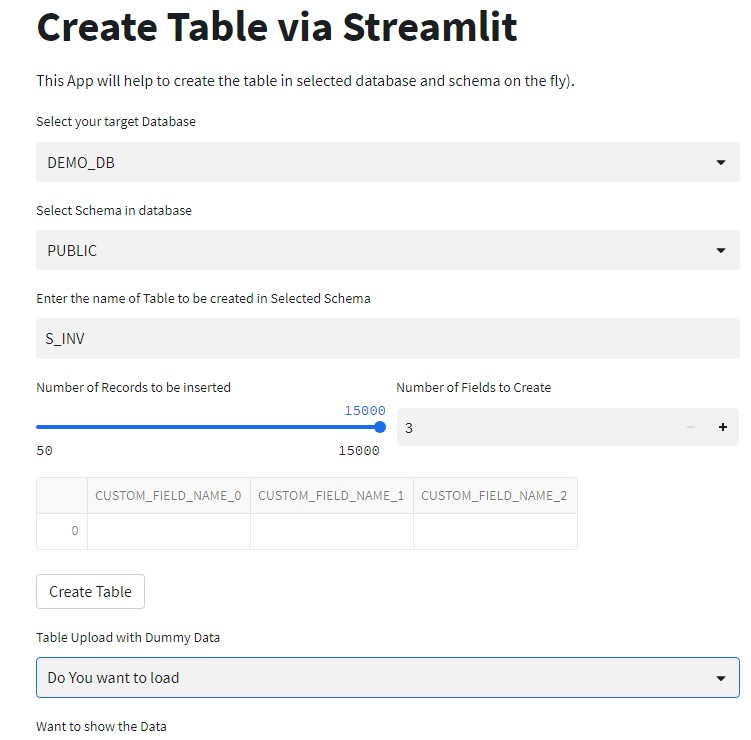
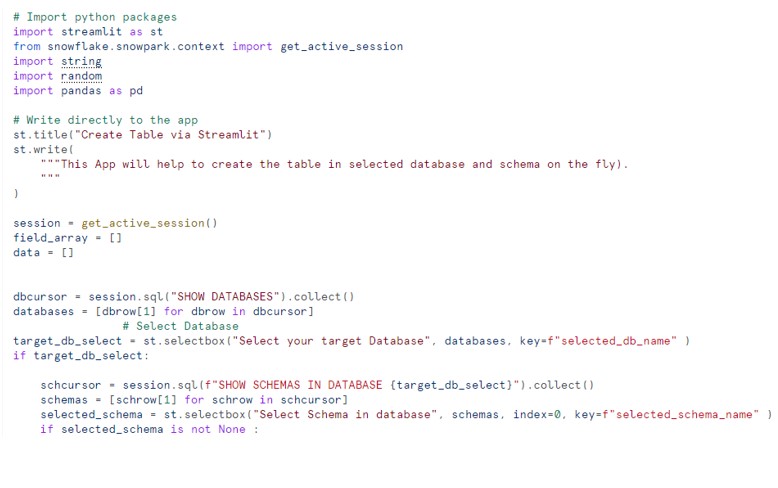
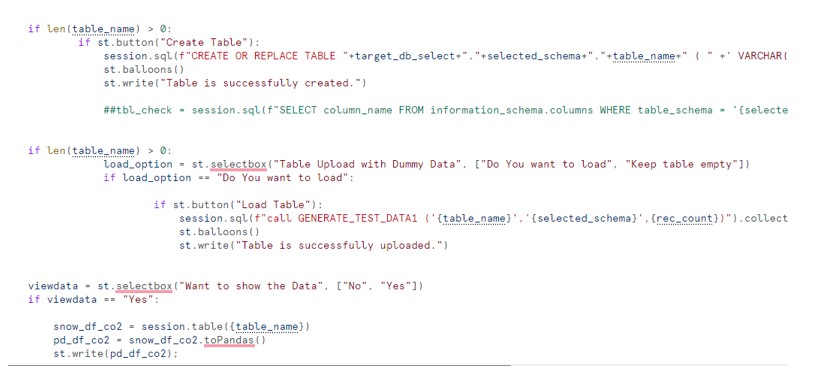
Please excuse me again for one more post related to the Streamlit. In this ongoing exploration of Streamlit, today’s focus is on dynamically creating a table and populating it with a user-defined number of records. Users have the flexibility to choose the record count using a slider, with a maximum limit of 15,000 records per table. Additionally, users can specify the desired number of columns for the table. We’ll also delve into calling a JavaScript stored procedure with arguments in the Streamlit app. Finally, we’ll explore how to verify the count or number of records in the newly created table.
Kindly observe that the data currently populated in the table is of string type. For simplicity, the same random value is being populated in all columns. There is no specific use case identified at the moment, and it remains uncertain if it can be effectively utilized. Nonetheless, I actively engaged in experimenting and gaining practical experience with it. Also, it helped me to learn the Snowpark concepts as well.
Please know that I understand this is a basic example, and I’m open to suggestions for improvement.
Credit goes to various open blogs authored by experts in Streamlit. I consulted multiple sources, and as such, I’m unable to specify names.












Hi Sachin , I really like your posts and too much to learn from them .. Thank you so much first of all for all your hardwork and knowledge sharing ..
Does this streamlit app loads the data from excel or any files or it just create the table ?
I have a req where i need to built streamlit app to load the excel,parquet file from streamlit app and able to load data back to table using this .. Just wondering if you have demo anything like this recently ?
Hi Nakul, The code mentioned there creates the table at run time based on the number of cols select from UI. Then i have one stored procedure which takes the table name,cols,and rec count as an input and we call it using streamlit it populates the data into table. I have below code in my repository from someone. Please see it it can be any help.
import streamlit as st
import io
import pandas as pd
import snowflake.connector as sc
@st.experimental_singleton
def sf_con():
return sc.connect(
user=st.secrets[“sf_usr”],
account=st.secrets[“sf_account”],
password =st.secrets[“sf_pwd”],
database=st.secrets[“sf_db”],
warehouse=st.secrets[“sf_wh”],
schema =st.secrets[“sf_schema”],
autocommit=True)
conn = sf_con()
@st.experimental_memo()
def fetch_query_pd(query):
with conn.cursor() as cur:
cur.execute(query)
return cur.fetch_pandas_all()
data_pd=fetch_query_pd(‘select * from tpch_sf1.customer limit 1000’)
st.title (‘From Snowflake to Excel via Streamlit’)
st.dataframe (data_pd)
@st.experimental_memo()
def create_xlsx(data_pd):
buffer = io.BytesIO()
with pd.ExcelWriter(buffer) as writer:
data_pd.to_excel(writer)
return buffer
if st.download_button(
label=”Download”,
data=create_xlsx(data_pd) ,
file_name=’customer.xlsx’,
mime=”application/vnd.ms-excel”):
st.write(“thank you for downloading!”)