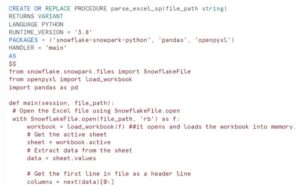
During this post we will discuss about common data format issue. Consider the scenario during the initial phase we have agreed with business on the feed file format. As per the agreement a fixed “,” delimited file would be provided by business. Based on the defined file format we create the table inside the snowflake database. But due to some process modification in source, we see data format gets change in source system. Instead of agreed Fixed file format we are getting extra comma in one of the fields in feed file. During the processing of file at Snowflake end we get the following error:
“Number of columns in file (9) does not match that of the corresponding table (8), use file format option error_on_column_count_mismatch=false to ignore this error”
In order to process the file, we can enclose the changed column into Double Quotes in the file itself. However in addition to it will use field_optionally_enclosed_by='”‘ in the creation of the FILE FORMAT. Though this manual modification is fine if we talk about some few records. But recently we have come across this situation on big file and instead of doing it manually we have decided to resolve it programmatically.
So during this discussion we will be talking about two scenario:
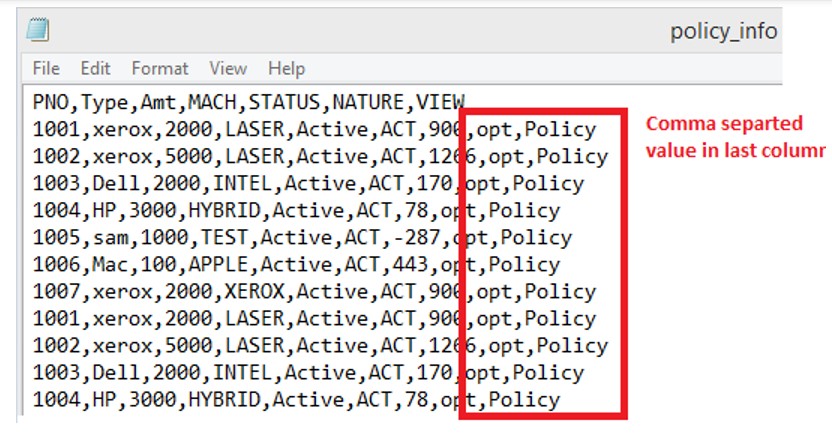
- When the Supplement comma column is last column of feed file.
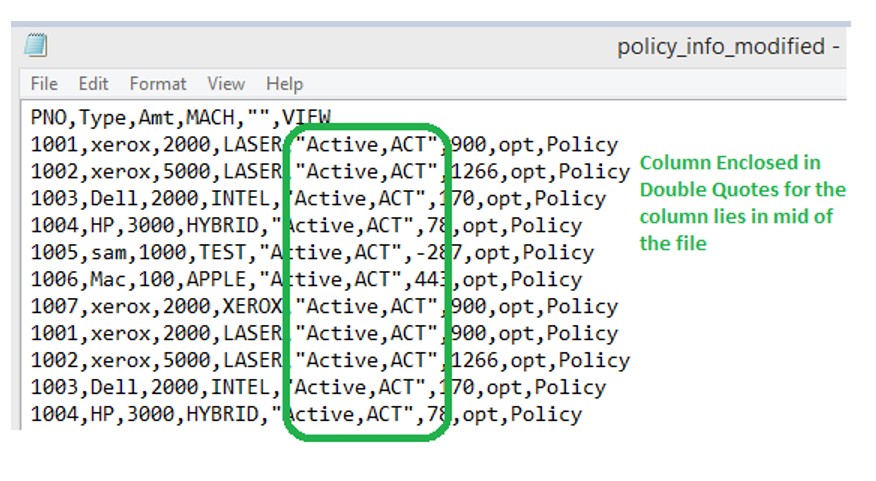
- Or Extra comma column lies in between the fields
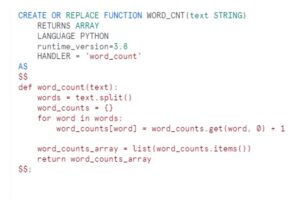
We have written a python code to take care of above scenario
Case 1: Extra comma Column at last.
