In this post, we will explore the automation of the COPY process for loading a Snowflake table from an S3 bucket. Imagine a scenario where data needs to be migrated from a traditional system to a Snowflake database. The source system contains numerous tables that must be replicated in Snowflake. The data has been exported to files in the S3 bucket, which can be in CSV or JSON format depending on the source system’s database.
Now, to load these files into the corresponding tables in Snowflake, the conventional COPY command is typically use. When dealing with a considerable number of files, such as 100+, the manual approach involves writing a COPY command for each file, resulting in a cumbersome task. However, the business requirement is to implement a dynamic COPY process. This dynamic process aims to generate the COPY command at runtime, incorporating both the Snowflake table and AWS S3 file details. Instead of manually crafting and repeating the COPY command for each file, this process dynamically constructs and executes them sequentially.
Currently, the S3 bucket contains files in both CSV and JSON formats.
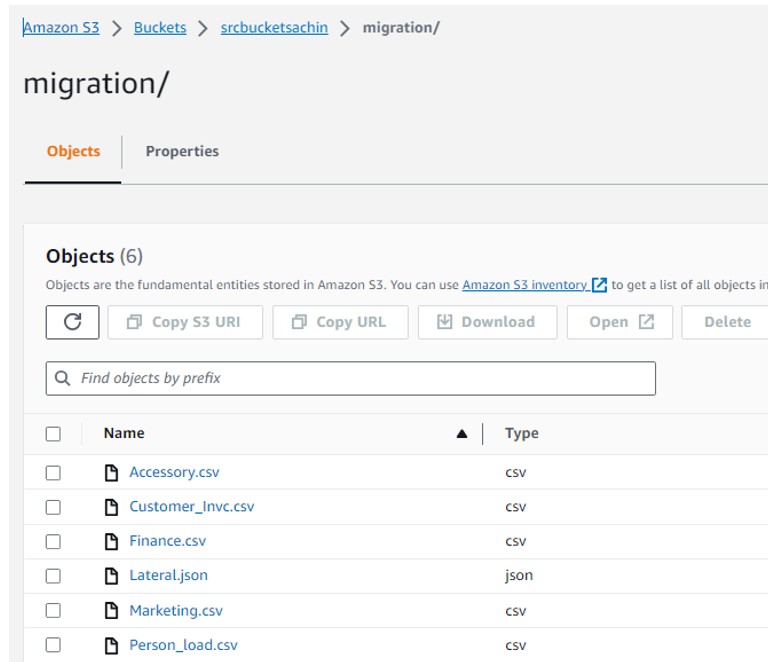
Note: In this context, file sizes are not taken into consideration, and they are organized within a single parent folder named “Migration.” However, if there are multiple files for the same table, a folder can be create using the table name, and all corresponding files will place inside it.
Our objective now is to load all these files into Snowflake while dynamically constructing the COPY command at runtime. The goal is to avoid hardcoding table and file names within the COPY command.
Approach:
Approach:
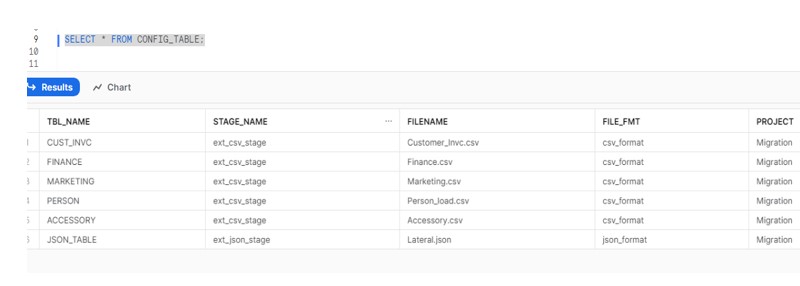
To achieve this, we have initiated the creation of a configuration table within Snowflake that contains details about tables and files.
