During the last post we discussed about an important function QUALIFY in conjunction with Window function, Today we will be talking about three other key functions i.e. SPLIT, SPLIT_PART,LATERAL FLATTEN which are being used in Snowflake.
SPLIT:
Splitting string is something most of us have to do from time to time. Splits a given string with a given separator and returns the result in an array of strings. The result can be use with functions and constructs operating on semi-structured data, e.g. FLATTEN, ARRAY_SIZE.
Syntax: SPLIT(<string>, <separator>)
SPLIT_PART:
Splits a given string at a specified character and returns the requested part. If any parameter is NULL, NULL returns.
Syntax: SPLIT_PART(<string>, <delimiter>, <partNumber>)
Arguments:
string : Text to be split into parts.
delimiter: Text representing the delimiter to split by.
partNumber: Requested part of the split (1-based).
FLATTEN:
Flattens (explodes) compound values into multiple rows. FLATTEN is a table function that takes a VARIANT, OBJECT, or ARRAY column and produces a lateral view
Using LATERAL FLATTEN removes the need for you to explicitly reference array locations. Each member of the array becomes its own row.
Syntax: from table, lateral flatten(input => table.variants)
Use Case:
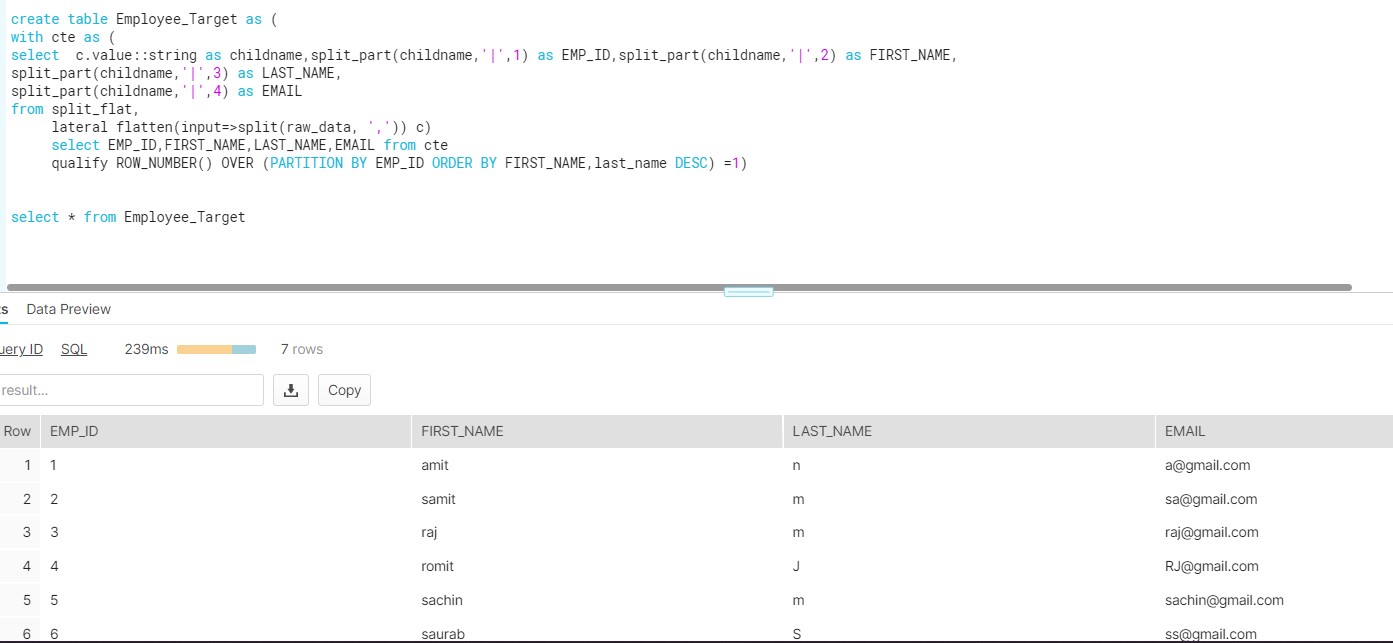
Lets consider one real time scenario where we have used the combination of all above three functions i.e. (SPLIT,SPLIT_PART,LATERAL_FLATTEN) along with QUALIFY to implement the requirement. Business has provided the source file in below format and want to ingest this file into Snowflake and data should be decompose into ROWS and COLUMNS.

Requirement:
- In above screenshot, Comma (,) is use to distinguish between the records which needs to be store as ROWS.
- while Pipe (|) is use to distinguish among the columns. So ideally store in 4 separate columns of table.
- No Duplicate records should be present in target table, Here Emp id 1 and 3 are duplicate entries , hence should be stored a single record.
