During this post we will discuss a requirement which we resolve using SQL scripting. Currently we are in the development phase, and we have created multiple tables. Later on, using the different mechanisms we have populated these tables. As per the confirmation from the source team as well, they don’t have any duplicate data in their database. Snowflake Business users also confirm the same understanding and expecting no data duplicity in Snowflake.
In development environment many developers are accessing and loading the same table. It can be the possibility that same table gets loaded by multiple people. This can lead to data redundancy and duplicity in the tables. Though this can be acceptable till the development and code is in progress. At the final analysis, we wanted to ensure that these table should hold the unique records.
As part of this process, we want to identify such tables where duplicate records are there. We will compile the list of these table and truncate them accordingly. Thereafter we will run the Data load process from fresh to ingest the data in these tables.
Requirement seems straightforward if have few or limited tables in our database. But consider the scenario when we have huge number of tables in database. So it would be tedious job to query each and every table manually and identify the corrupted tables. To avoid such manual activity we have developed a sql scripting procedure which will query the tables automatically and identify the erroneous tables. At last the procedure would return the final compile list of such tables.
Technical discussion:
Let move to the technical part.
Below query returns the list of table along with count in DEMO_DB database.
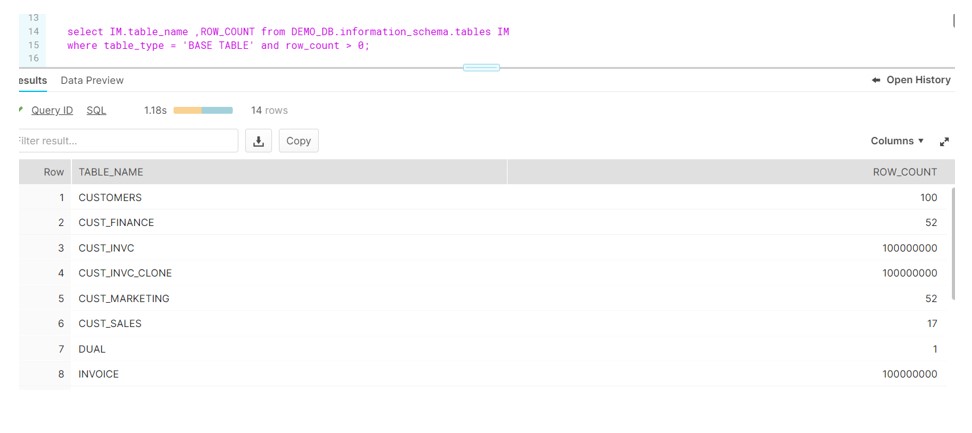
Below is the procedure to traverse the tables present in DEMO_DB and have record count > 0.
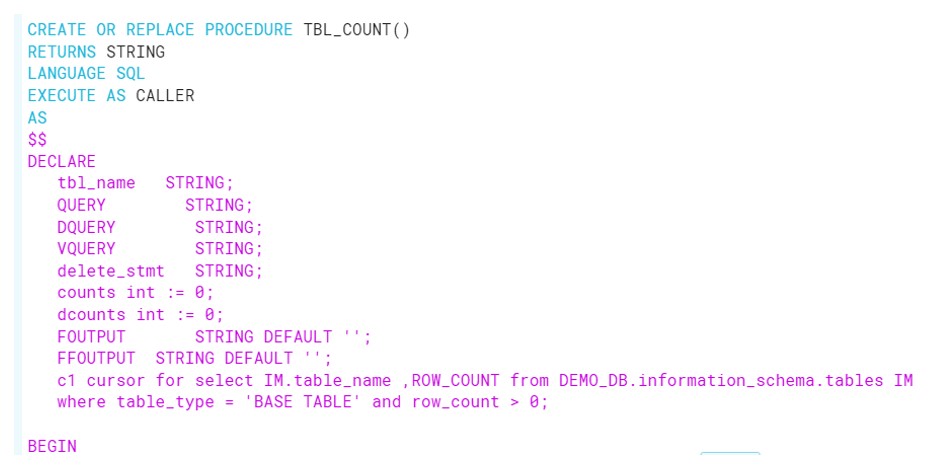
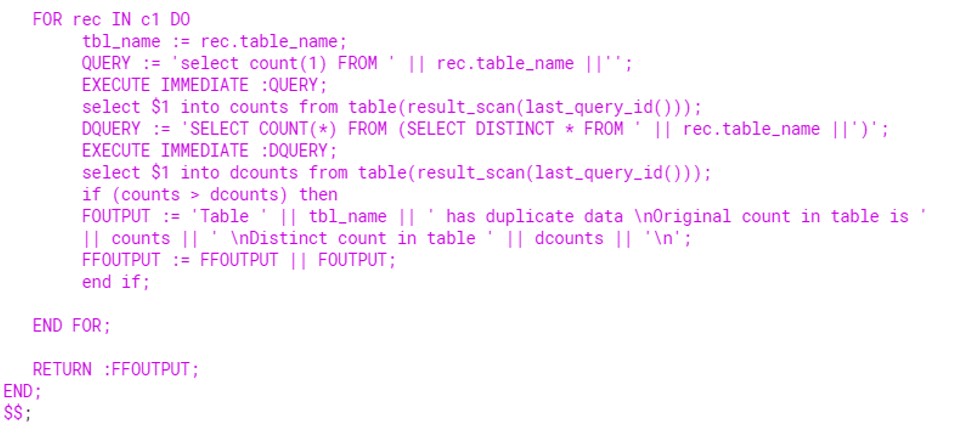
Execute the Procedure:
CALL TBL_COUNT();
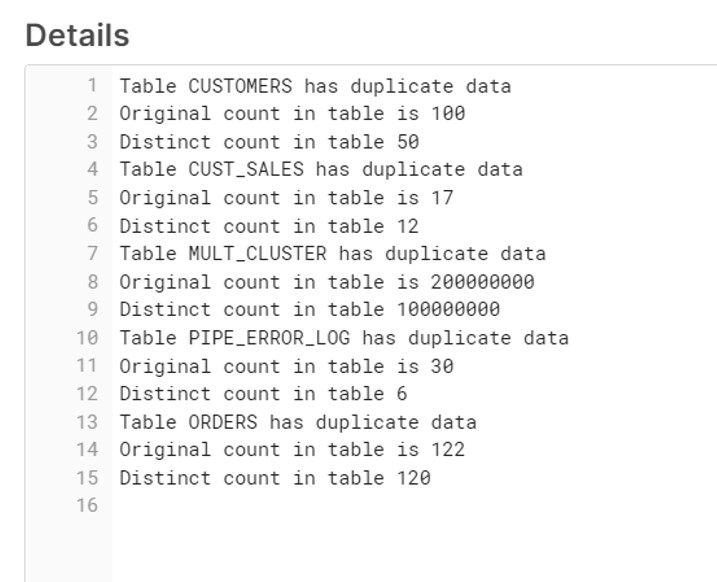
Please find below output and we get list of tables along with Total count and Distinct count.