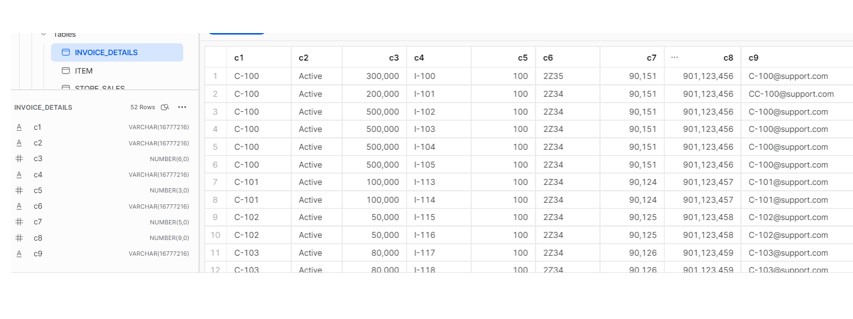
- Snowflake output:
- Now with negative testing.
- I have modified the ctl file with record count 42.