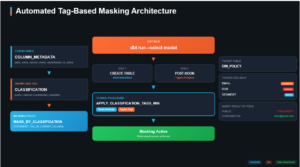
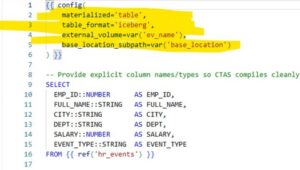
Snowflake and DBT (Data Build Tool) are two of the most powerful players in the modern data stack. Traditionally, DBT is known for transformations and Snowflake for its cloud-native warehousing. When combined, DBT handles your transformations and Snowflake provides the storage and compute power. This combination streamlines ETL processes, increases flexibility, and reduces manual coding.
In this blog, I walk you through a use case where DBT orchestrates an automated S3-to-Snowflake ingestion flow using Snowflake capabilities like file handling, schema inference, and data loading. All of this, defined inside DBT using just SQL and macros, without any Airflow, Python scripts, or manual schema management.
Goal: Ingest customer invoice data from an S3 bucket into Snowflake, create the target table dynamically based on the file’s structure, and load the data — all automated via DBT.
But Isn’t DBT Just for Transformations?
But Isn’t DBT Just for Transformations?
Yes — DBT is primarily known as a transformation tool, where you take raw data already inside your warehouse and clean, enrich, or model it using SQL.
But in platforms like Snowflake, where you can already:
-
Read files from S3
-
Dynamically infer schemas
-
Load data with
COPY INTO
, you don’t need a heavy ETL tool or Python scripts to ingest data.
So instead of switching between tools, we’re saying:
Why not use DBT to orchestrate Snowflake-native features — just like we use it to orchestrate SQL transformations?
- DBT is not doing the ingestion itself — it’s telling Snowflake what to do, using SQL.
- It brings structure, version control, and documentation to the entire data pipeline, not just the modeling part.
Technical Breakdown of the Solution
Technical Breakdown of the Solution
Let’s break down the solution into two pieces:
1. Macro (reusable logic)
2. DBT model (declarative workflow)
DBT Macro: create_snowflake_stage
We defined a Jinja macro to create an external stage pointing to the S3 bucket.

DBT Model: Ingest & Load the Data.
Our DBT model (load_data_from_s3.sql) calls this macro and then executes three main steps:
Before calling the macro or running SQL commands, we define a set of Jinja variables in the DBT model.
{% set db = 'DATA_LOAD_DBT' %}
{% set schema = 'public' %}
{% set stage_name = 'DBT_STAGE' %}
{% set table_name = 'CUST_INVOICE_TABLE' %}
{% set stage_type = 'external' %}
{% set location = 's3://snowflakeeventtable/cust_table' %}
{% set file_format_name = 'DATA_LOAD_DBT.public.my_csv_format' %}
Steps:
a) Create the Stage
{{ create_snowflake_stage(
db='DATA_LOAD_DBT',
schema='public',
name='DBT_STAGE',
stage_type='external',
location='s3://snowflakeeventtable/cust_table',
file_format='DATA_LOAD_DBT.public.my_csv_format',
storage_integration='s3_int'
) }}
b) Create Table using INFER_SCHEMA
We use Snowflake’s INFER_SCHEMA() to dynamically build the table based on the CSV file’s header.
{% set create_table_sql %}
CREATE OR REPLACE TABLE DATA_LOAD_DBT.public.CUST_INVOICE_TABLE
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION => '@DATA_LOAD_DBT.public.DBT_STAGE',
FILE_FORMAT => 'DATA_LOAD_DBT.public.my_csv_format'
)
)
)
{% endset %}
{% do run_query(create_table_sql) %}{% set copy_sql %}
COPY INTO DATA_LOAD_DBT.public.CUST_INVOICE_TABLE
FROM @DATA_LOAD_DBT.public.DBT_STAGE
FILE_FORMAT = (FORMAT_NAME = 'DATA_LOAD_DBT.public.my_csv_format')
PATTERN = '.*[.]csv'
ON_ERROR = 'CONTINUE'
{% endset %}
{% do run_query(copy_sql) %}SELECT COUNT(*) AS rows_loaded FROM DATA_LOAD_DBT.public.CUST_INVOICE_TABLE;

Conclusion:
This use case demonstrates that Data Build Tool and Snowflake aren’t just compatible — they’re complementary.
-
DBT brings structure, repeatability, and governance
-
Snowflake brings powerful ingestion and data management primitives