
Schema Detection Automate: Consider the scenario where we are getting files (PARQUET format) from multiple sources and structure of Files is also varies depending on the source system. Every source file has different set of columns and as per need ,Ingest these files to Snowflake in a single table. Data pipeline should be robust enough that it should read the multiple file structure at run time and ingest them in a same table.
One of the upfront approach comes to our mind, will copy the file data into Snowflake by using VARIANT columns .Later on parse the data into rows-columns by SQL query. But limitation with this approach is that we need to provide the schema beforehand and only then we could able to parse the file. Also another challenge is that File Schema is different for every source and requires manual intervention to get the schema based on the Source system.
Snowflake latest feature Schema Detection came to the rescue, It automatically detecting the schema i.e. Schema Detection Automate in a set of staged semi-structured data files and retrieving the column definitions. Moreover ,Snowflake automatically create a table for you with the detected schema.
Snowflake provide below three functions for the implementation of Schema Detection:
- INFER_SCHEMA retrieves and returns the schema from a set of staged files.
- GENERATE_COLUMN_DESCRIPTION returns the list of columns necessary to create a table, external table, or view. Here you can modify the columns or data types before you complete the creation of the object.
- CREATE TABLE … USING TEMPLATE expands upon Snowflake’s CREATE TABLE functionality to automatically create the structured table using the detected schema from the staged files with no additional input.
We will discuss more about these functions in detail in another blog post Schema detection overview….
USe Case:
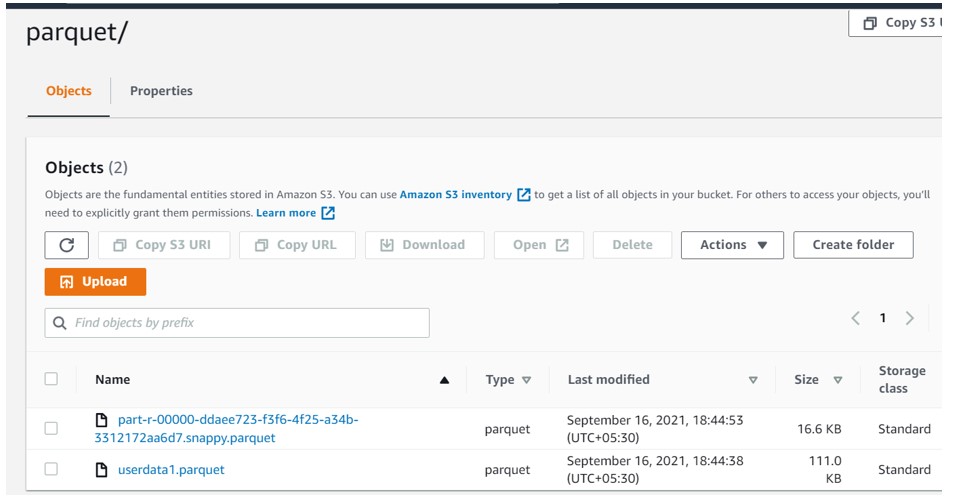
To continue with our Parquet file format requirement, Please find below two different files uploaded to the S3 bucket.
Structure of both file as follows:
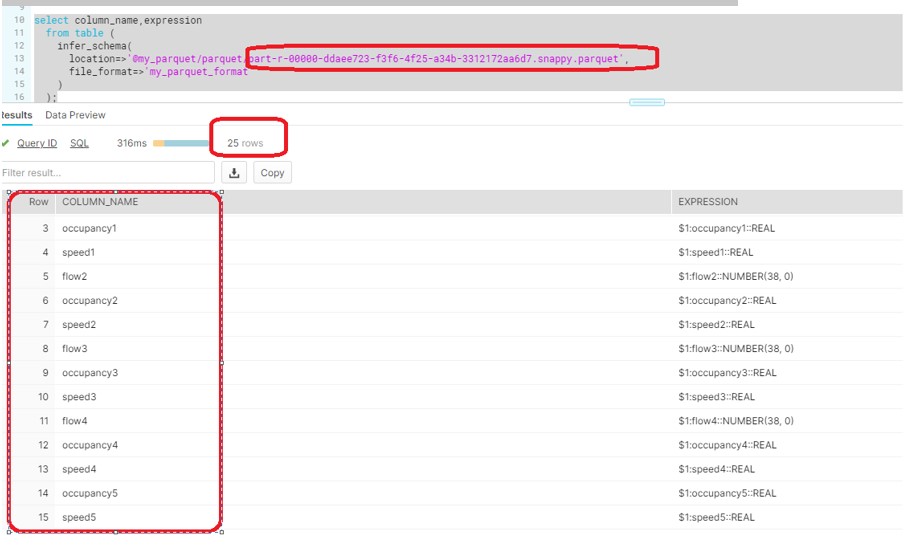
File : part-r-00000-ddaee723-f3f6-4f25-a34b-3312172aa6d7.snappy.parquet
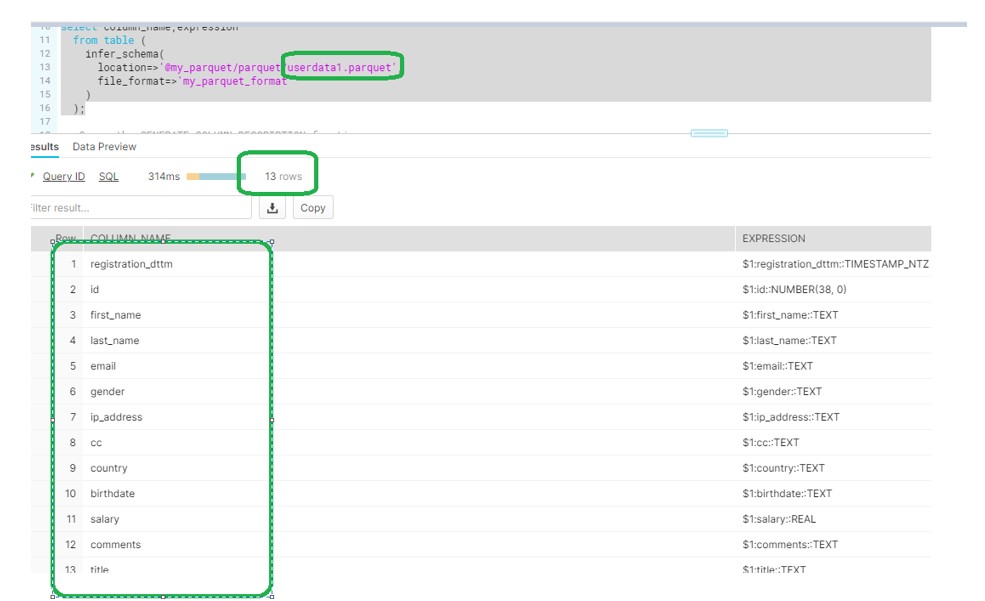
File : userdata1.parquet
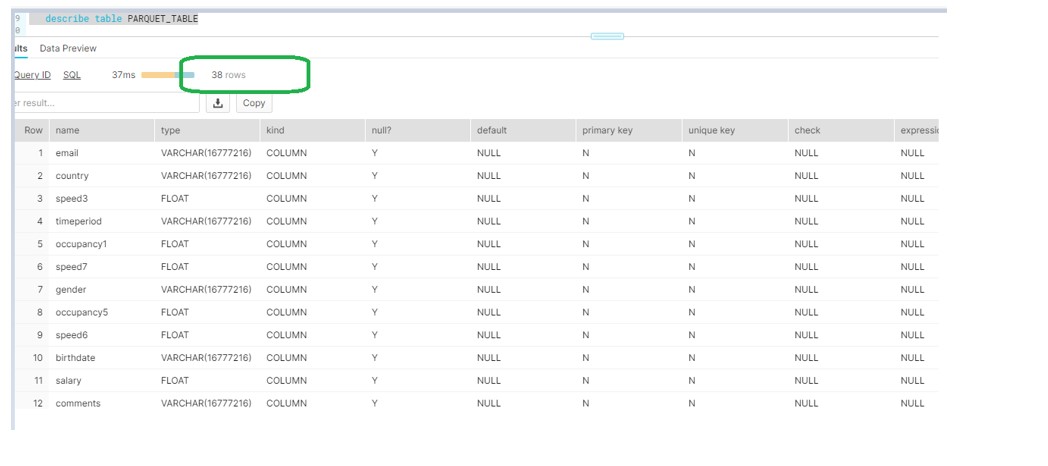
Now we will use the CREATE TABLE … USING TEMPLATE function to create a table that will hold the structure of both files in one step.
Snowflake Schema detection will make the union of all columns from the different files in random order.
create or replace table PARQUET_TABLE using template
(select array_agg(object_construct(*)) from table
(
infer_schema(
location=>'@my_parquet/parquet/',
file_format=>'my_parquet_format'
)
));
Output:
Note: This will create an EMPTY table with the UNION of all the column listed in the file.
Now Data needs to be loaded in below way:
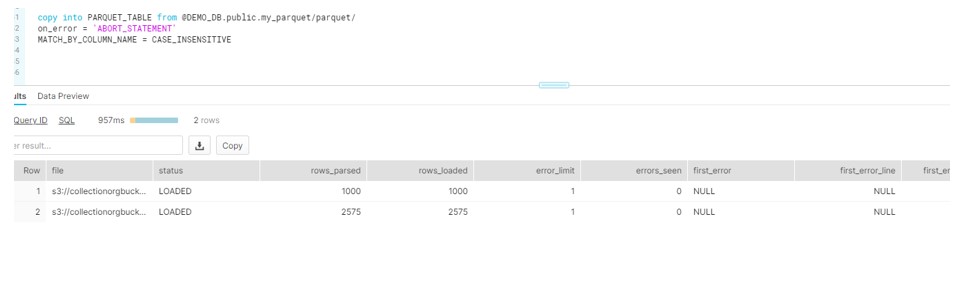
Note: MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE. As INFER_SCHEMA doesn’t guarantee to return the column names in the same order of file.








Good Post.
Very Nice explanation.!
Thanks sirji…