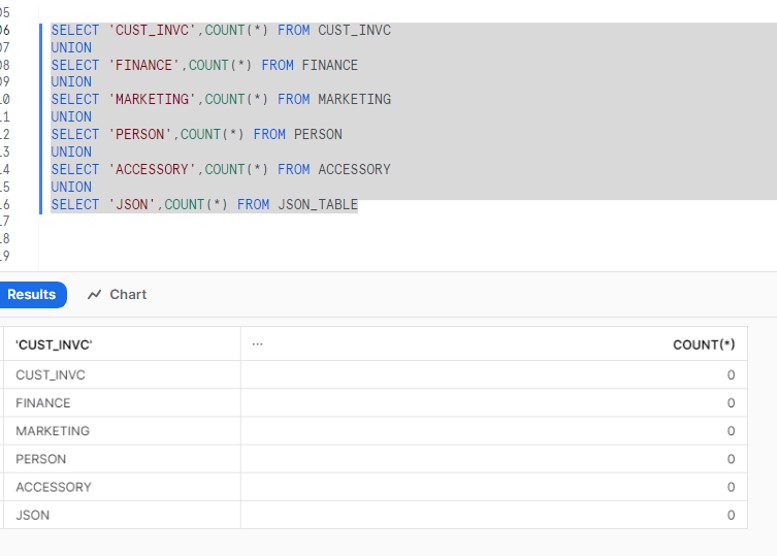
Verify whether respective table holds any data or not in snowflake.
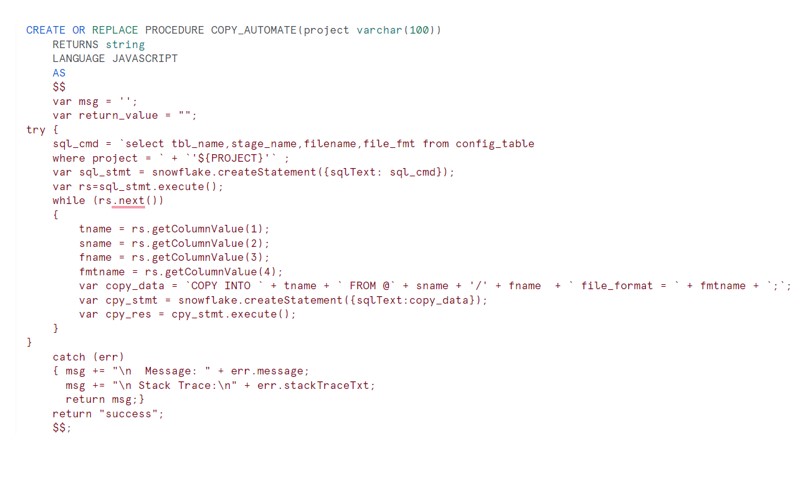
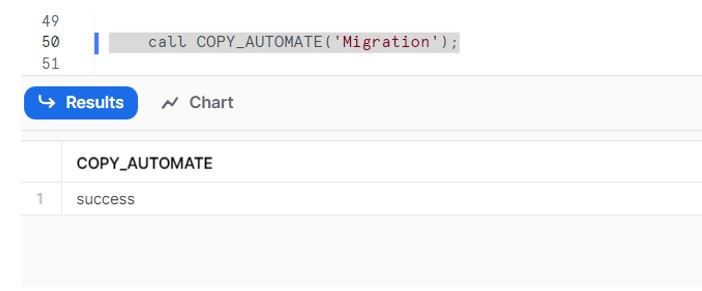
Now develop a Stored procedure which will read above config table and generate the COPY command. Once the COPY command is readily available , execute and load the data into Snowflake.
If you see the output of copy_data variable it will generate like below :
COPY INTO CUST_INVC FROM @ext_csv_stage/Customer_Invc.csv file_format = csv_format;
Now execute the procedure and observe the output in tables.
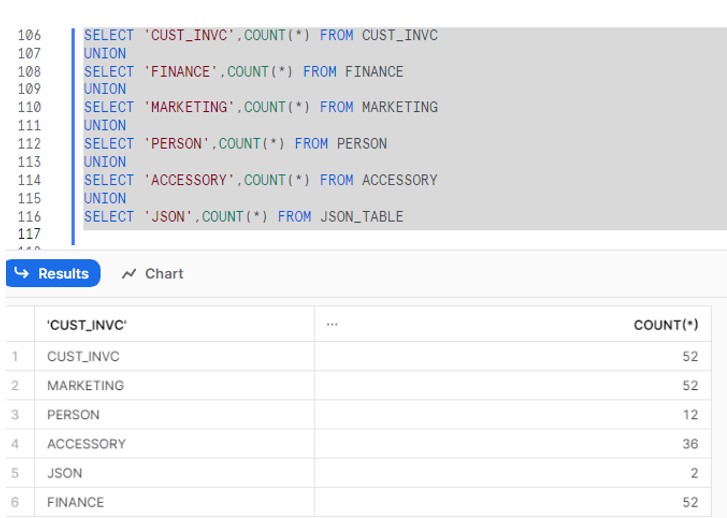
After the Proc execution data gets load into other respective tables:
So in future if any other entity comes to the S3 bucket, we need to add an entry to the Config table and rest the procedure will do it for you.