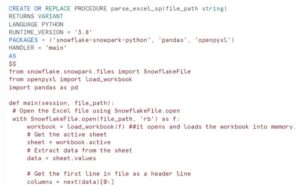
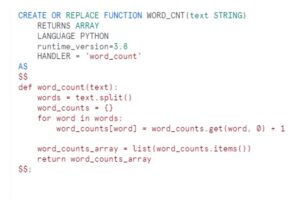
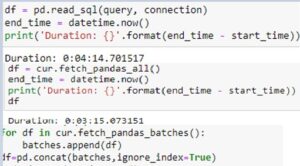
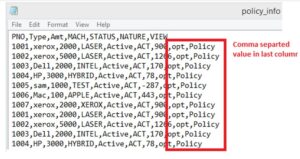
Today one of my colleague got the requirement where they received customer demographic file in csv format . There was one Address column field in the file where getting Some extra commas like Indirapuram,Noida,UP. So while loading the data into the table we are getting error because of Extra commas in data.
“Number of columns in file (6) does not match that of the corresponding table (4), use file format option error_on_column_count_mismatch=false to ignore this error”
This lead to the failure of our data load as complete file left unprocessed because of the data (extra commas in data) issue in Address.
To resolve the issue we can enclose the Address column into Double Quotes in the file itself. However in addition to it will use field_optionally_enclosed_by='”‘ in the creation of the FILE FORMAT.
But we have one glitch with this approach that, it is ideal to modify the Address (enclosing into Double Quotes) for countable records but what if we are getting a huge file then manual intervention is not feasible at any point. So to avoid the manual intervention we have used Python program which will enclosed the double quotes programmatically and generate the modified file in quick succession of time without any human error.
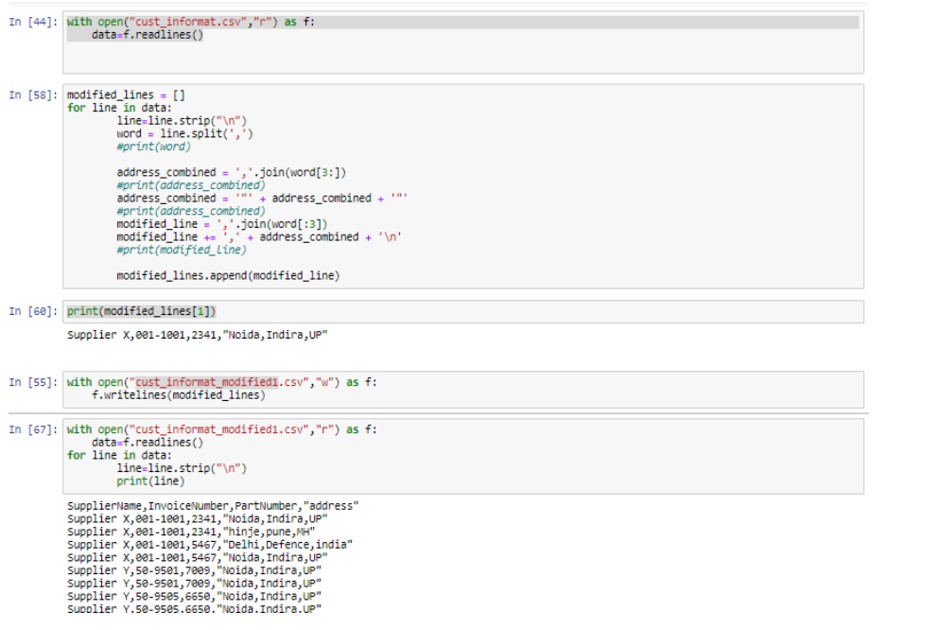
Above code will create file named cust_informat_modified1.csv which contains Address field enclosed in double quotes.
Now come to the Snowflake Worksheet and create the file format in below way:
File Format:
create or replace file format demo_db.public.csv_format
type = csv
field_delimiter = ','
skip_header = 1
field_optionally_enclosed_by='"';
Stage:
create or replace stage demo_db.public.ext_csv_stage
URL = 's3://collectionorgdelta/'
STORAGE_INTEGRATION = s3_int
file_format = demo_db.public.csv_format
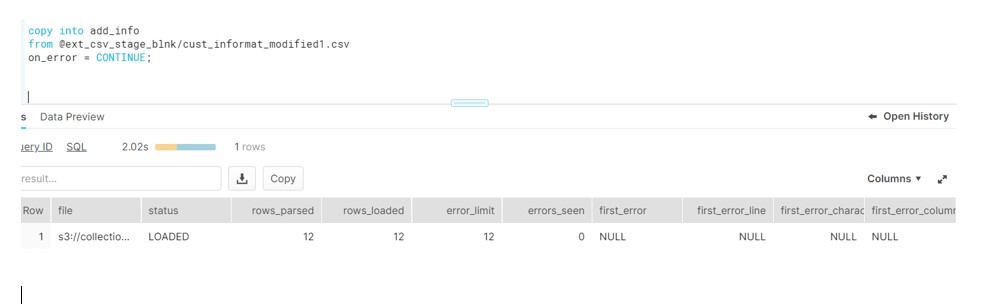
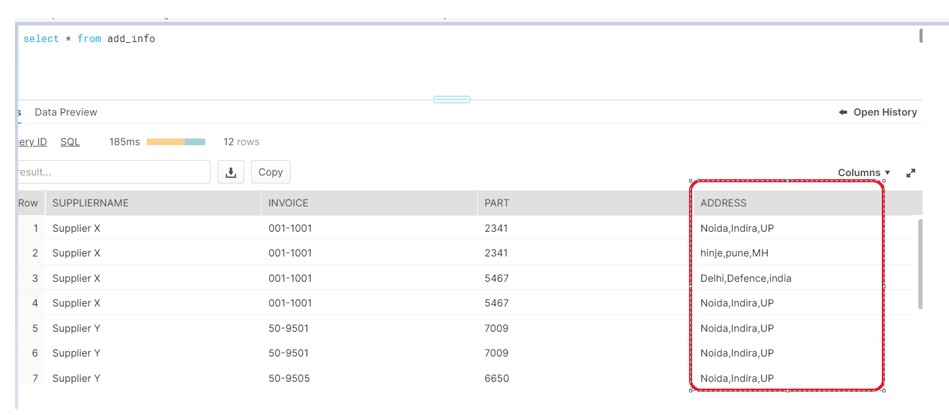
Now we can see the file gets loaded successfully into the table.