Data warehouses store large volumes of data, sometimes they keep historical data for many years. At the same time data analysts rarely need to query all data, in most cases their interest in data for recent days, weeks or just short periods in the past. Data warehouses rely on static partitioning of large tables which is available using specialized DDL and syntax; however, static partitioning has a number of well-known limitations, such as maintenance overhead and data skew and to overcome the limitations we have Micro partitions and Pruning in Snowflake.
Micro-Partition:
Micro-Partitions:
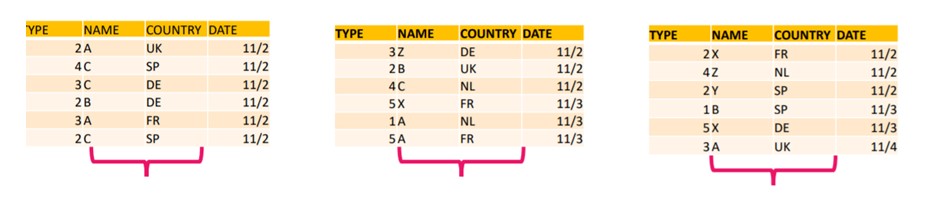
Although you do not explicitly specify partitions in Snowflake. All data are automatically load into partitions, called micro partitions in Snowflake.
Moreover, Each micro partitions contains between 50 MB and 500 MB of uncompressed data . Groups of rows in tables maps into individual micro-partitions, organize in a columnar fashion.
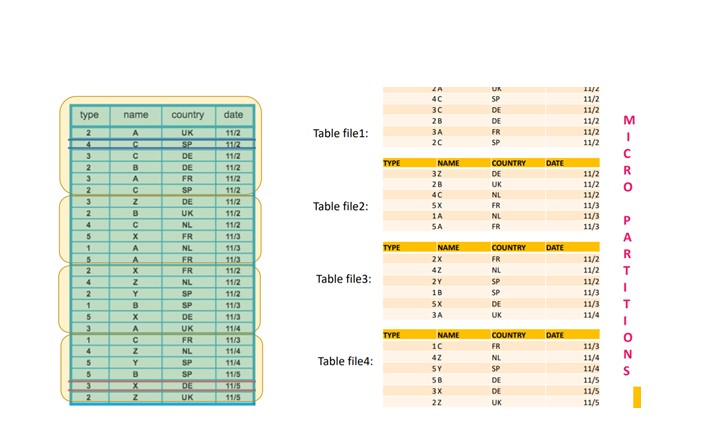
Reorganize the data in each partition to make it columnar i.e. Column values in partition are store together.
Compressing the each column, we are not compressing the entire partition but compressing the columns values in each partition
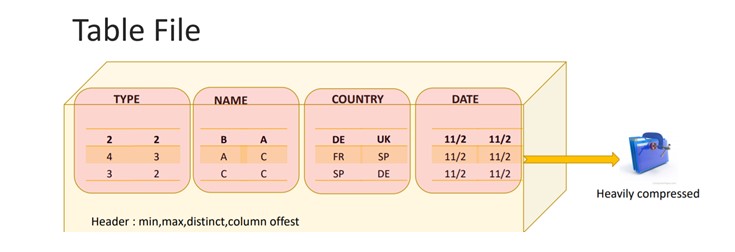
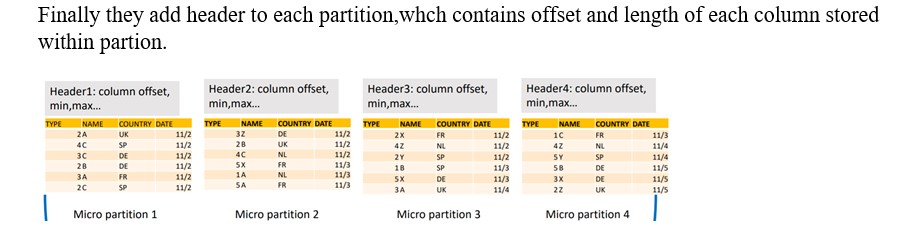
Finally these micro partitions store on S3 in the form of immutable files while other statistics and information about these stores at cloud service layer.
Note: While loading the data into table, Snowflake does not reorganize the partitions, once the data load completed snowflake reorganized the micro partitions.
How Query gets executed in snowflake:
- Query submits to the cloud service layer.
- Parsing i.e. Syntactical checking is done.
- Semantical Analysis : Verify the object name in metadata repository.
- Cloud service layer does Query optimization, create execution plans, and submits this plans to Virtual ware house nodes.
- Nodes will first download the table file header from all the table files.
- Based on the metadata information in the header file, Micro partitions are scanned and this allows the first level of partition pruning.
- Finally, In next step read the micro partition header and read the desired columns and this allows the second level of column pruning.
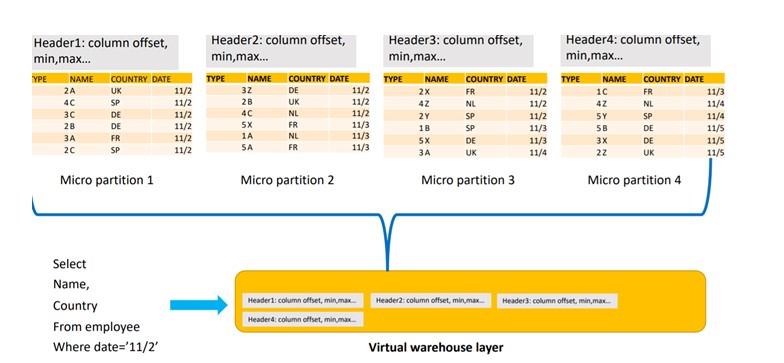
Execute the Query will eliminate the 4th Micro partition as the date mentioned in query does not lie in 4th partition and below result lead to the Column Pruning.