
There are many incredible features built in to Snowflake, but the most remarkable Snowflake Uniqueness is the ability to spin up an unlimited number of virtual warehouses (each effectively an independent MPP cluster). Therefore, Each warehouse can resize within milliseconds from a single node extra-small cluster to a massive 128-node monster.
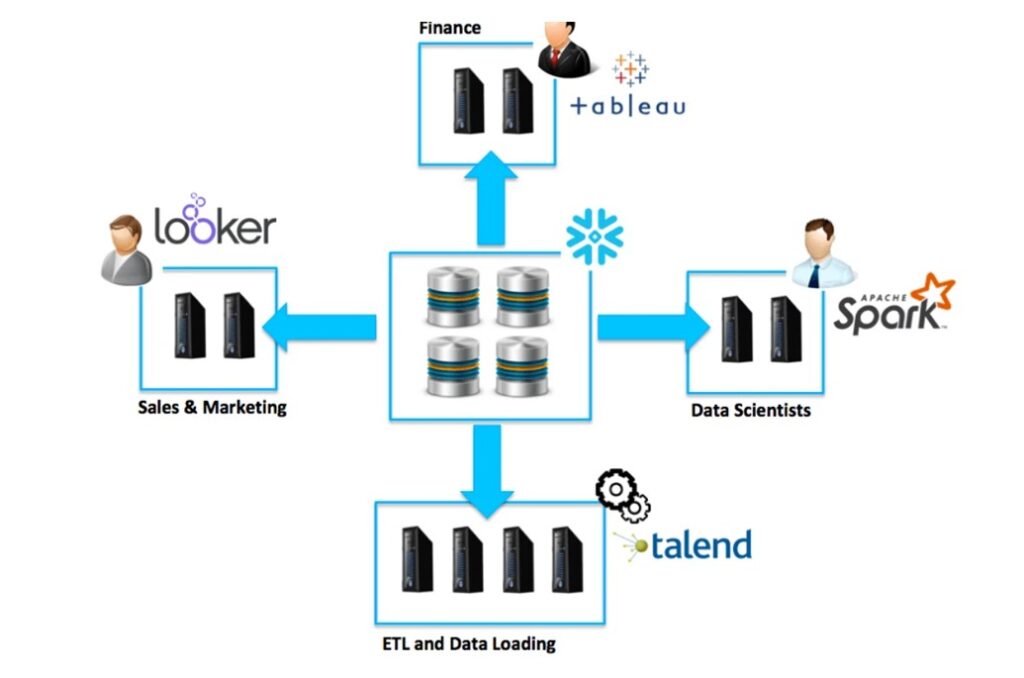
Snowflake Uniqueness features:
- No Risk of Contention: Users focus on analyzing data rather than spending time managing and tuning.
- Scaling compute: Autoscaling is a feature that enables within any Snowflake multi-cluster data warehouse. Snowflake multi-cluster feature automatically scales out and then back in during the day.
- Pay as you go: Beauty of Snowflake ,the user charges for the time the clusters are actually running.
- Native Support for Semi-Structured Data :
Traditional Databases Overview:
Traditional database architectures design to store and process data in strictly relational rows and columns. But a significant share of data today is machine-generated and deliver in semi structured data formats such as JSON, Avro, and XML.
Using semi-structured data in a traditional relational database requires compromising flexibility or performance. One approach is to transform that data into a relational format by extracting fields. This approach effectively puts the constraints of a fixed schema on that semi-structured data, sacrificing information and flexibility. Fields not specify for extraction get loose, including new fields that appear in the data.
The alternative to this approach, which some databases implements, is a special datatype for storing semi-structured data as a complex object or simply as a string type. Although this approach preserves the information and flexibility in the semistructured data, it sacrifices performance. For example, accessing a single element in an object commonly requires a full scan of the entire object in order to locate the element.
Semi structured Data
Snowflake started by making it possible to flexibly store semi-structured records inside a relational table in native form. This accomplishes through a custom datatype (Snowflake’s VARIANT datatype) that allows schema-less storage of hierarchical data, including JSON, Avro, XML and Parquet. This makes it possible to load semi-structured data directly into Snowflake without pre-processing, losing information, or defining a schema.
You simply create a table containing a column with Snowflake’s VARIANT datatype and then load files containing semi-structured data into that table.
Seamless sharing of data :
Instead of needing to manually create copies of data and sending them over FTP, EDI, or cloud file services. Snowflake Data Sharing allows any Snowflake customer to share access to their data with any other Snowflake customer.
The schema and database structure can import automatically by the consumer so there’s very little manual effort involved in using the shared data. What’s more, when the data updates in the provider account, it’s automatically and immediately visible in the consumer account.












