The Cloning Snapshot represents the state of the source data at the specified time/point in the past.
Database ,Table, Schema cloning means snapshot of the data in each table is taken and made available to clone.
This is the fantastic feature of Snowflake. It provides the capability to duplicate an object. Duplicity does not implies physical copy as well as the add additional storage costs.
This lead to the greater freedom by keeping costs as low without limiting potential.
Scenario: Application require to be tested in QA env based on the prodcution data.
As a first step, create a Clone of the production data to the stage environment with just a simple command like below.
CREATE OR REPLACE TABLE <STAGE_SCHEMA>.TABLE_A_CLONE CLONE <PROD_SCHEMA>.TABLE_A ;
TABLE_A_CLONE created in the QA environment and the data available in the production table named TABLE_A.
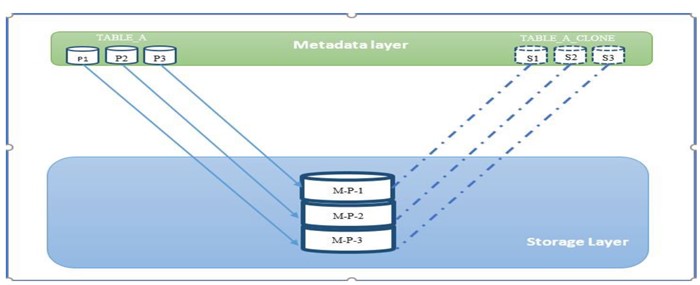
TABLE_A_CLONE is fully independent and will support all kinds of DML, DDL operations.
During integration testing activities, ETL jobs executed in stage environment, And inevitably modified some part of data from TABLE_A_CLONE.
All this modified data belongs to Micro Partition -3. How does Snowflake manages the change because same micro partition is shared among QA and production.
Well, now Snowflake copies that modified micro-partition alone and creates a new micro-partition and assigns this one to stage environment .
Note:A cloned object does not retain any granted privileges on the source object itself (i.e. clones do not automatically have the same privileges as their sources)
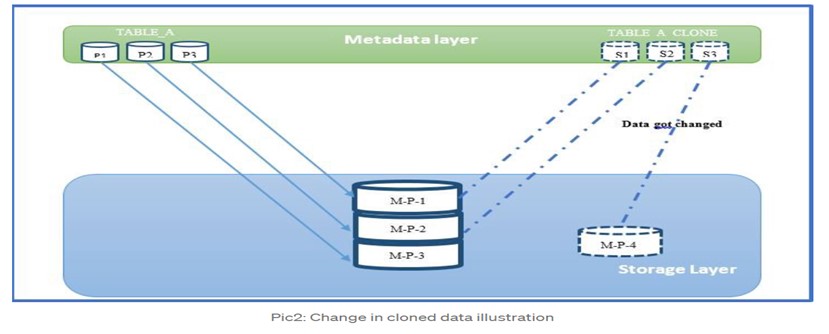
Therefore , Additional storage costs are levied only for the modified data but not for the complete clone.







