During this post we will talk about, how to process unstructured data and ingest into Snowflake. For our use case we will read and fetch data from PDF file. Consider the scenario where Client have multiple PDF file available in a folder. As per the need, Client wants to traverse these PDF files and extract the Invoice number. Later on, these Invoices should be store in Snowflake Table say ACTIVE_INVOICE. Parallel there is a Legacy table available in Snowflake which stores the historical as well as current Invoices data. Now the Client wants to get rid of these historical data but there is no mechanism at their end to identify Active and Stale invoices. Assuming the PDF file present in folder are the Active invoices and As ask, we need to join these two tables ( ACTIVE_INVOICE and HISTORICAL Table). After the join extract the Active Invoices along with their relevant information from the table and mark rest Invoices as Inactive.
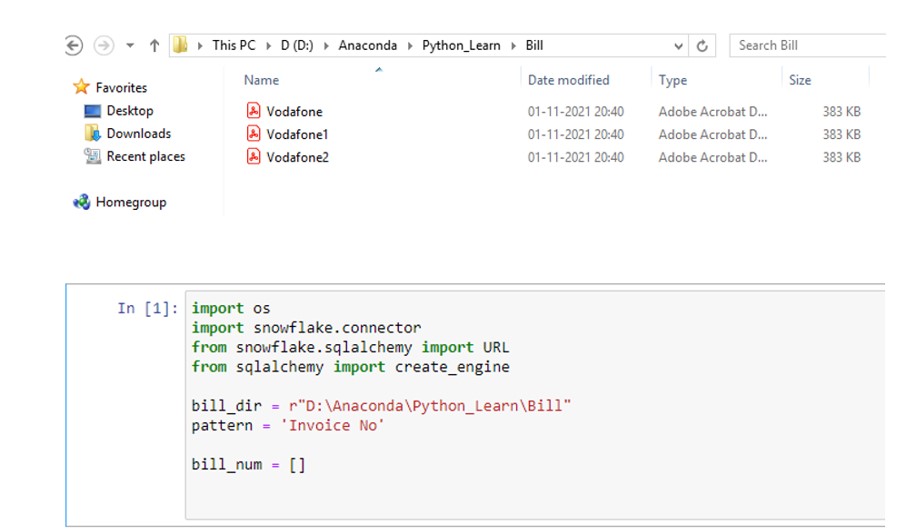
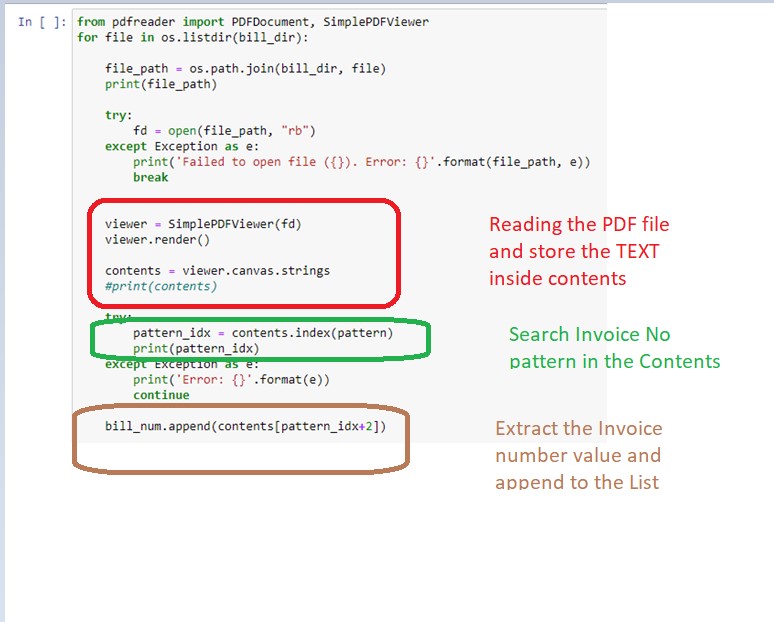
To implement the above requirement, I have used the Python – pdfreader library to read and extract the data from PDF files. Please find below snapshot of the code .