We need to parse the data using SPLIT and FLATTEN and once the data has been consumed into staging table , the data looks like below:
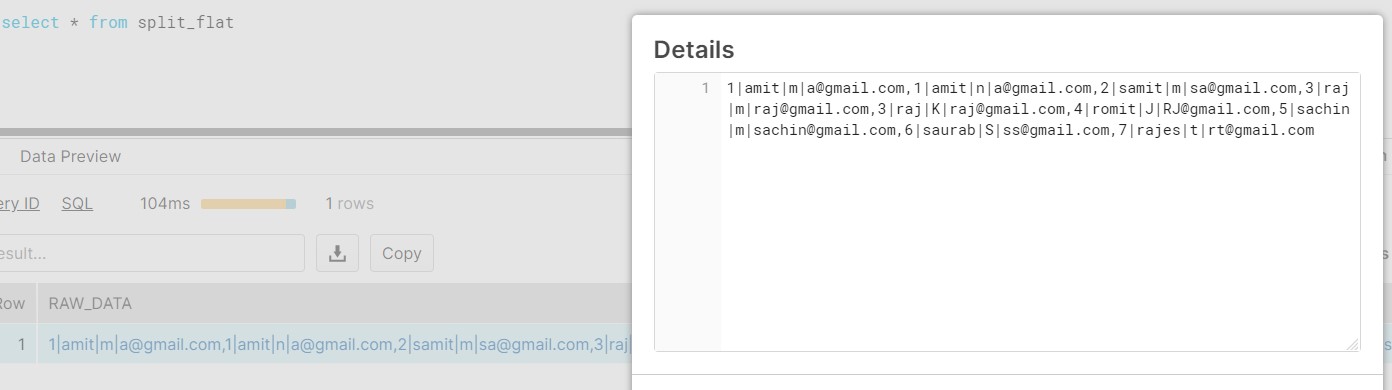
Now devise a query to extract the data into ROWS and COLUMNS from the staging table.
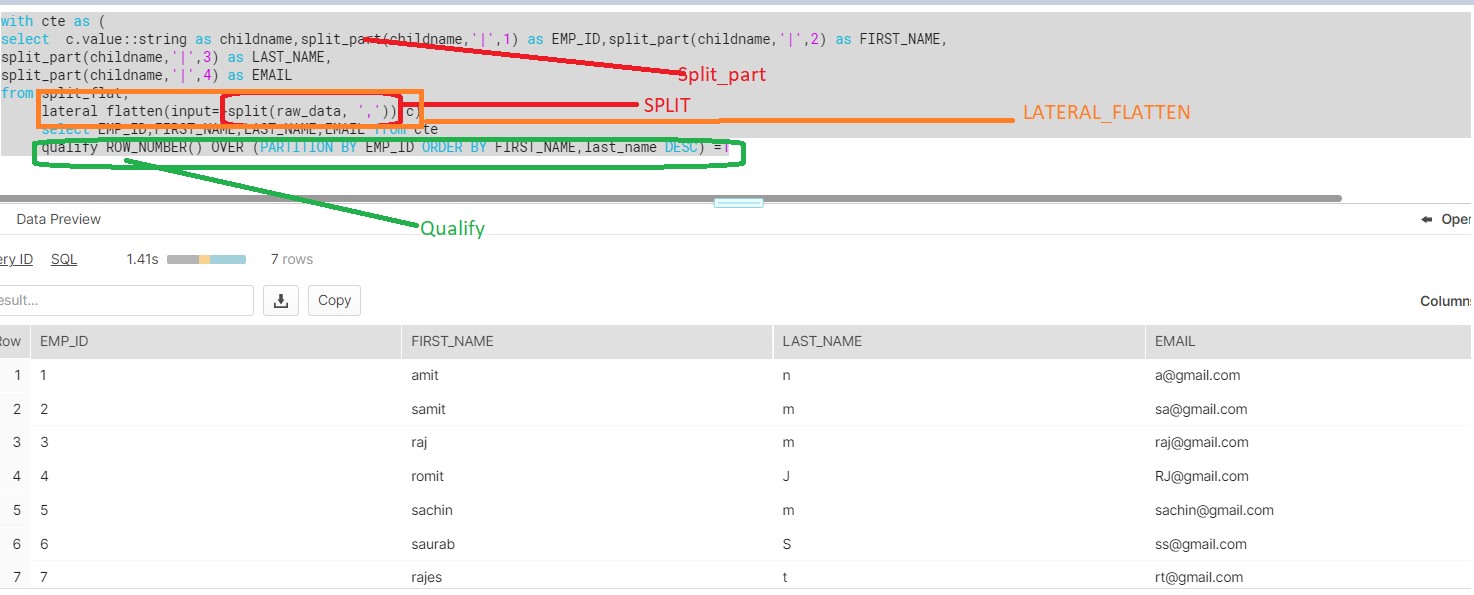
Finally create the target table where no duplicate records would be there.