Source File:
Python Code:
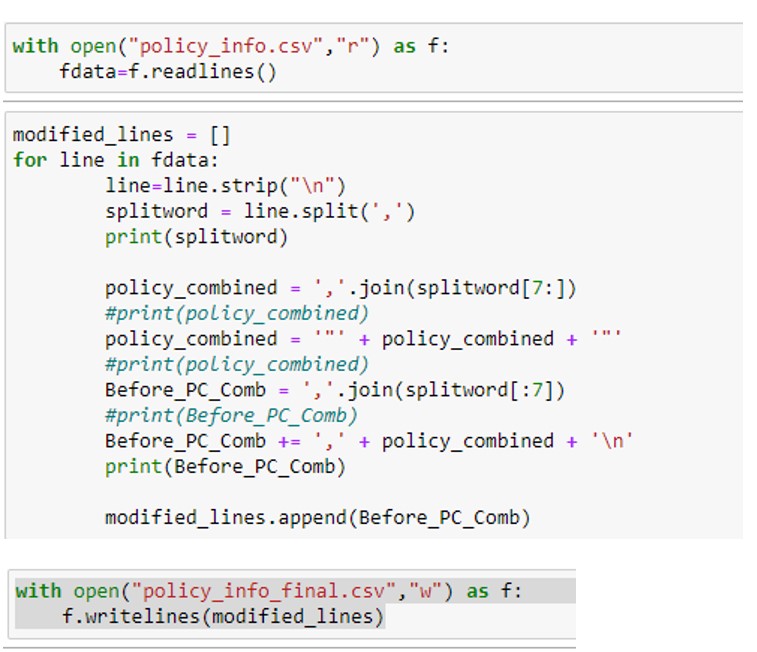
Output:
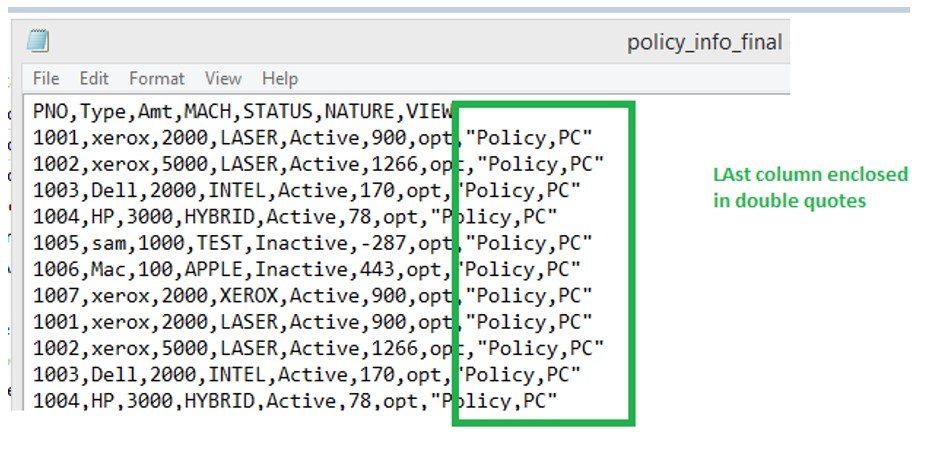
Case 2: Extra comma Column in mid of fields.
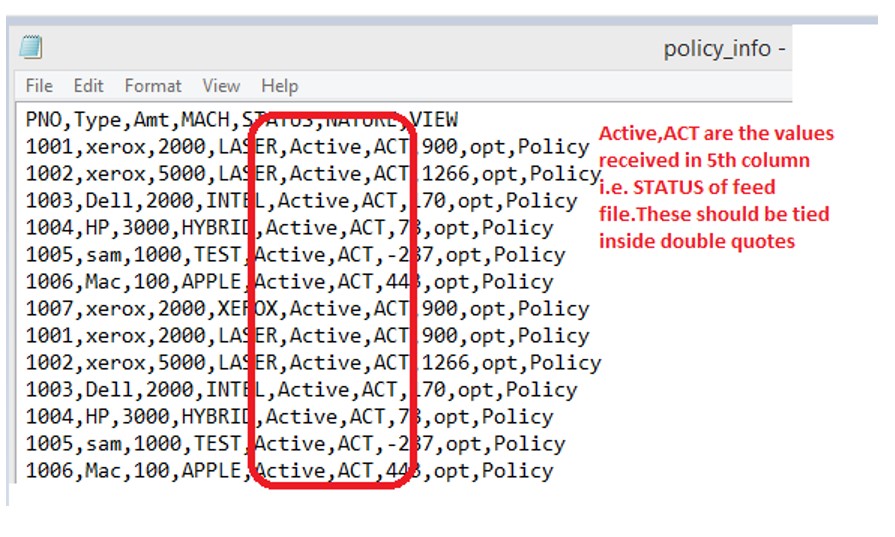
Python Code:
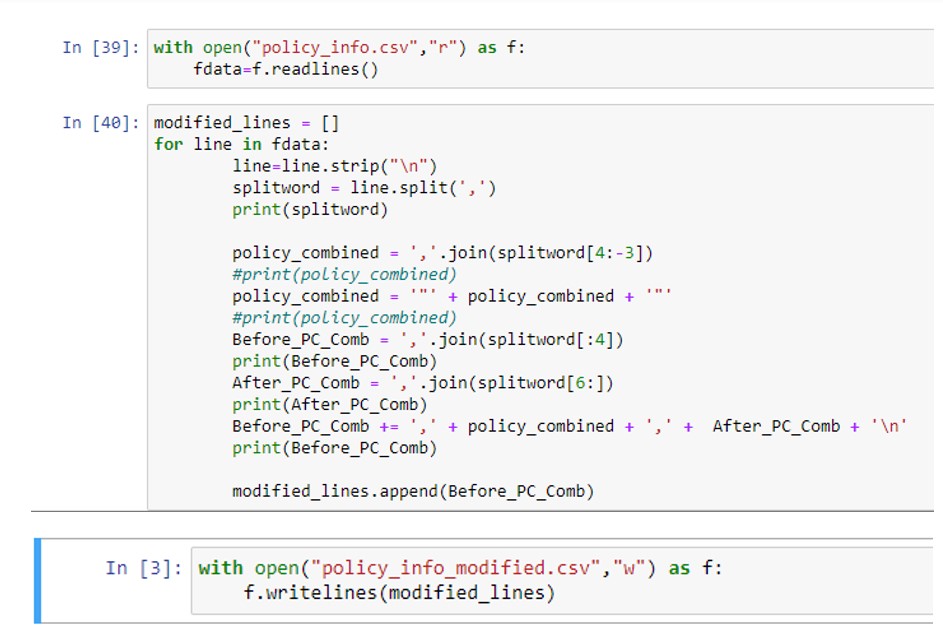
Output:
Hence this is one of the way to handle Extra comma in feed file.
Now we can create the File Format using field_optionally_enclosed_by property.
File Format:
create or replace file format demo_db.public.csv_format
type = csv
field_delimiter = ','
field_optionally_enclosed_by='"';