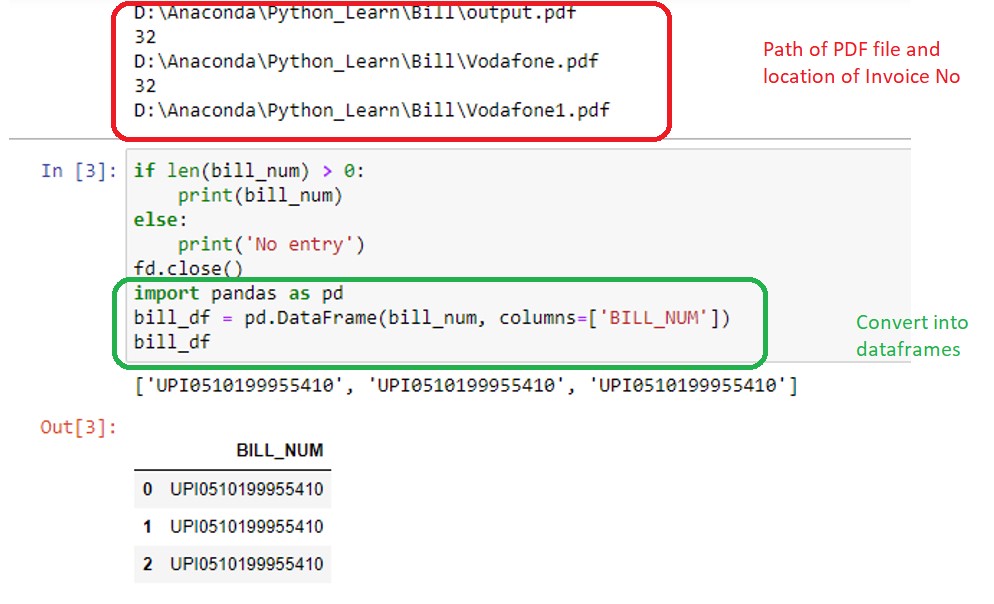
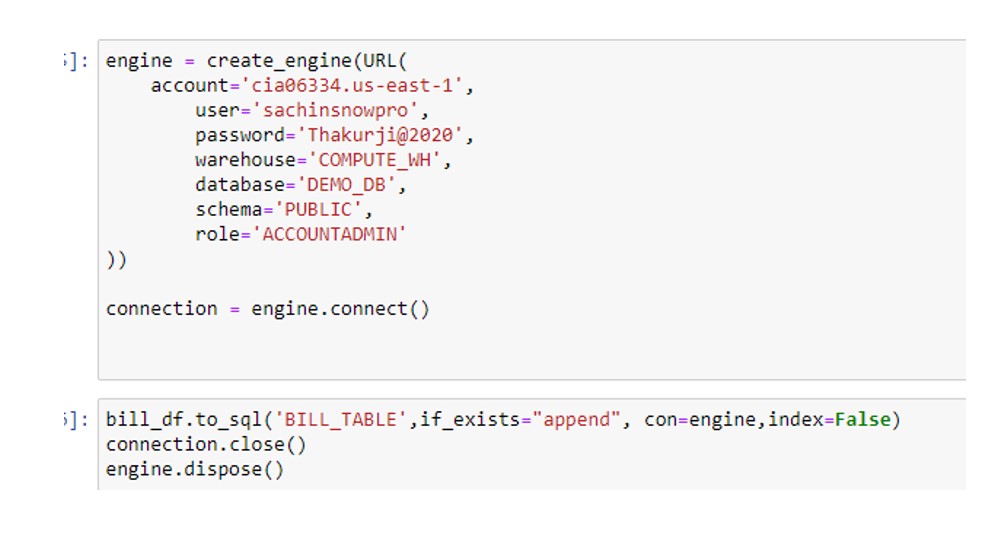
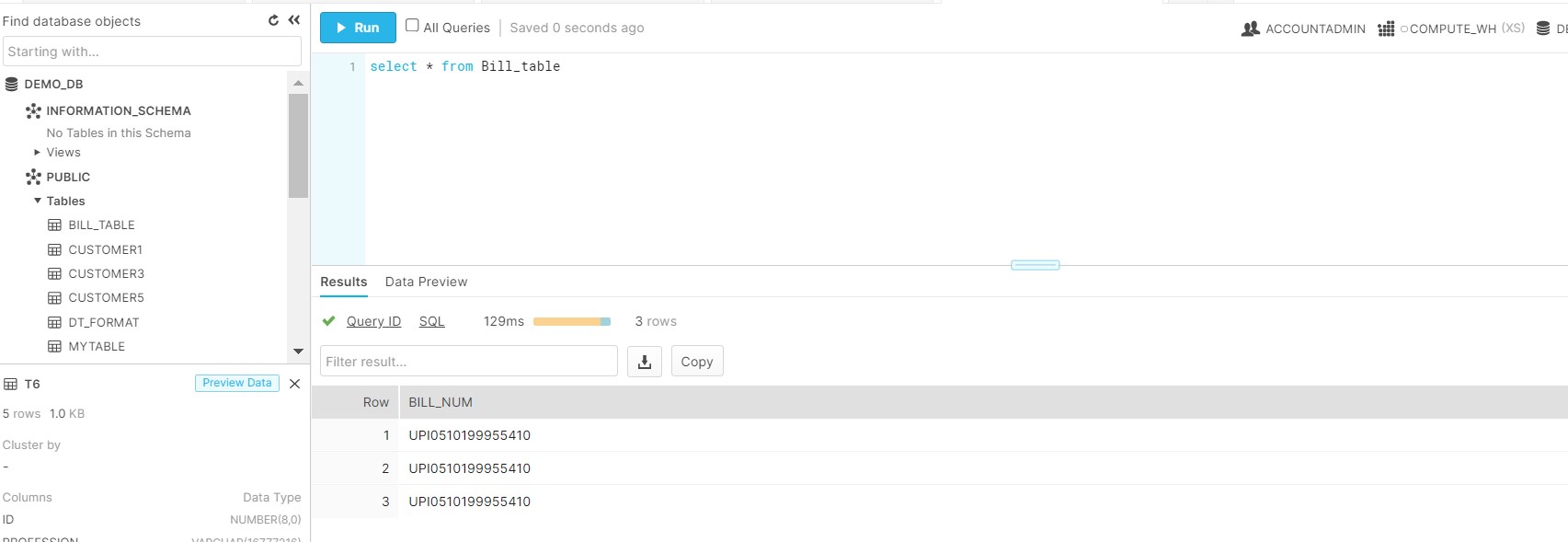
So with the above code ,Dataframe has been written to the Snowflake inside he BILL_TABLE. Please see the below screenshot from the Snowflake.