Out of the curiosity I tried to upload a file says 3 GB to Snowflake Internal Named Stage via Snowsql PUT command and then I realized according to the File sizing Guidelines by snowflake ,Loading very large files is not recommended. Split larger files into a greater number of smaller files to distribute the load among the servers in an active warehouse.
Splitting the file on Linux platform is quite straight forward and you can use out of the box split command in UNIX/LINUX Os. But on the windows platform either we need to write a python program to split the files based on the number of lines or use external tools to split the file. I was looking for an out-of-box feature by snowflake which we can leverage directly without writing any code and PUT command using Snowsql does the same with optional parameter [PARALLEL] .
Using parallel= will automatically split the files into smaller chunks and upload them in parallel – you don’t have to split the source file yourself.
Increasing the number of threads can improve performance when uploading large files.
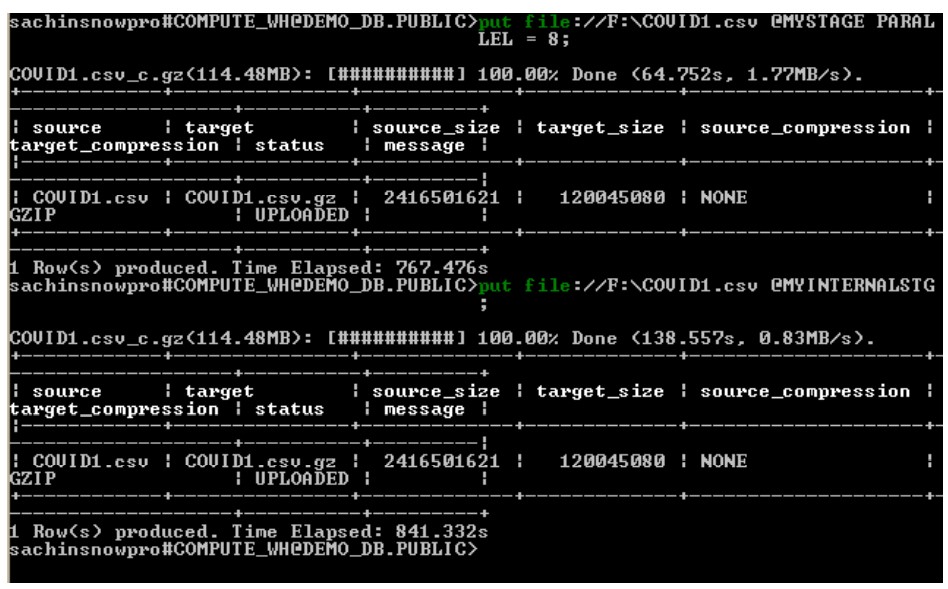
I tried to upload the 1 GB and 3GB file (because of storage constraint in my local PC) with two approaches.
PARALLEL and w/o PARALLEL:
put file://F:\COVID1.csv @MYSTAGE PARALLEL = 8
put file://F:\COVID1.csv @MYINTERNALSTGI see the difference in Time elapsed for both process and PARALLEL process got finished earlier as compared to the other process. Though the difference in timings not much but yes it is obvious we are working on smaller file size, In real time if you are trying to upload around 100- 500 GB file then this difference really matters.
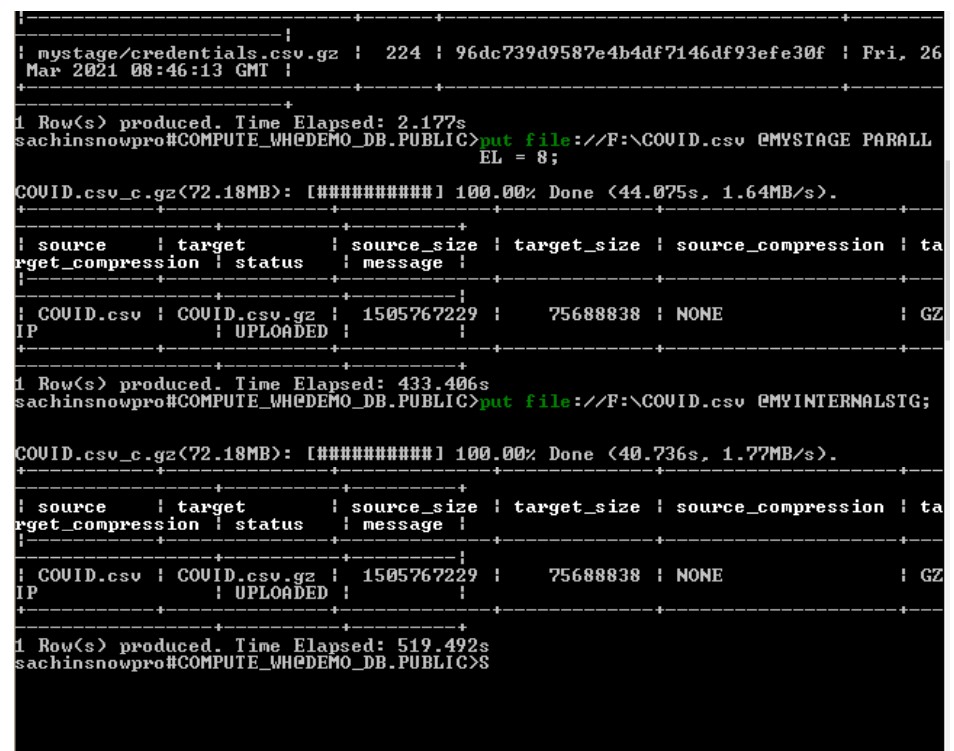
When trying to copy the 1GB file ,we see difference in Time Elapsed in both process.